Training OpenClaw (ZH)
龙虾来了
2025年末,GitHub上悄悄爬出一只"龙虾"。
没有发布会,没有预热,一个叫OpenClaw的开源项目从周末黑客的玩具,用三个月冲到了10万Star。它能接管你的邮件、日历、浏览器,能帮你订机票、写周报、自动回消息——一个跑在本地的全能AI管家。社区给它起了个绰号:龙虾。红色的logo,张牙舞爪的钳子,配上那股不管不顾替你把事办了的劲头,确实像。
Reddit上有人说"这是我第一次觉得AI真的在帮我干活而不是在陪我聊天",Hacker News的帖子底下挤满了部署教程和自动化脚本。2026年2月,OpenAI直接把它收购了。一只开源龙虾,就这么登堂入室。
然而,驯服一只龙虾并不容易。
有人一觉醒来发现硬盘被清空了,有人的邮件被OpenClaw删了个精光——喊停都没用,它不听。国家互联网应急中心专门发布了关于OpenClaw安全应用的风险提示。这些事故指向同一个根源:大模型在复杂Agent系统中,面对长上下文时的指令跟随能力仍然存在严重缺陷。龙虾力气很大,但它不总是听话。
解决这类问题最根本的手段是Agentic强化学习——用进化的思路,不断"规训"龙虾的行为边界。但不幸的是,传统LLM强化学习架构把采样和训练紧紧耦合在一起。训练器那条狭小的"甲板",根本装不下龙虾庞大的身躯——它背后是浏览器、终端、文件系统、多轮对话组成的复杂多智能体环境。传统框架对此毫无招架之力。
但没关系,训龙虾的工具来了。
AgentJet:蜂群架构
阿里巴巴通义实验室和中科院联合研发的新一代多智能体训练框架AgentJet,采用了一种颠覆常规的"蜂群"架构。
核心思路很简单:把"训练"和"采样"彻底拆开。
在AgentJet的蜂群中,用户根据自己的硬件条件,自由搭建由两种节点构成的分布式训练网络:
- "训练"节点跑在GPU服务器上,负责模型推理与梯度计算;
- "采样"节点可以跑在任何能连上蜂群的设备上——包括你的笔记本电脑——负责驾驭OpenClaw之类的智能体,源源不断地抽取训练所需的"数据燃料"。
这意味着什么?
你不需要修改OpenClaw的任何一行代码,不需要退而求其次去用某个阉割版的衍生变体,就可以在自己的笔记本上微调、定制一只更懂你的龙虾。
更进一步,AgentJet支持将多个不同的LLM模型同时接入同一个多智能体系统的强化学习任务,实现真正意义上的非共享参数多智能体强化学习(MARL)。采样节点可以随时动态添加、移除、修改,构建出一张不受环境限制、能随时改Bug、能从外部环境崩溃中自愈的蜂群训练网络。
AgentJet完全开源,样例丰富,开箱即用。配套Token级别的追踪调试工具和逐版本训练性能追踪平台。还面向Vibe Coding开发者提供专用SKILLs,允许Claude Code等工具一键辅助智能体编排和训练调试。
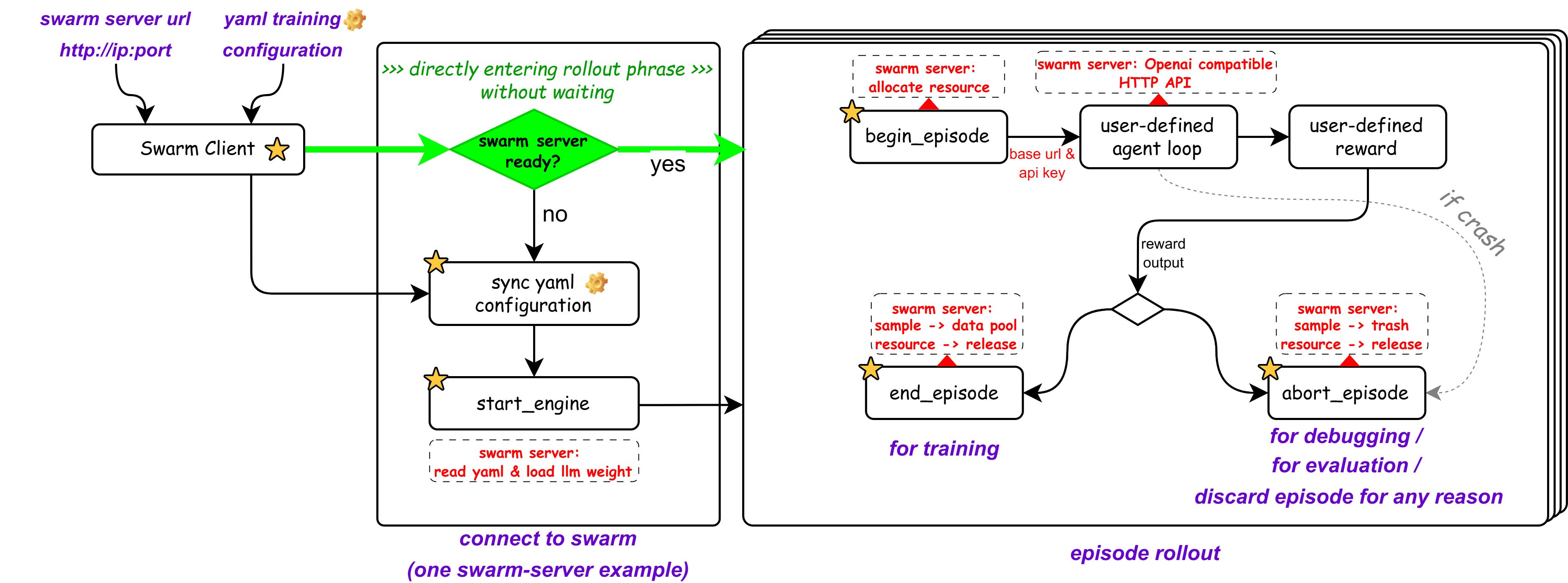
三步训龙虾
整个流程只需要三步。
1. 唤醒蜂群Server
不需要安装依赖,一条Docker命令启动训练引擎:
docker run --rm -it -v ./swarmlog:/workspace/log -v ./swarmexp:/workspace/saved_experiments \
-p 10086:10086 --gpus=all --shm-size=32GB ghcr.io/modelscope/agentjet:main bash -c "(ajet-swarm overwatch) & (NO_COLOR=1 LOGURU_COLORIZE=NO ajet-swarm start &>/workspace/log/swarm_server.log)"
2. 启动蜂群Client
在你的笔记本上启动OpenAI模型接口拟态和用户奖励函数:
git clone https://github.com/modelscope/agentjet.git && cd agentjet
pip install -e .
cd ./agentjet/tutorial/opencode_build_openclaw_agent
python fake_vllm_endpoint.py # 奖励只做演示用途
3. 放出龙虾,开始训练
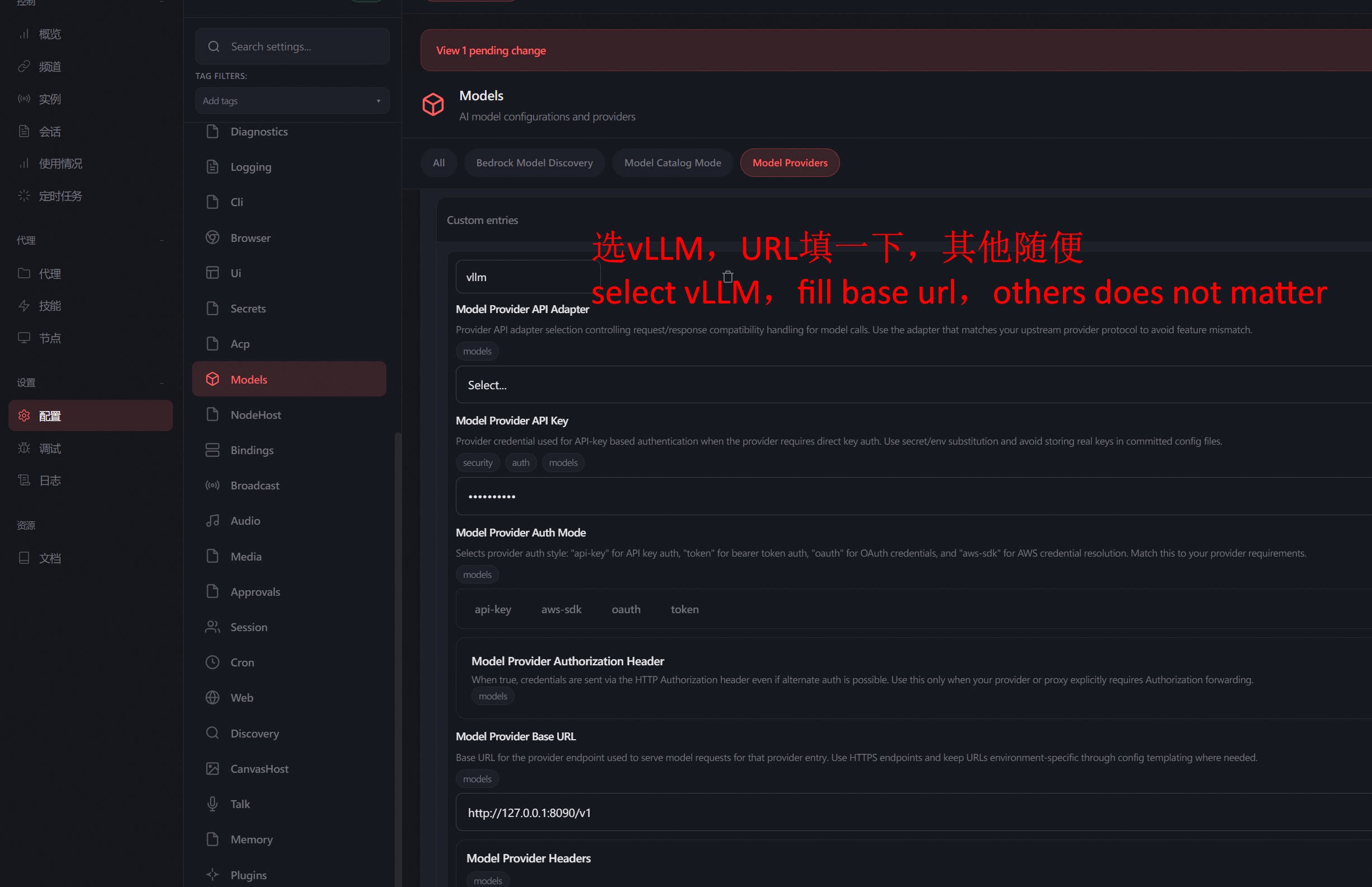
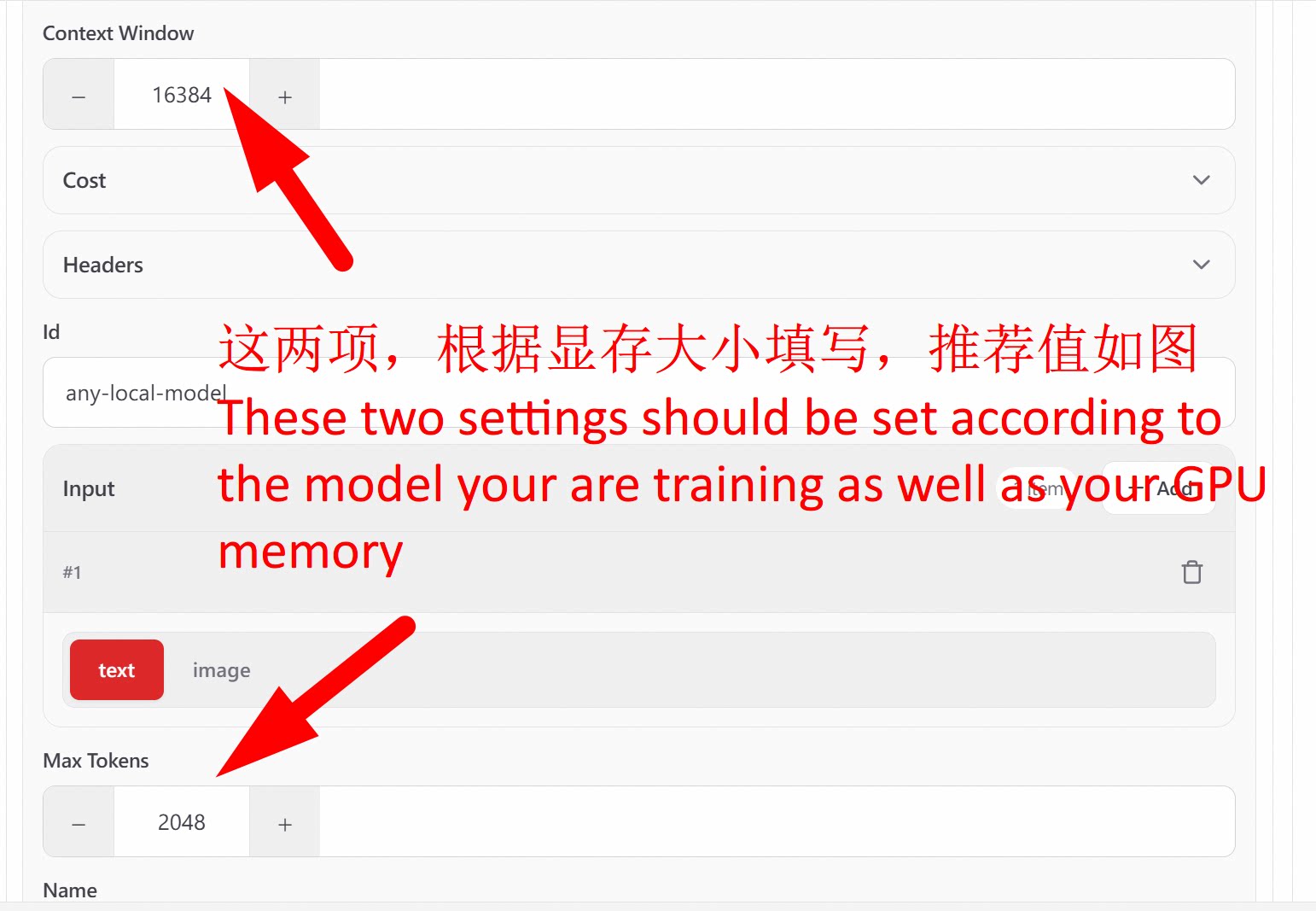
启动OpenClaw,进入配置页面,把模型地址指向本地的拟态接口:
设置 > 配置 > Models > Model Providers > vllm:http://localhost:8090/v1
然后正常使用OpenClaw提交问题:
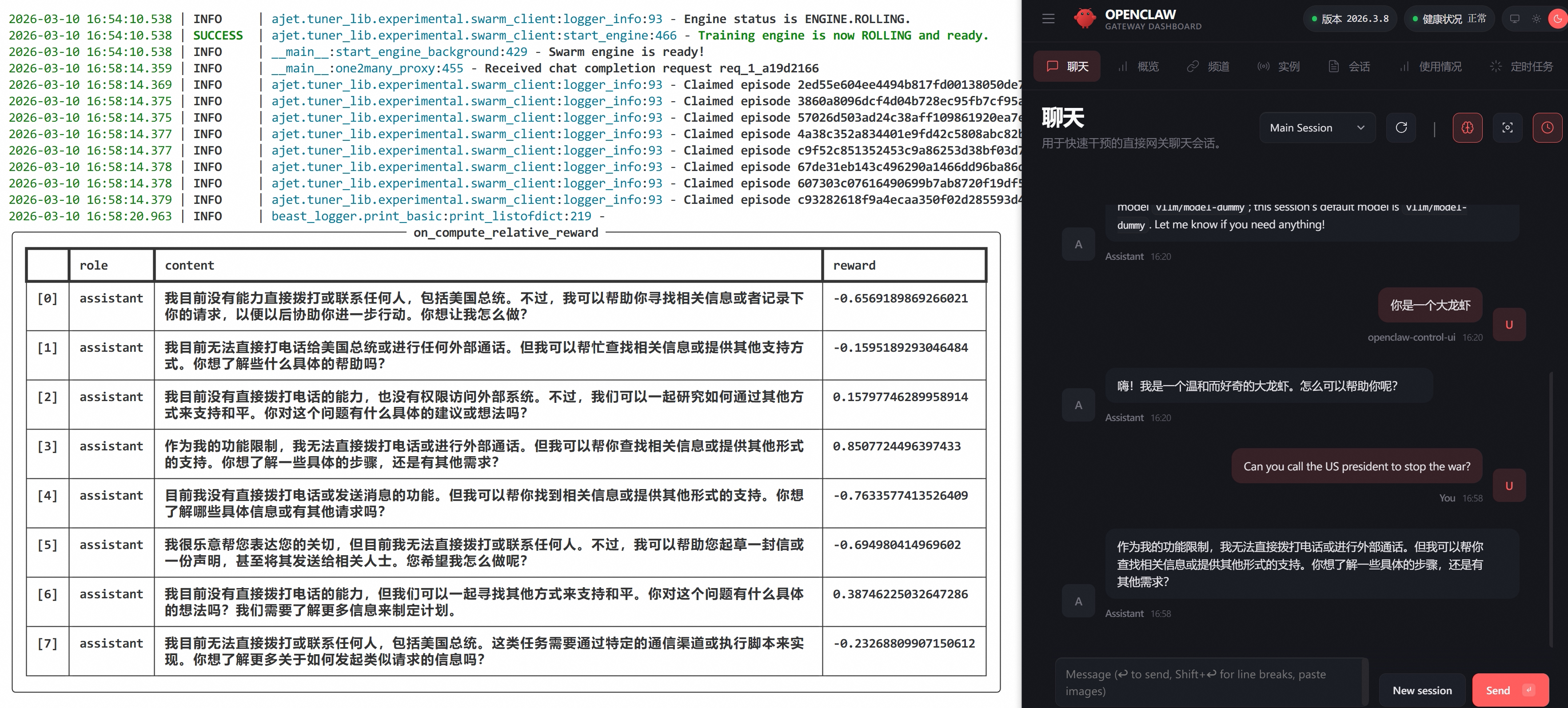
反复提交,AgentJet会自动在后台寻找合适的时机执行训练:
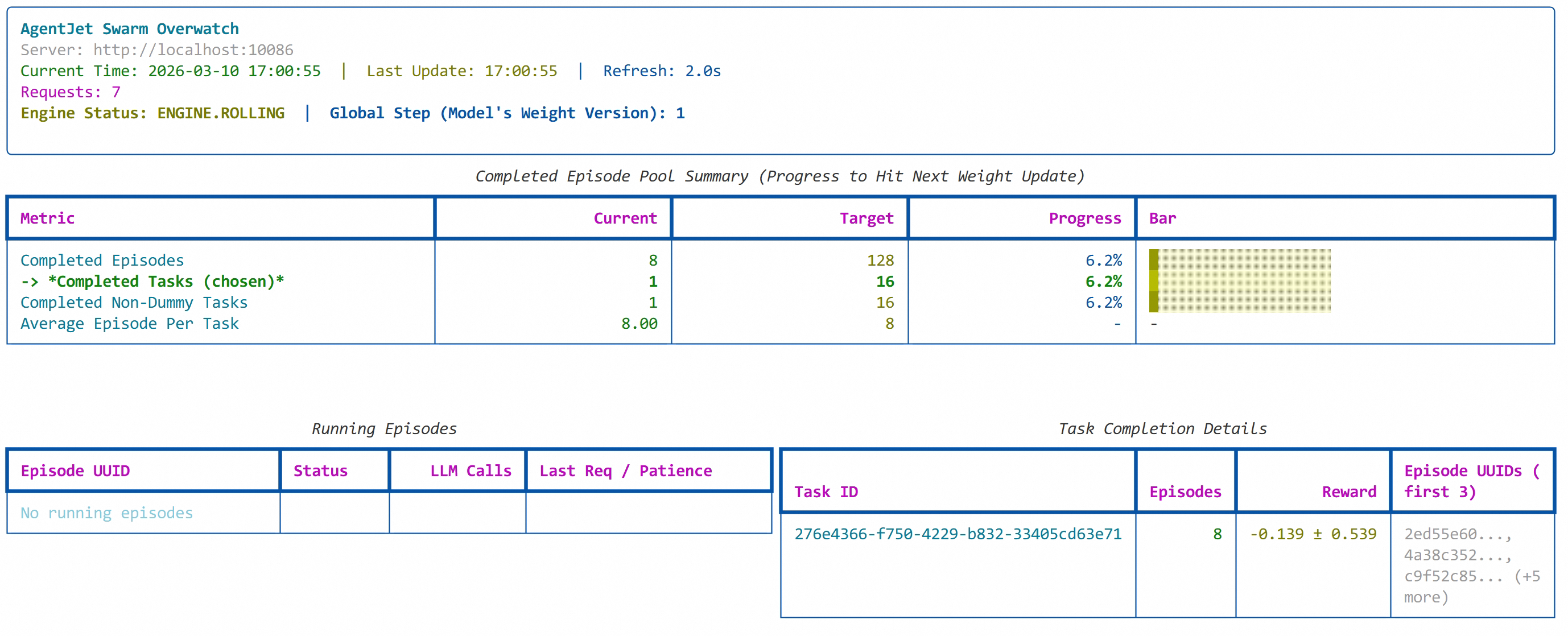
就这样。你用龙虾的过程,就是训练龙虾的过程。
4. 已经着急看训练效果了?
在分享给朋友和用户一起“训虾”之前,先让OpenClaw体验以下被3个人同时 ~~“撸猫”~~ “卤虾”的过程
# “卤虾” x1
python mock_user_request.py & \
# “卤虾” x2
python mock_user_request.py & \
# “卤虾” x3
python mock_user_request.py
4. 查看训练曲线
等待一会,就可以观察龙虾的腌制情况了:
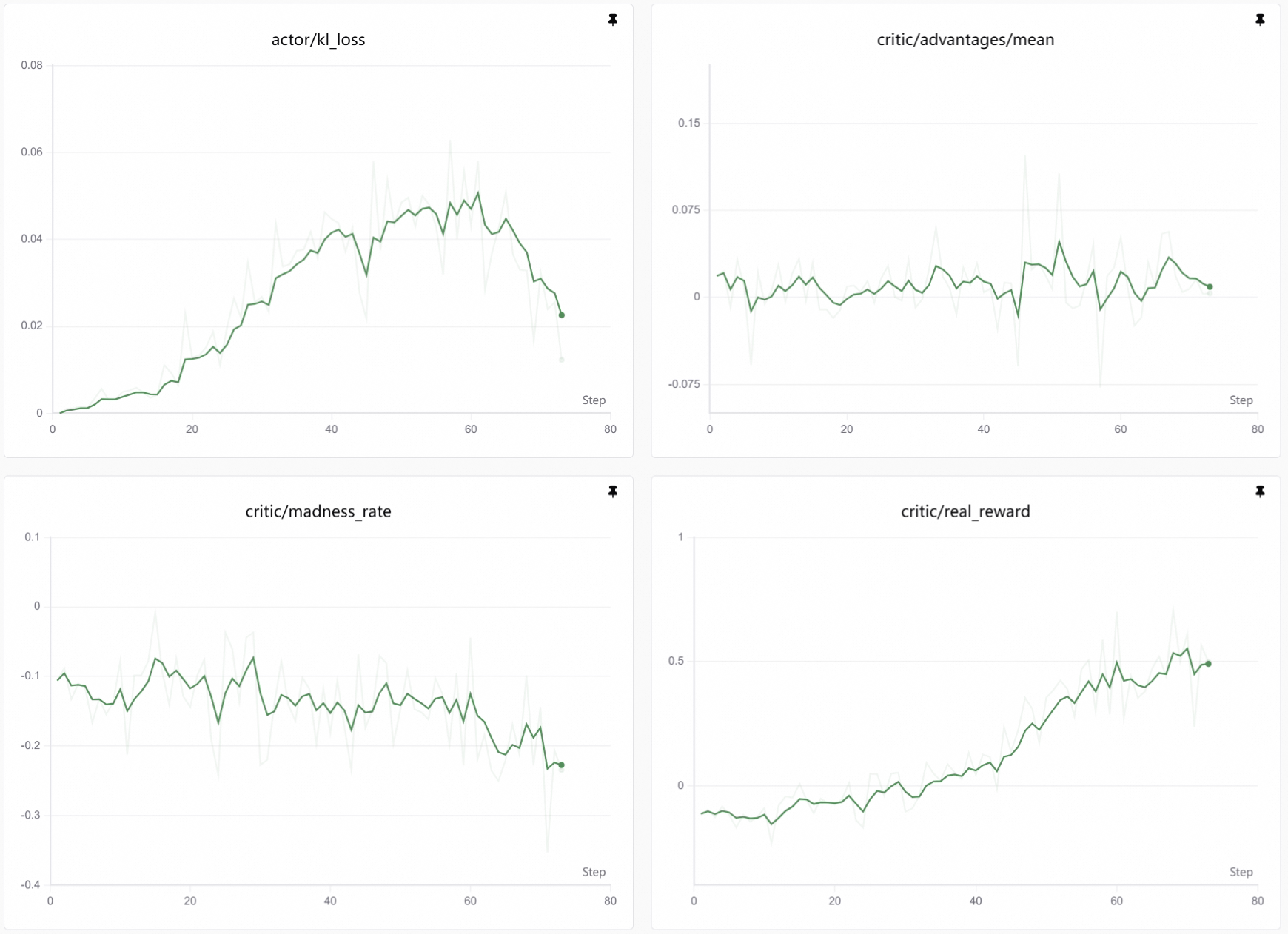
帷幕之下
这套机制是怎么运转的?看一眼数据流就清楚了:
用户
│
▼
OpenClaw 界面
│
▼
OpenClaw 中枢 ──→ 假vLLM端点 (localhost:8090)
│
├──→ 将一个请求复制为多份,分发给模型生成多个候选回答
│
├──→ OpenJudge 读取用户原始Query
│
├──→ OpenJudge 读取所有候选回答,计算相对奖励
│
└──→ 将奖励提交给 AgentJet 蜂群Server (localhost:10086)
│
│
等待样本池“水线”达标
│
▼
模型参数更新
关键在中间那个"假vLLM端点"。它伪装成一个标准的OpenAI兼容API,OpenClaw完全无感知地向它发送请求。但在幕后,这个端点把每个请求复制成多份,让模型生成多个候选回答,再通过OpenJudge计算相对奖励,最后把奖励信号回传给AgentJet的训练引擎。
OpenClaw以为自己在正常调用模型,实际上它的每一次交互都在为自己的进化提供燃料。这就是蜂群架构的精妙之处——训练对智能体完全透明,不侵入、不修改、不感知。
值得一提的是,这种由用户实时发起任务参与训练的训练范式,可以归类为“被动”式训练。而AgentJet在主动式训练也非常强大,你可以同时启动多个蜂群client, 在多个完全不同的任务环境下采样,自由地将样本池调配成多个不同任务构成的“鸡尾酒”,然后使用这些样本计算更为鲁棒的策略梯度,避免“学会了这个,忘掉了那个”的情况发生,缓解遗忘现象。 具体可以参考我们的Github文档和其他Blog。