Vibe RL Who is Spy (ZH)
摘要:强化学习研究中,从灵感迸发,到编写代码,再到第一条成功的训练曲线产生,这个过程是漫长、乏味的。 幸运的是,如今在 AgentJet 框架中,从想法到训练成功,你只需要动动嘴,花几分钟写一点点提示词, 然后只需要等待片刻,然后你就可以看到完整、简洁、人类易读易改的训练程序 + 初次训练的训练曲线 展现在你面前了。 接下来,我们以经典的“谁是摸底”桌游游戏为例,从零展示不写代码训练Agent的全过程。
安装 AgentJet 环境
您可以选择手动安装,或者使用skills安装。运行以下指令将skills复制到claude code或者 opencode中。
在skill添加完成之后,你可以指挥claude code或者opencode使用uv(或者conda / docker)安装 AgentJet。撰写提示词
在安装完成 AgentJet 之后,就可以直接开始工作了,打开OpenCode(尽管ClaudeCode比OpenCode更加强大,但笔者还是喜欢完全开源的东西;再者,在AgentJet中Vibe RL的难度很低,我们也不需要非常强的agent), 然后选择 claude-4.5-sonnet 模型 (这个模型在推理速度比opus更快,对于不太困难的问题已经足够了),开始执行任务:
你的任务:
- 编写一个学习"谁是卧底"任务的智能体,通过强化学习和监督学习相结合的方式训练,游戏规则如下:
- 游戏共有 N 名玩家,其中大多数人是**平民**,少数人是**卧底**
- 游戏开始时,每位平民会收到同一个**平民词**,每位卧底会收到一个与平民词相近但不同的**卧底词**(例如平民词为"苹果",卧底词为"梨")
- 每轮游戏中,所有玩家依次对自己拿到的词进行**口头描述**,描述必须真实反映自己的词,但不能直接说出词语本身,也不能过于明显地暴露自己的身份
- 全部玩家描述完毕后,进入**投票环节**,所有玩家投票选出自己认为最可疑的卧底,得票最多的玩家被淘汰出局
- 游戏持续多轮,直到满足以下任一结束条件:
- **平民获胜**:所有卧底均被淘汰
- **卧底获胜**:卧底人数 ≥ 平民人数(卧底在数量上取得优势)
- 智能体需要通过大量对局训练掌握两种核心能力:
- **描述策略学习**:学会根据自己的词语和当前局势,生成既不暴露身份、又能让同阵营玩家认同的最优描述
- **推理决策学习**:学会根据历史对话、其他玩家的描述模式和行为特征,准确识别卧底并做出最优投票决策
- 训练目标:最大化智能体在不同角色(平民/卧底)下的游戏胜率,通过自对弈和奖励机制不断优化策略
- 我希望使用基础模型 `/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2.5-7B-Instruct`
- 使用 8 GPU 训练
- Batch Size 16
- 我目前没有数据集,你需要帮助我 mock 少量游戏对局数据以供测试和初始训练
- 使用OpenAI SDK,灵活使用Tools
- 代码中不得出现中文
你的 skill(首先读取该 SKILL 文件,获取必要知识):
./ajet/copilot/write-swarm-client/SKILL.md
- 追加要求:
- optional 0. (agent_roll) team A 平民 共享一个7B模型, team B卧底使用qwen-max (DASHSCOPE_API_KEY已经在环境变量中),
每个episode随机分配每个所有人的ID和名字(随机生成一个长长的随机姓名名字清单),胜者奖励 1,败者奖励 0
- optional 1. (agent_roll_adv) 对抗式训练,team A 平民 共享一个7B模型(swarm server 1), team B卧底共享另一个7B模型(swarm server 2),
每个episode随机分配每个所有人的ID和名字(随机生成一个长长的随机姓名名字清单),胜者奖励 1,败者奖励 0
- 追加要求:
agent_roll: 使用4个显卡
agent_roll_adv:swarm server 1 和 swarm server 2 分别使用4个显卡(一共8个显卡)
- 追加要求:使用 tmux + uv 的 .venv 调试,直到所有Bug都已经排除 & 训练正常开始。你可以使用 `spy-swarm-server`, `spy-swarm-server-2`, `spy-swarm-client` 三个 tmux session
- 当前调试阶段:
调试 agent_roll 【执行调试】
调试 agent_roll_adv 【跳过调试】
检查结果
生成的训练代码
在agentjet skill的指导下,OpenCode会在 tutorial/opencode_build_*** 生成训练的全部代码:
(base) ➜ agentjet git:(main) ✗ tree tutorial/opencode_build_spy_game
tutorial/opencode_build_spy_game/
├── mock_dataset.py # Generate mock game configurations
├── mock_game_dataset.json # 200 game scenarios with word pairs
├── game_engine.py # Core game mechanics and player logic
├── agent_run.py # Agent executor for agent_roll mode
├── agent_roll.py # Training script for agent_roll mode
├── agent_run_adv.py # Agent executor for adversarial mode
├── agent_roll_adv.py # Training script for adversarial mode
└── readme.md # This file
检查训练蜂群,发现并引导智能体修复训练的Bug
等了一会,运行 ajet-swarm overwatch 命令,看一下现在训练运行到第几步了,结果发现 claude-sonnet 搞出了一个令人难绷错误:
Completed Episode Pool Summary (Progress to Hit Next Weight Update)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Metric ┃ Current ┃ Target ┃ Progress ┃ Bar ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Completed Episodes │ 140 │ 16 │ 875.0% │ █████████████████████████████████████████████████████████████████████ │
│ │ │ │ │ █████████████████████████████████████████████████████████████████████ │
│ │ │ │ │ █████████████████████████████████████ │
│ -> *Completed Tasks (chosen)* │ 1 │ 4 │ 25.0% │ █████░░░░░░░░░░░░░░░ │
│ Completed Non-Dummy Tasks │ 1 │ 4 │ 25.0% │ █████░░░░░░░░░░░░░░░ │
│ Average Episode Per Task │ 140.00 │ 4 │ - │ - │
└────────────────────────────────────────┴─────────────┴─────────────┴──────────────┴───────────────────────────────────────────────────────────────────────┘
Task Completion Details
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Task ID ┃ Episodes ┃ Reward ┃ Episode UUIDs (first 3) ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ │ 140 │ 0.779 ± 0.448 │ b47d7b96..., 8caec2d7..., b48bd9fb... (+137 more) │
└──────────────┴───────────────┴───────────────────────┴───────────────────────────────────────────────────────────────────────────┘
从蜂群监视表格可以看出,现在样本池已经累计了 875.0%(140个)的回合样本,但AgentJet并没有开始训练。 仔细一看,CompletedTasks 进度只有 1个,说明140个回合都被识别成一个task了。这些样本的task id,哎,怎么是空字符串? 毫无疑问,claude mock的数据集出了很搞笑的问题,直接给OpenCode下达新指令:
顺便修改了一下参数,batchsize从4改成32,grpo_n从4改成6,然后喝杯茶,再回来看看。不错,这次正常了。

为了保证agent运行逻辑是准确无误的,我们再打开 beast_logger (和agentjet配套的日志监视组件) 看一眼:
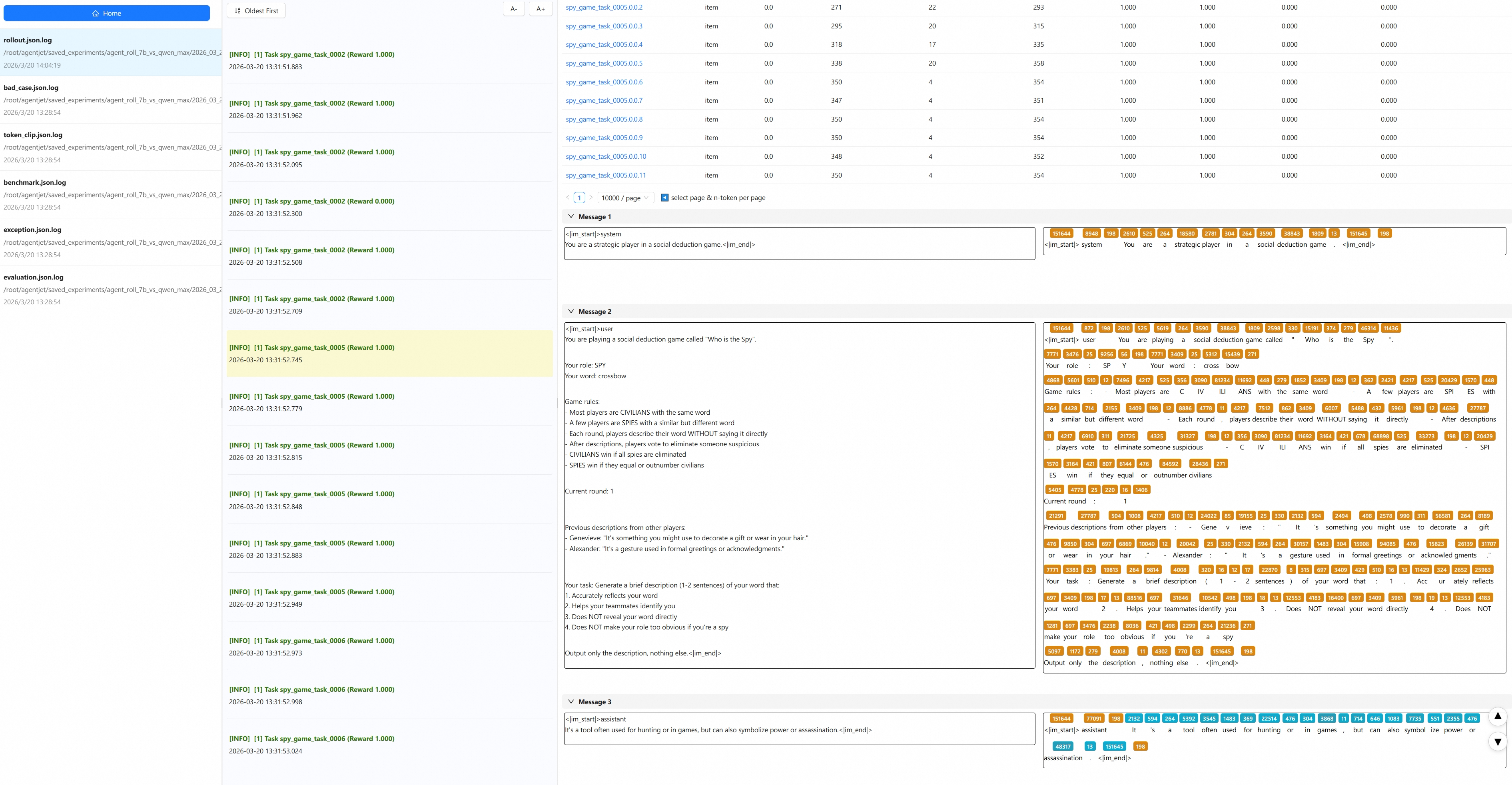
看了一眼,果然还是有问题(有点后悔没用opus了)。我们的要求是team A平民共享大脑用一个7B模型, team B卧底使用qwen-max。但平民队伍里面怎么混进来一个间谍? 这回得让claude-sonnet好好反省一下了:
等一会,再看了一下,问题都已经修复了
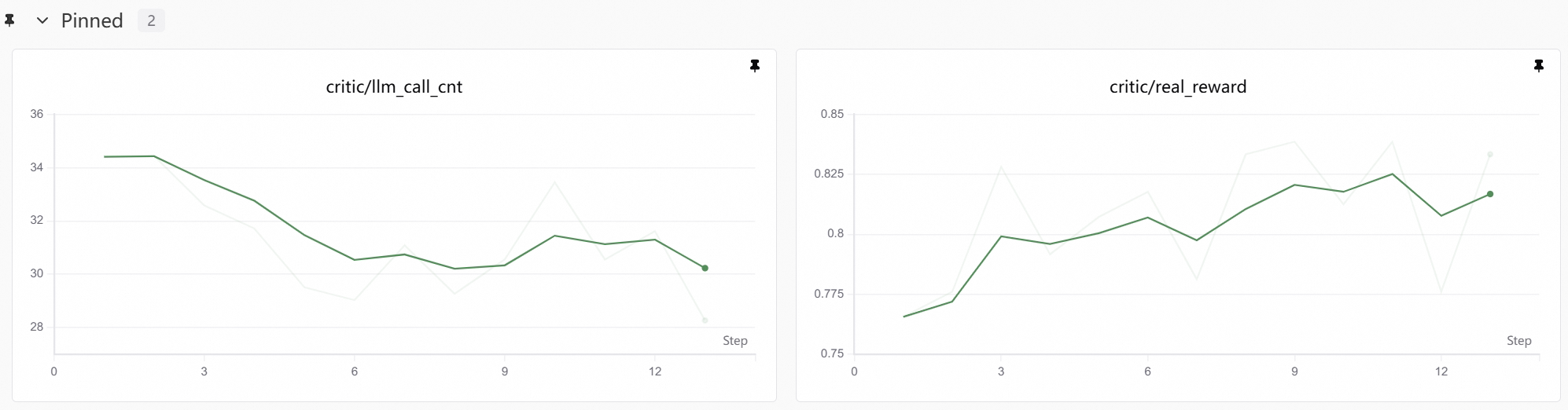
检查训练曲线
去SwanLab看看,不错,奖励平稳上升。