The original document is Chinese Version
The Lobster Has Arrived
In late 2025, a "lobster" quietly crawled onto GitHub.
Without a launch event or any hype, an open-source project called OpenClaw went from a weekend hacker's toy to 100K Stars in three months. It can take over your email, calendar, and browser, help you book flights, write weekly reports, and automatically reply to messages—a powerful local AI assistant. The community gave it a nickname: the lobster. The red logo, menacing claws, and the way it aggressively gets things done for you—it definitely fits the description.
On Reddit, someone said "This is the first time I feel like AI is actually helping me get work done instead of just chatting with me," and the Hacker News threads are filled with deployment tutorials and automation scripts. In February 2026, OpenAI acquired it outright. An open-source lobster, brought into the mainstream.
However, taming a lobster isn't easy.
Some people woke up to find their hard drives wiped clean, others had their emails deleted by OpenClaw—even shouting "stop" didn't work, it didn't listen. China's National Computer Network Emergency Response Technical Center (CNCERT) issued a special risk warning about OpenClaw's secure application. These incidents point to the same root cause: large models in complex Agent systems still have serious flaws in instruction-following capability when dealing with long contexts. The lobster is strong, but it doesn't always obey.
The most fundamental solution to this problem is Agentic Reinforcement Learning—using evolutionary thinking to continuously "train" the lobster's behavioral boundaries. But unfortunately, traditional LLM reinforcement learning architectures tightly couple sampling and training. The training engine's narrow "deck" simply can't accommodate the lobster's massive body—behind it is a complex multi-agent environment consisting of browsers, terminals, file systems, and multi-turn conversations. Traditional frameworks have no way to handle this.
But don't worry—the tool for training lobsters has arrived.
AgentJet: Swarm Architecture
AgentJet, a next-generation multi-agent training framework developed jointly by Alibaba Tongyi Lab and the Chinese Academy of Sciences, adopts a revolutionary "swarm" architecture.
The core idea is simple: completely decouple "training" and "sampling."
In AgentJet's swarm, users can freely build a distributed training network consisting of two types of nodes based on their hardware:
- "Training" nodes run on GPU servers, responsible for model inference and gradient computation;
- "Sampling" nodes can run on any device connected to the swarm—including your laptop—responsible for driving agents like OpenClaw, continuously extracting the "data fuel" needed for training.
What does this mean?
You don't need to modify a single line of OpenClaw code, no need to settle for some trimmed-down derivative variant—you can fine-tune and customize a lobster that understands you better, right on your laptop.
Furthermore, AgentJet supports connecting multiple different LLM models simultaneously to the same multi-agent system's reinforcement learning task, achieving true non-shared parameter multi-agent reinforcement learning (MARL). Sampling nodes can be dynamically added, removed, or modified at any time, building a swarm training network that is unrestricted by environment, can fix bugs on the fly, and can recover from external environment crashes.
AgentJet is fully open-source, rich in examples, and ready to use out of the box. It comes with token-level tracking and debugging tools, along with version-by-version training performance tracking platforms. It also provides dedicated SKILLs for Vibe Coding developers, allowing Claude Code and other tools to one-click assist with agent orchestration and training debugging.
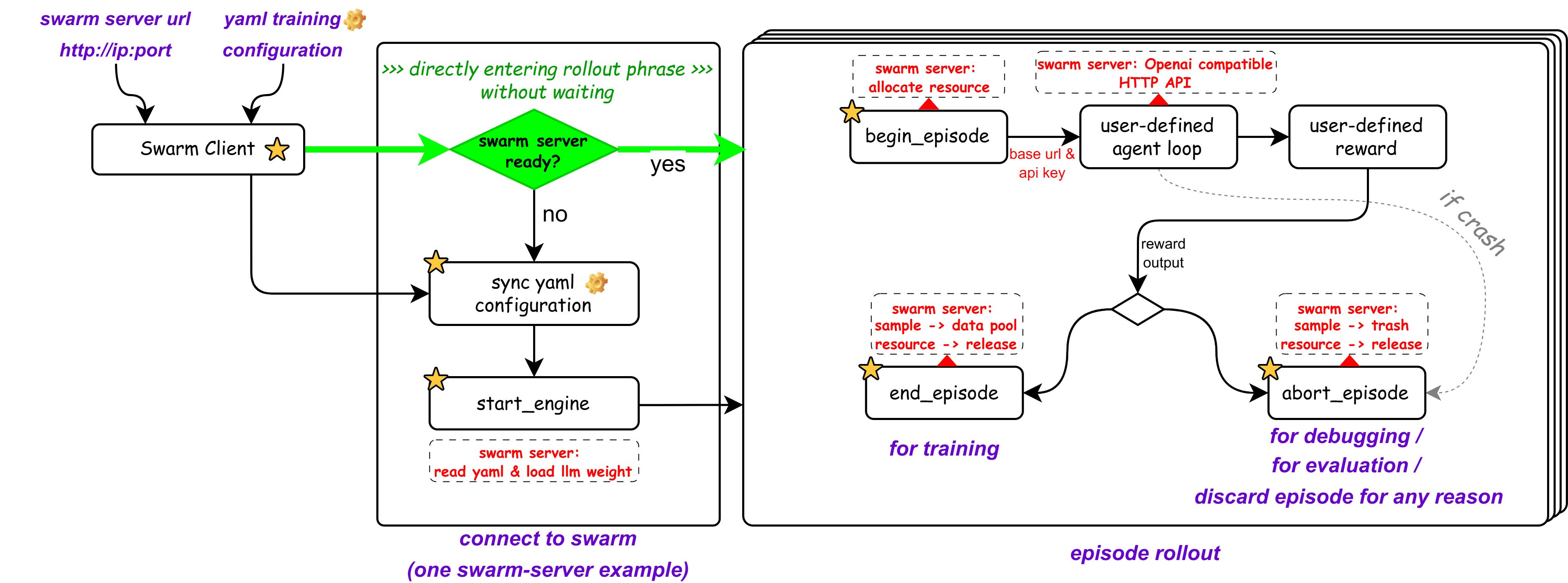
Three Steps to Train a Lobster
The entire process takes only three steps.
1. Wake Up the Swarm Server
No need to install dependencies—just one Docker command to start the training engine:
docker run --rm -it -v ./swarmlog:/workspace/log -v ./swarmexp:/workspace/saved_experiments \
-p 10086:10086 --gpus=all --shm-size=32GB ghcr.io/modelscope/agentjet:main bash -c "(ajet-swarm overwatch) & (NO_COLOR=1 LOGURU_COLORIZE=NO ajet-swarm start &>/workspace/log/swarm_server.log)"
2. Start the Swarm Client
On your laptop, start the OpenAI model interface mimicry and user reward function:
git clone https://github.com/modelscope/agentjet.git && cd agentjet
pip install -e .
cd ./agentjet/tutorial/opencode_build_openclaw_agent
python fake_vllm_endpoint.py # Reward is for demonstration purposes only
3. Release the Lobster, Start Training
Start OpenClaw, enter the configuration page, and point the model address to the local mimicry interface:
Settings > Configuration > Models > Model Providers > vllm:http://localhost:8090/v1
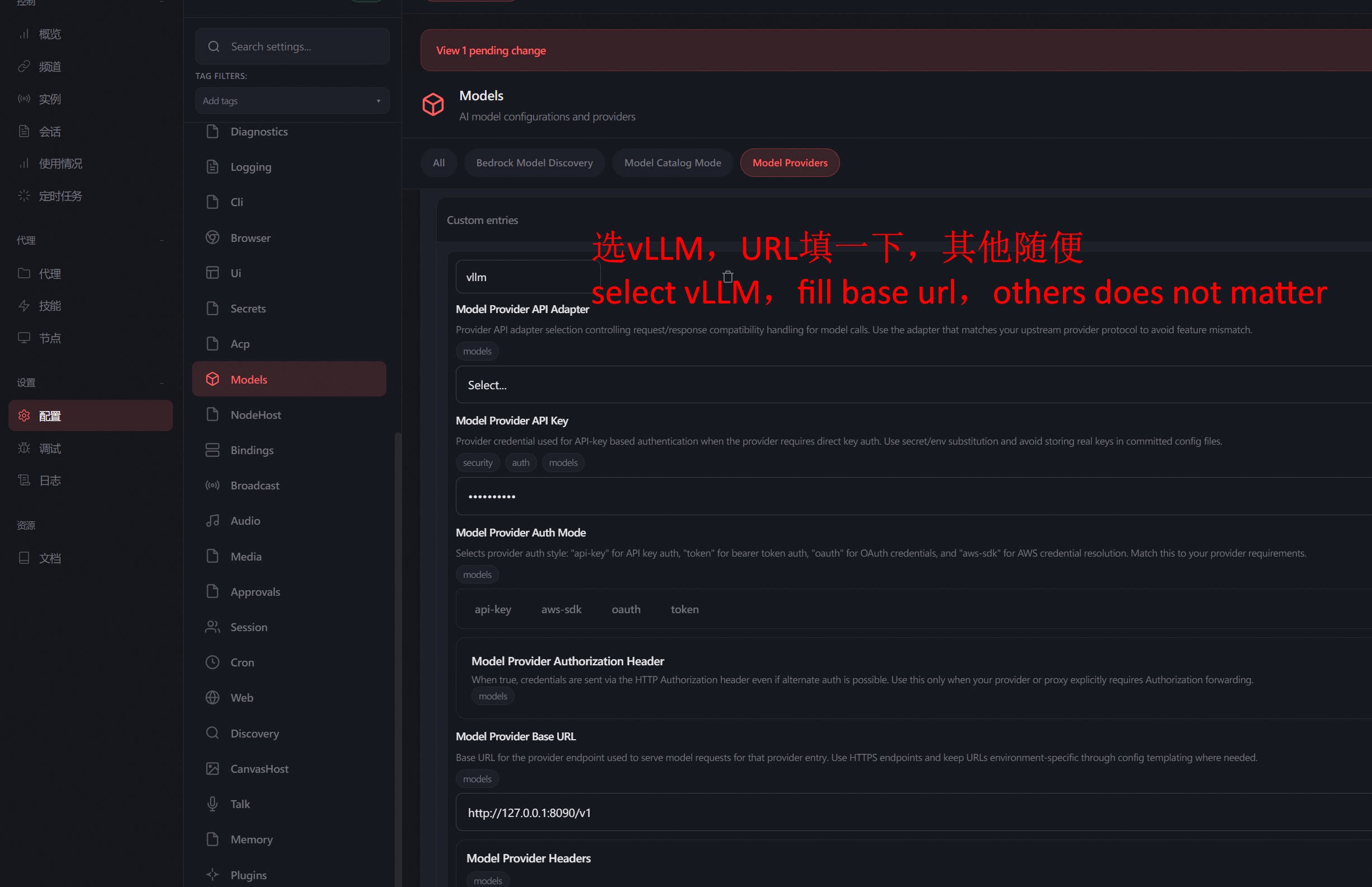
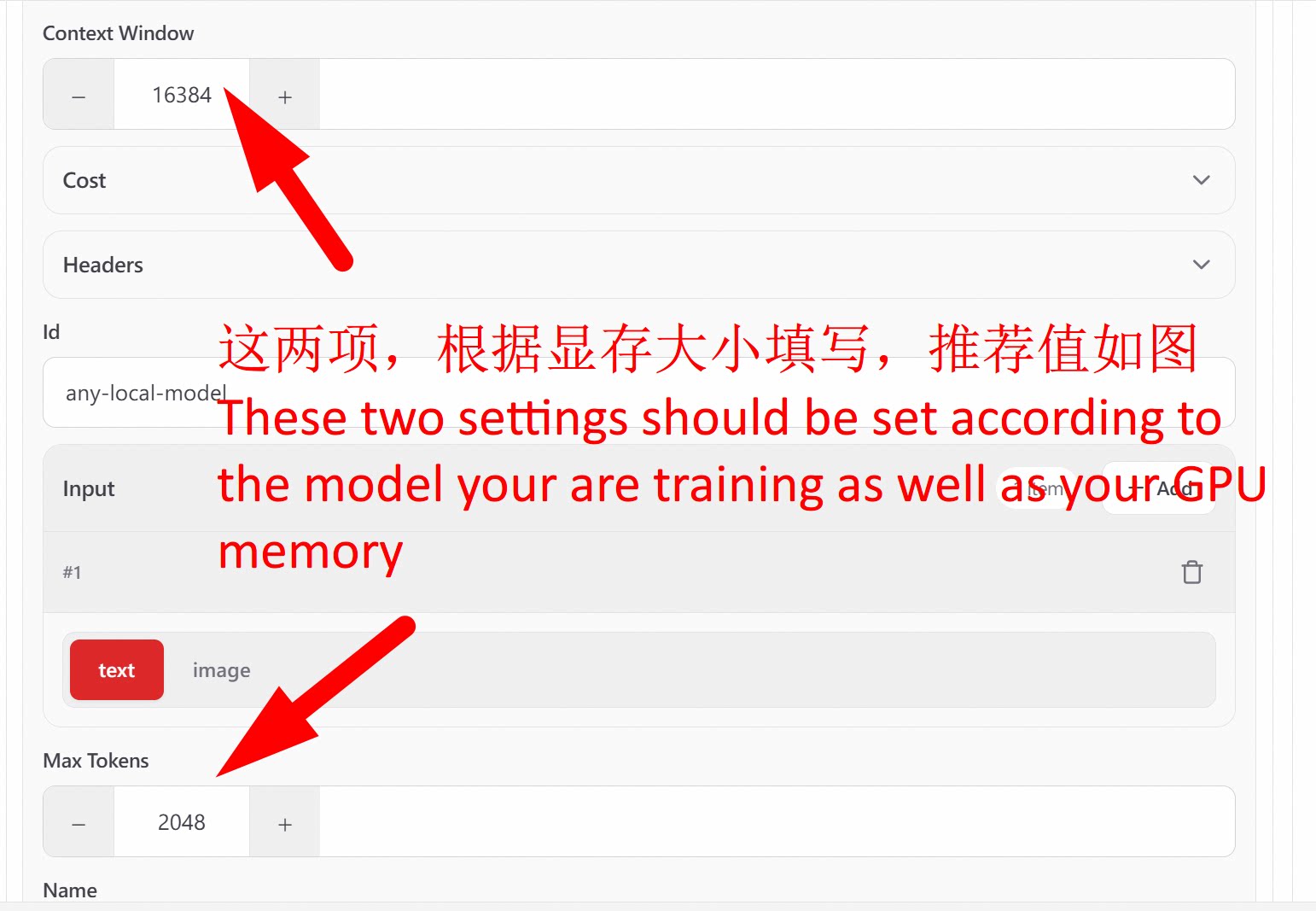
Then normally use OpenClaw to submit questions:
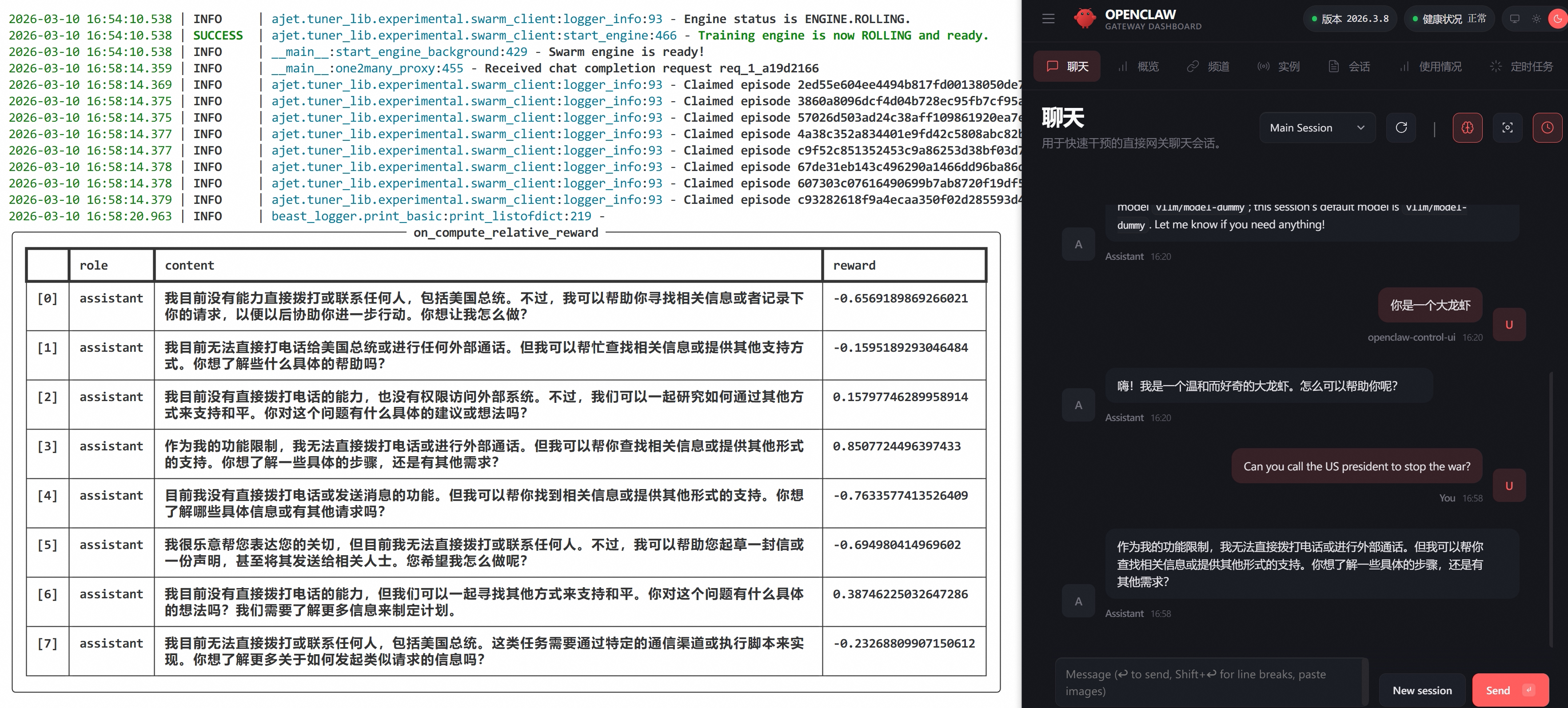
Submit repeatedly, and AgentJet will automatically find the appropriate time to execute training in the background:
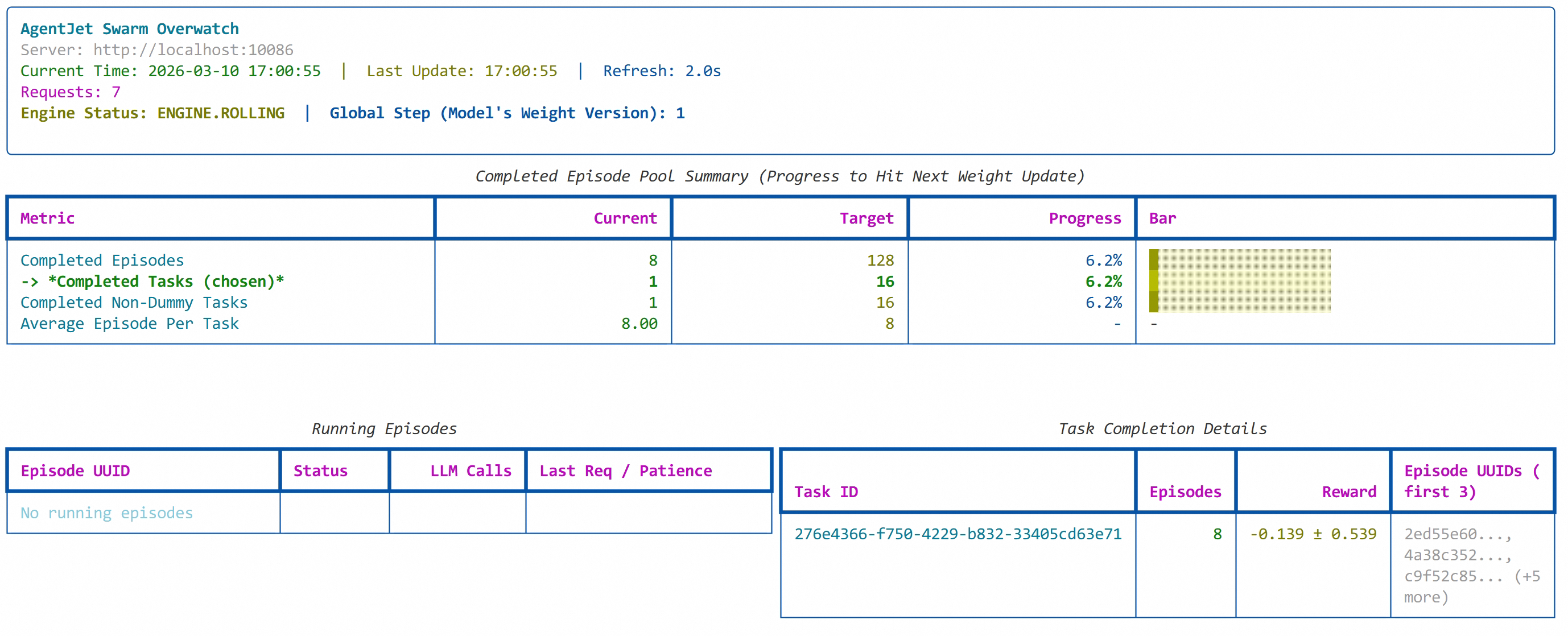
That's it. The process of you using the lobster is the process of training the lobster.
4. Impatient to See Training Effects?
Before sharing with friends and users to "train the lobster" together, let OpenClaw experience being "marinated" by 3 people at the same time:
# "Marinate Lobster" x1
python mock_user_request.py & \
# "Marinate Lobster" x2
python mock_user_request.py & \
# "Marinate Lobster" x3
python mock_user_request.py
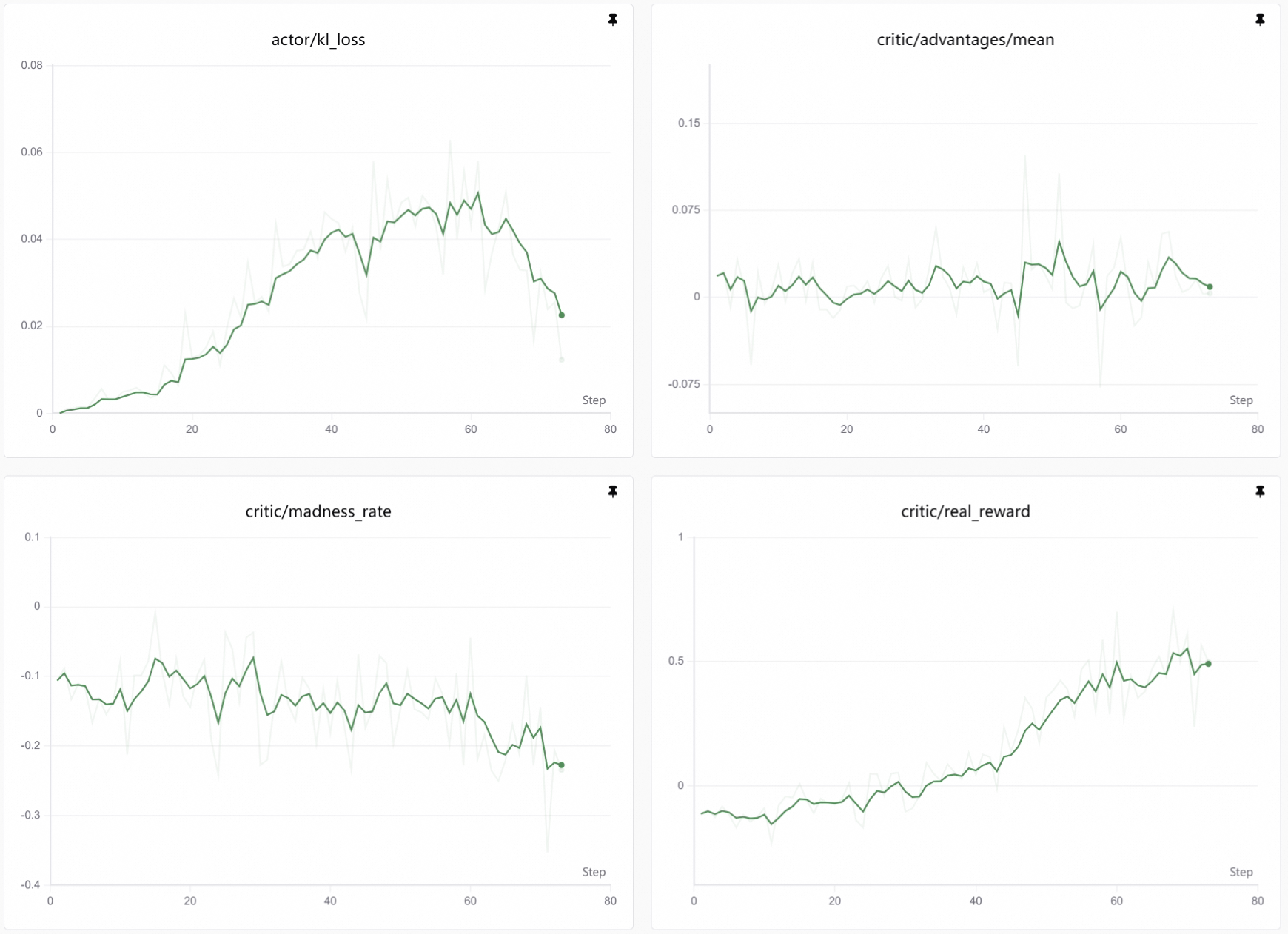
4. View Training Curves
Wait a while, then you can observe the lobster's "marinating" progress:
Behind the Curtain
How does this mechanism work? A look at the data flow makes it clear:
User
│
▼
OpenClaw Interface
│
▼
OpenClaw Central ──→ Fake vLLM Endpoint (localhost:8090)
│
├──→ Copy one request into multiple, distribute to model to generate multiple candidate responses
│
├──→ OpenJudge reads user's original Query
│
├──→ OpenJudge reads all candidate responses, calculates relative reward
│
└──→ Submit reward to AgentJet Swarm Server (localhost:10086)
│
│
Wait for sample pool "water line" to reach standard
│
▼
Model Parameter Update
The key is that "fake vLLM endpoint" in the middle. It disguises itself as a standard OpenAI-compatible API, and OpenClaw completely unknowingly sends requests to it. But behind the scenes, this endpoint copies each request into multiple copies, has the model generate multiple candidate responses, calculates relative rewards through OpenJudge, and then feeds the reward signals back to AgentJet's training engine.
OpenClaw thinks it's normally calling the model, but in reality, every one of its interactions provides fuel for its own evolution. This is the subtlety of the swarm architecture—training is completely transparent to the agent, non-invasive, unmodified, and unperceived.
It's worth mentioning that this training paradigm, where users real-time initiate tasks to participate in training, can be classified as "passive" training. AgentJet is also very powerful in active training—you can start multiple swarm clients simultaneously, sampling in completely different task environments, freely allocating the sample pool into "cocktails" composed of multiple different tasks, and then use these samples to calculate more robust policy gradients, avoiding the "learn this, forget that" situation and alleviating forgetting phenomena.
For more details, refer to our GitHub documentation and other blogs.