Train a tool-using Math Agent (ReAct + Python executor) to solve GSM8K-style math problems. Rewards come from a judge that checks final-answer correctness.
Overview
In Math Agent, each training sample is a math word problem (e.g., GSM8K). The agent learns to reason step by step (ReAct-style), call a Python tool when computation is needed, and produce a final answer that matches the reference.
This tutorial is organized into the following sections:
- Run this tutorial: Download the dataset and start training with the default YAML config.
- Understand & customize: Read the workflow and the judge/reward logic.
- Training Curve: Compare the training curlve.
Quick Start
Prepare Dataset
Download the openai/gsm8k dataset:
Start Training
# (optional) recommended cleanup before training
# ajet --kill="python|ray|vllm"
ajet --conf tutorial/example_math_agent/math_agent.yaml --backbone='verl'
Quick Debugging (Optional)
If you want to breakpoint-debug the workflow/judge locally:
# (optional) recommended cleanup before debug
# ajet --kill="python|ray"
clear && \
ajet --conf tutorial/example_math_agent/math_agent.yaml --backbone='debug' --with-logview
When --backbone=debug, Ray is disabled. You can use a VSCode launch config:
Understanding the Training Pipeline
Pipeline Abstraction
- Load one problem Load a math problem from the dataset via `task_reader`.
- Run the Workflow Build the prompt, let the ReActAgent call Python tools, and extract the final answer.
- Return result as `WorkflowOutput` Return `WorkflowOutput(reward=None, metadata={"final_answer": final_answer})`. (reward=None because we want to compute reward outside the workflow)
- Run the judge Compare `final_answer` with reference, compute `raw_reward` and `is_success`.
YAML Configuration
Most wiring happens in tutorial/example_math_agent/math_agent.yaml:
ajet:
task_reader:
type: huggingface_dat_repo # also supports: dataset_file / env_service
rollout:
user_workflow: tutorial.example_math_agent.math_agent->ExampleMathLearn
task_judge:
judge_protocol: tutorial.example_math_agent.math_answer_as_judge->MathAnswerAndLlmAsJudge
model:
path: YOUR_MODEL_PATH
ajet:
task_reader:
type: huggingface_dat_repo # also supports: dataset_file / env_service
rollout:
user_workflow: tutorial.example_math_agent.math_agent_oai_sdk->ExampleMathLearn
task_judge:
judge_protocol: tutorial.example_math_agent.math_answer_as_judge->MathAnswerAndLlmAsJudge
model:
path: YOUR_MODEL_PATH
ajet:
task_reader:
type: huggingface_dat_repo # also supports: dataset_file / env_service
rollout:
user_workflow: tutorial.example_math_agent.math_agent_raw_http->ExampleMathLearn
task_judge:
judge_protocol: tutorial.example_math_agent.math_answer_as_judge->MathAnswerAndLlmAsJudge
model:
path: YOUR_MODEL_PATH
ajet:
task_reader:
type: huggingface_dat_repo # also supports: dataset_file / env_service
rollout:
user_workflow: tutorial.example_math_agent.math_agent_langchain->ExampleMathLearn
task_judge:
judge_protocol: tutorial.example_math_agent.math_answer_as_judge->MathAnswerAndLlmAsJudge
model:
path: YOUR_MODEL_PATH
user_workflow assignment
- As you have noticed,
user_workflow: tutorial.example_math_agent.math_agent_langchain->ExampleMathLearnmeans, AgentJet will try to importExampleMathLearnfrom${WorkingDir}/tutorial/example_math_agent/math_agent_langchain.py. (Dot import) - If you prefer absolute path, or you workflow is not in python search path, you can also use the alternative way to import your workflow
user_workflow: /path/to/ajet/tutorial/example_math_agent/math_agent_langchain.py->ExampleMathLearn. (Path import) - Both dot import (dot-to-module) and path import (path-to-source-code) is good. But dot import is recommended as it is more pythonic.
| Field | Description |
|---|---|
task_reader |
Where tasks come from |
user_workflow |
Which workflow runs per sample |
judge_protocol |
Which judge computes rewards |
model.path |
Pretrained model to fine-tune |
Code Walkthrough
Workflow: tutorial/example_math_agent/math_agent.py
self.toolkit = Toolkit()
self.toolkit.register_tool_function(execute_python_code)
self.agent = ReActAgent(
name="math_react_agent",
sys_prompt=system_prompt,
model=model_tuner, # trainer-managed model wrapper
formatter=DashScopeChatFormatter(),
toolkit=self.toolkit,
memory=InMemoryMemory(),
)
msg = Msg("user", init_messages[0]["content"], role="user")
result = await self.agent.reply(msg)
final_answer = extract_final_answer(result)
# IMPORTANT: provide final answer to the judge via WorkflowOutput metadata
return WorkflowOutput(reward=None, metadata={"final_answer": final_answer})
client = tuner.as_raw_openai_sdk_client()
# call 1: get response with tool call
messages = [
{ "role": "system", "content": self.system_prompt },
{ "role": "user", "content": query }
]
reply_message: ChatCompletion = await client.chat.completions.create(messages=messages, tools=self.available_functions)
if (reply_message.choices[0].message.content):
messages.append({
"role": "assistant",
"content": reply_message.choices[0].message.content
})
# If the model called a tool
if (reply_message.choices[0].message) and (reply_message.choices[0].message.tool_calls):
tool_calls: list[ChatCompletionMessageToolCall] = reply_message.choices[0].message.tool_calls
for tool_call in tool_calls:
if tool_call.function.name == "execute_python_code":
arguments = json.loads(tool_call.function.arguments)
def sync_wrapper():
import subprocess
import sys
process = subprocess.run(
[sys.executable, "-c", arguments["code"]],
timeout=arguments.get("timeout", 300),
capture_output=True,
text=True
)
return process.stdout
result = await asyncio.to_thread(sync_wrapper)
tool_result_message = {
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": json.dumps({
"return_code": str(result),
})
}
messages.append(tool_result_message)
# Step 3: Make a follow-up API call with the tool result
final_response: ChatCompletion = await client.chat.completions.create(
messages=messages,
)
final_stage_response = final_response.choices[0].message.content
else:
final_stage_response = reply_message.choices[0].message.content
return WorkflowOutput(reward=None, metadata={"final_answer": final_stage_response})
url_and_apikey = tuner.as_oai_baseurl_apikey()
base_url = url_and_apikey.base_url
api_key = url_and_apikey.api_key
# take out query
query = workflow_task.task.main_query
messages = [
{
"role": "system",
"content": self.system_prompt
},
{
"role": "user",
"content": query
}
]
# use raw http requests (non-streaming) to get response
response = requests.post(
f"{base_url}/chat/completions",
json={
"model": "fill_whatever_model", # Of course, this `model` field will be ignored.
"messages": messages,
},
headers={
"Authorization": f"Bearer {api_key}"
}
)
final_answer = response.json()['choices'][0]['message']['content']
return WorkflowOutput(reward=None, metadata={"final_answer": final_answer})
# tuner to api key
url_and_apikey = tuner.as_oai_baseurl_apikey()
base_url = url_and_apikey.base_url
api_key = url_and_apikey.api_key
from langchain_openai import ChatOpenAI
llm=ChatOpenAI(
base_url=base_url,
api_key=lambda:api_key,
)
agent=create_agent(
model=llm,
system_prompt=self.system_prompt,
)
# take out query
query = workflow_task.task.main_query
response = agent.invoke({
"messages": [
{
"role": "user",
"content": query
}
],
})
final_answer = response['messages'][-1].content
return WorkflowOutput(reward=None, metadata={"final_answer": final_answer})
Important
- User should put all elements necessary for reward computation in
WorkflowOutput.metadata, so the judge can use them. - In this specific case,
final_answeris that key element.
Reward Computation
The judge receives:
| Object | Contains |
|---|---|
workflow_task |
Task info; reference answer from metadata |
workflow_output |
Workflow result; final answer from metadata["final_answer"] |
Extending the Judge
If you observe issues like "almost solved but messed up tool-call formatting", you can extend the judge to add:
- Format penalty (invalid
<tool_call>) - Behavior penalty (tool called but no
print) - Keep answer correctness as the primary signal
YAML Configuration
Most wiring happens in tutorial/example_math_agent/math_agent.yaml:
ajet:
task_reader:
type: huggingface_dat_repo # also supports: dataset_file / env_service
rollout:
user_workflow: tutorial.example_math_agent.math_agent->ExampleMathLearn
task_judge:
judge_protocol: tutorial.example_math_agent.math_answer_as_judge->MathAnswerAndLlmAsJudge
model:
path: YOUR_MODEL_PATH
| Field | Description |
|---|---|
task_reader |
Where tasks come from |
user_workflow |
Which workflow runs per sample |
judge_protocol |
Which judge computes rewards |
model.path |
Pretrained model to fine-tune |
Results
Training Curve
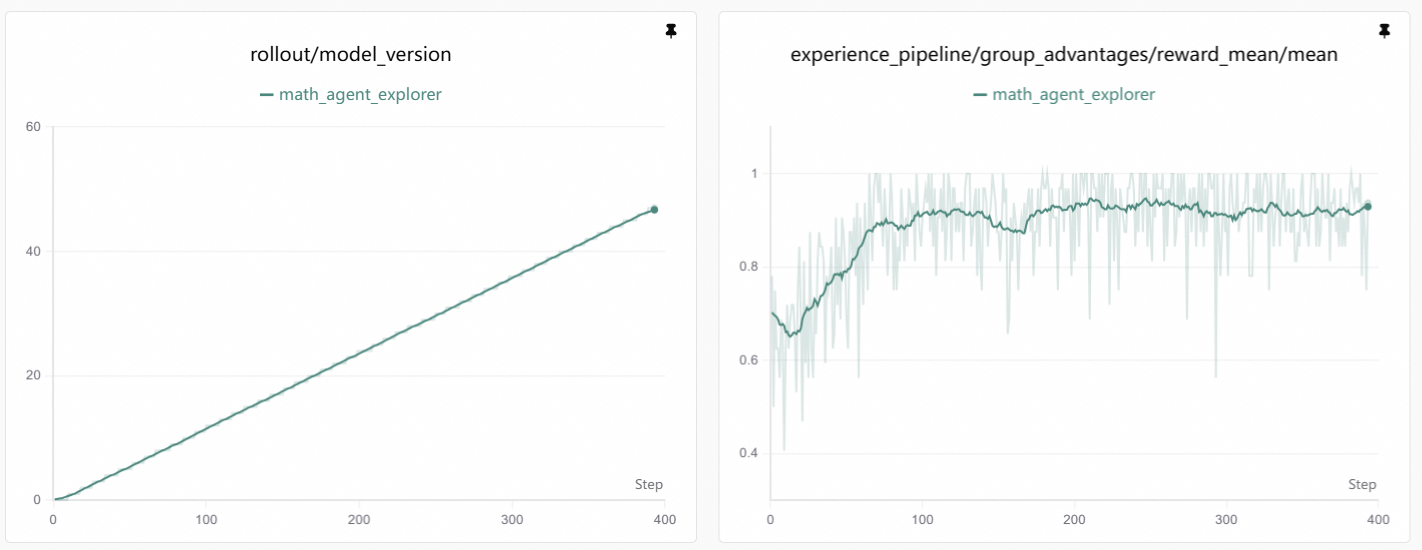
Visualization
Training curves are generated by SwanLab. See Visualization Tools for setup.
Interpretation: As training progresses, reward increases. This usually means the agent becomes more stable at:
- Using tools when needed: Correctly emitting
<tool_call>and callingexecute_python_code - Producing reliable answers: Using tool output to produce final answers aligned with reference
Case Study: Tool Discipline Improvement
Before training, the agent may solve many problems but often fails at tool-call discipline:
# bad case 1: forgot to print the result in python code
<tool_call>
{"name": "execute_python_code", "arguments": {"code": "... height_difference"}}
</tool_call>
# bad case 2: too impatient — outputs final answer without waiting for tool result
<tool_call> {"name": "execute_python_code", ...} </tool_call>
<tool_call> {"name": "generate_response", "arguments": {"response": "... \\boxed{48} ..."}} </tool_call>
These failures are not because the model "can't do math", but because it does not close the loop by incorporating the tool execution result.
After tuning, the agent follows a clean 3-stage pattern:
- Message 3 (assistant): Decomposes problem + emits
<tool_call>withprint(...) - Message 4 (tool_response): Tool returns execution results
- Message 5 (assistant): Reads
stdoutand produces final answer

Token-level Visualization
The colored blocks show token-level sequence visualization from Beast-Logger:
- Yellow tokens: Excluded from loss computation
- Blue tokens: Participate in loss computation (light to dark = high to low logprob)