This article is a translated version of the Chinese original.
Abstract
In reinforcement learning research, the journey from inspiration to writing code to generating the first successful training curve is long and tedious. Fortunately, with the AgentJet framework, going from idea to successful training is now just a matter of speaking up and spending a few minutes writing some prompts. After a short wait, you get to see complete, concise, human-readable and editable training code alongside the first training curve displayed before you. In this article, we use the classic "Who is the Spy" board game as an example to demonstrate the entire process of training an Agent without writing code.
Install AgentJet Environment
You can choose to install manually or use skills. Run the following commands to copy skills into Claude Code or OpenCode:
After the skills are added, you can instruct Claude Code or OpenCode to install AgentJet using uv (or conda / docker).
Write the Prompt
Once AgentJet is installed, you can get started right away. Open OpenCode (while ClaudeCode is more powerful, the author prefers fully open-source tools; moreover, Vibe RL difficulty in AgentJet is quite low, so we don't need a very strong agent), then select the claude-4.5-sonnet model (this model is faster than opus for reasoning speed and sufficient for tasks that aren't too difficult), and start executing the task:
Your task:
- Write an agent that learns the "Who is the Spy" task, trained using a combination of reinforcement learning and supervised learning. The game rules are as follows:
- The game has N players, most of whom are **civilians**, with a few being **spies**
- At the start of the game, each civilian receives the same **civilian word**, and each spy receives a **spy word** that is similar to the civilian word but different (e.g., civilian word is "apple", spy word is "pear")
- In each round, all players take turns giving **verbal descriptions** of their word. The description must truthfully reflect the word, but cannot directly say the word itself or expose the player's identity too obviously
- After all players have described, the game enters the **voting phase**, where all players vote for who they think is the most suspicious spy. The player with the most votes is eliminated
- The game continues for multiple rounds until one of the following end conditions is met:
- **Civilians win**: All spies are eliminated
- **Spies win**: The number of spies >= the number of civilians (spies have the numerical advantage)
- The agent needs to master two core abilities through extensive gameplay:
- **Description strategy learning**: Learn to generate optimal descriptions based on the agent's word and current game state that neither expose identity nor alienate teammates
- **Reasoning and decision learning**: Learn to accurately identify spies based on conversation history, other players' description patterns, and behavioral characteristics, and make optimal voting decisions
- Training objective: Maximize the agent's win rate across different roles (civilian/spy), continuously optimizing strategy through self-play and reward mechanisms
- I want to use the base model `/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2.5-7B-Instruct`
- Use 8 GPUs for training
- Batch Size 16
- I don't have a dataset yet, please help me mock some game data for testing and initial training
- Use OpenAI SDK, flexibly use Tools
- Code must not contain Chinese characters
Your skill (please read this SKILL file first to get necessary knowledge):
./ajet/copilot/write-swarm-client/SKILL.md
- Additional requirements:
- optional 0. (agent_roll) Team A civilians share one 7B model, Team B spies use qwen-max (DASHSCOPE_API_KEY is already in environment variables),
each episode randomly assigns each player's ID and name (randomly generate a long list of random names), winner gets reward 1, loser gets reward 0
- optional 1. (agent_roll_adv) Adversarial training, Team A civilians share one 7B model (swarm server 1), Team B spies share another 7B model (swarm server 2),
each episode randomly assigns each player's ID and name (randomly generate a long list of random names), winner gets reward 1, loser gets reward 0
- Additional requirements:
agent_roll: Use 4 GPUs
agent_roll_adv: swarm server 1 and swarm server 2 each use 4 GPUs (total 8 GPUs)
- Additional requirements: Use tmux + uv's .venv for debugging until all bugs are fixed & training starts normally. You can use `spy-swarm-server`, `spy-swarm-server-2`, `spy-swarm-client` three tmux sessions
- Current debugging stage:
Debugging agent_roll [Execute debugging]
Debugging agent_roll_adv [Skip debugging]
Check Results
Generated Training Code
Under the guidance of the agentjet skill, OpenCode generates all training code in tutorial/opencode_build_***:
(base) ➜ agentjet git:(main) ✗ tree tutorial/opencode_build_spy_game
tutorial/opencode_build_spy_game/
├── mock_dataset.py # Generate mock game configurations
├── mock_game_dataset.json # 200 game scenarios with word pairs
├── game_engine.py # Core game mechanics and player logic
├── agent_run.py # Agent executor for agent_roll mode
├── agent_roll.py # Training script for agent_roll mode
├── agent_run_adv.py # Agent executor for adversarial mode
├── agent_roll_adv.py # Training script for adversarial mode
└── readme.md # This file
Inspect the Training Swarm, Find and Fix Agent Training Bugs
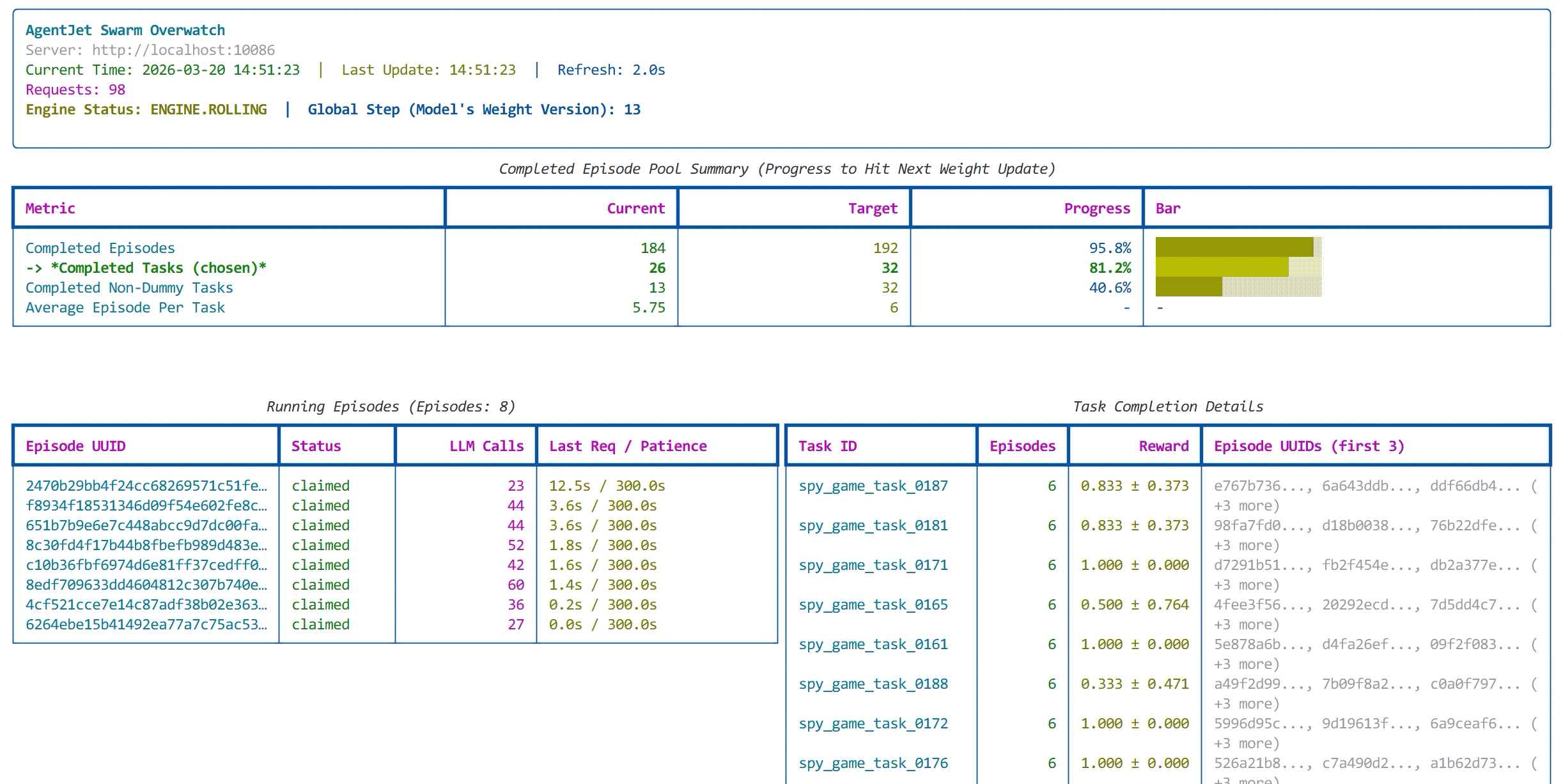
After waiting a while, running the ajet-swarm overwatch command shows the current training progress:
Completed Episode Pool Summary (Progress to Hit Next Weight Update)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Metric ┃ Current ┃ Target ┃ Progress ┃ Bar ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Completed Episodes │ 140 │ 16 │ 875.0% │ █████████████████████████████████████████████████████████████████████ │
│ │ │ │ │ █████████████████████████████████████████████████████████████████████ │
│ │ │ │ │ █████████████████████████████████████ │
│ -> *Completed Tasks (chosen)* │ 1 │ 4 │ 25.0% │ █████░░░░░░░░░░░░░░░ │
│ Completed Non-Dummy Tasks │ 1 │ 4 │ 25.0% │ █████░░░░░░░░░░░░░░░ │
│ Average Episode Per Task │ 140.00 │ 4 │ - │ - │
└────────────────────────────────────────┴─────────────┴─────────────┴──────────────┴───────────────────────────────────────────────────────────────────────┘
Task Completion Details
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Task ID ┃ Episodes ┃ Reward ┃ Episode UUIDs (first 3) ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ │ 140 │ 0.779 ± 0.448 │ b47d7b96..., 8caec2d7..., b48bd9fb... (+137 more) │
└──────────────┴───────────────┴───────────────────────┴───────────────────────────────────────────────────────────────────────────┘
From the swarm monitoring table, the sample pool has accumulated 875.0% (140) episode samples, but AgentJet hasn't started training yet. Looking closer, the Completed Tasks progress is only 1, meaning all 140 episodes were identified as one task. The task IDs for these samples? They're empty strings. No doubt, claude-sonnet produced a hilarious bug in the mock dataset. We give OpenCode a new directive:
task.task_id has a serious problem - task_id should be a random seed for each episode and must not be empty!
While we're at it, we adjust some parameters: batch size from 4 to 32, grpo_n from 4 to 6. Then we have a cup of tea and come back. This time it works.
To ensure the agent logic is correct, we also open beast_logger (the log monitoring component that comes with agentjet):
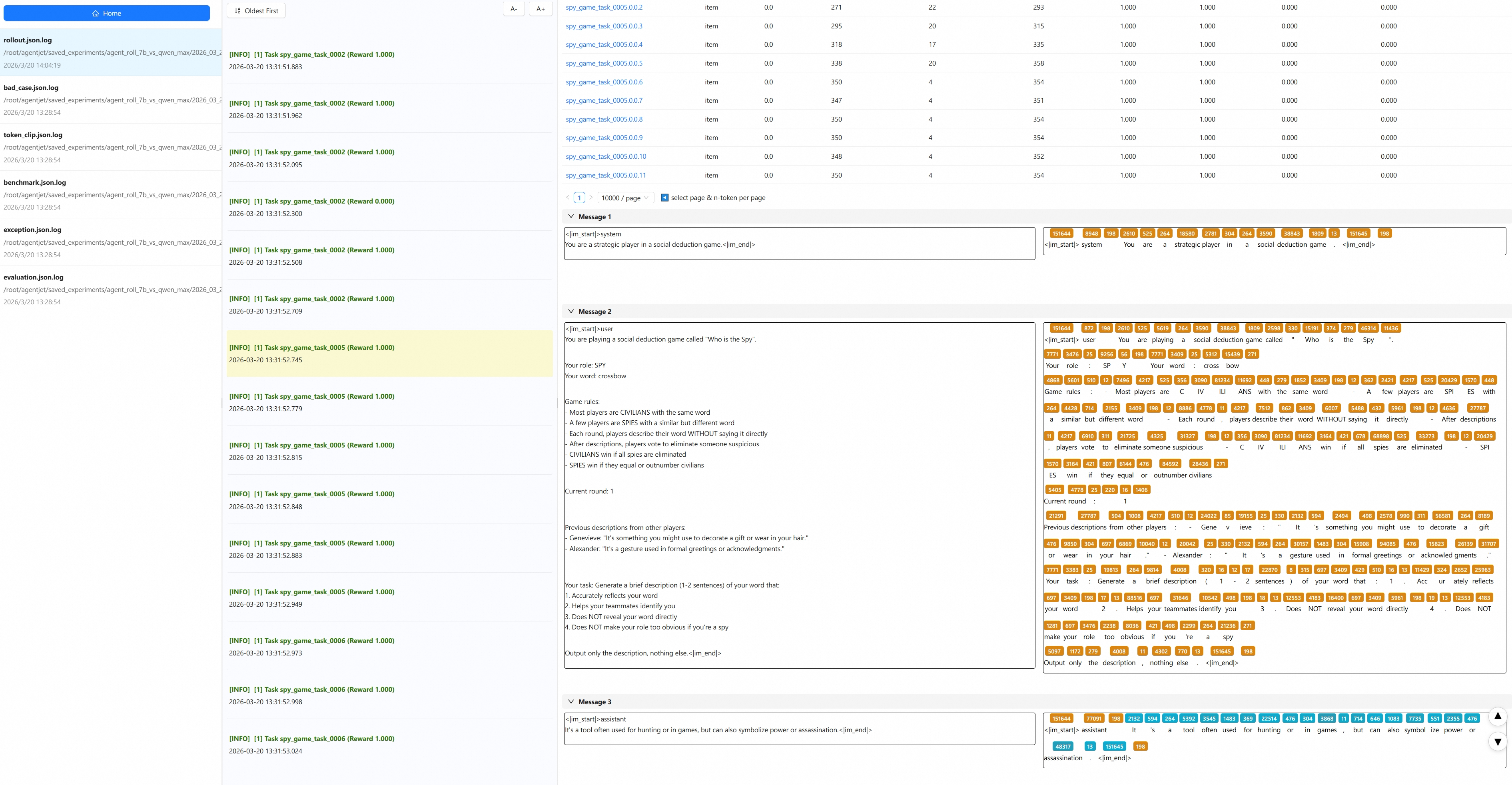
One look and sure enough, there are still issues (slightly regretting not using opus). Our requirement was that Team A civilians share one brain with a 7B model, while Team B spies use qwen-max. But why did a spy sneak into the civilian team? This time we need claude-sonnet to reflect carefully:
After a while, we check again and the issues are all fixed.
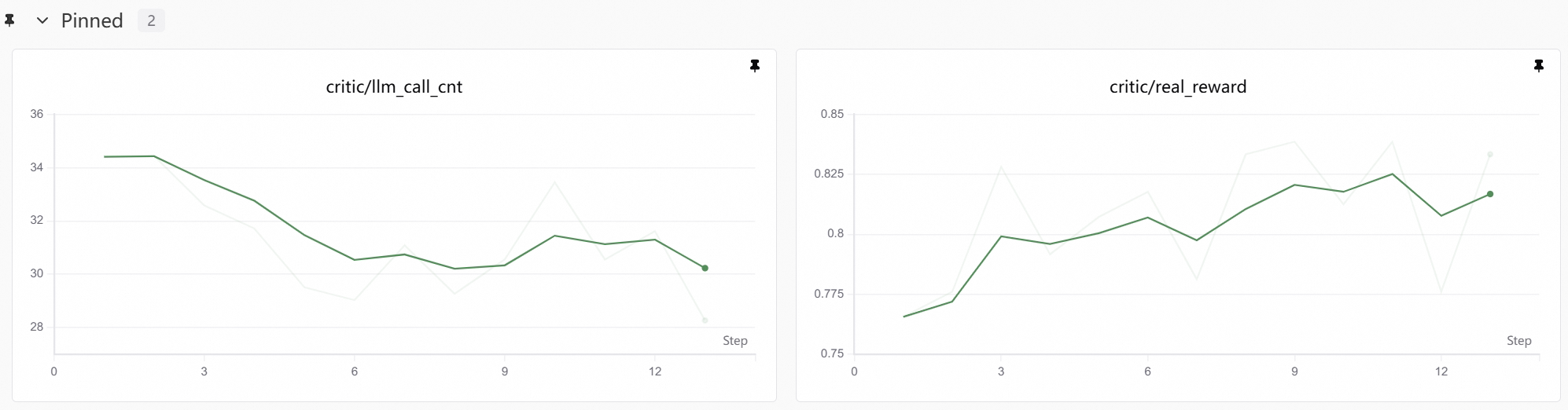
Check Training Curves
Heading over to SwanLab — not bad, the reward is steadily climbing.