This tutorial demonstrates how to train multiple agents to play the Werewolves game.
1. Overview
The Werewolves role-playing game is a typical POMDP (Partially Observable Markov Decision Process) problem. We can train agents in this cooperative multi-agent problem using shared-parameter methods.
Terms explained:
- Partially Observable: Agents are only able to receive local information. One agent cannot obtain others' perception, even if they are teammates.
- Markov Decision Process: Making decisions according to current situations.
- Shared-parameter: Using one model as policy for multiple agents. But notice agents share policy (model parameters) but do not share perception (model input).
- Cooperative multi-agent problem: Agents have aligned interests (reward).
- Environment: We use static
Qwen3-235B-A22Bas the brain of opponents. We useQwen2-7Bas the brain of trainable agents (trainable_targets).
This page shows how to use the Werewolves social deduction game as a multi-agent environment to prepare data and environment, write an AgentScope Workflow, configure the reward module (Judge), and complete the full process from local debugging to formal training.
Scenario Overview
- Scenario: Classic Werewolves game, including roles such as werewolf, villager, seer, witch, and hunter.
- Goal: Train a specific role (in this example, the
werewolf) to achieve a higher win rate in games.
2. Quick Start
Start training with the following command:
# ( ajet --kill="python|ray|vllm" )
ajet --conf tutorial/example_werewolves/werewolves.yaml --backbone='verl'
Quick Debugging (Optional)
If you want to breakpoint-debug the workflow/judge locally: When `--backbone=debug`, Ray is disabled. You can use a VSCode `.vscode/launch.json` like below:3. Understand
3.1 Core Process
At a high level, each training iteration follows this flow:
- The task reader generates a new game setup (players, role assignments, initial state).
- The rollout runs the AgentScope workflow to simulate a full game.
- Agents in
trainable_targetsact by using the trainable model (viatuner.as_agentscope_model(...)), while opponents use the fixed model. - The environment produces rewards / outcomes for the episode.
- Trajectories are collected and passed to the backbone trainer (
verlortrinity) to update the trainable model.
3.2 Configuration Details
This section corresponds to tutorial/example_werewolves/werewolves.yaml. The key configuration items are as follows:
ajet:
task_reader:
# random seed to shuffle players
type: random_dummy
task_judge:
# Implement and select the evaluation function
# (in this example you can first set it to null and rely purely on the rollout's internal reward)
judge_protocol: null
model:
# Set the model to be trained
path: YOUR_MODEL_PATH
rollout:
# Select the AgentScope Workflow entry
user_workflow: tutorial.example_werewolves.start->ExampleWerewolves
3.3 Code Map
tutorial/example_werewolves/werewolves.yaml: connects the task reader, judge, model, and workflow entry.tutorial/example_werewolves/start.py: the AgentScope workflow implementation (ExampleWerewolves).tutorial/example_werewolves/game.py: the Werewolves game logic implementation.tutorial/example_werewolves/prompt.py: prompt templates related to the game.tutorial/example_werewolves/structured_model.py: defines structured output formats for different roles.tutorial/example_werewolves/utils.py: game state management and helper functions.
3.4 Reward
When judge_protocol: null, training relies on the reward (or win/loss outcome) produced inside the rollout / environment. In this example, the reward is produced in the workflow in tutorial/example_werewolves/start.py.
In ExampleWerewolves.execute(), the workflow first runs a full game by calling werewolves_game(players, roles), and obtains good_guy_win (whether the good-guy side wins).
Then it uses a turn-level sparse win/loss reward:
- If
good_guy_win == Trueand the training target is notwerewolf(i.e., you are training a good-guy role), thenraw_reward = 1andis_success = True. - If
good_guy_win == Falseand the training target iswerewolf(i.e., you are training a werewolf-side role), thenraw_reward = 1andis_success = True. - Otherwise, the training side did not win:
raw_reward = 0andis_success = False.
Exception / invalid-behavior penalty:
- If an exception is thrown during the game (e.g., the game cannot proceed), all trainable targets are penalized uniformly:
raw_reward = -0.1andis_success = False.
If you need a more fine-grained evaluation (e.g., giving partial credit for key intermediate decisions instead of only win/loss), implement a custom Judge and enable it via ajet.task_judge.judge_protocol.
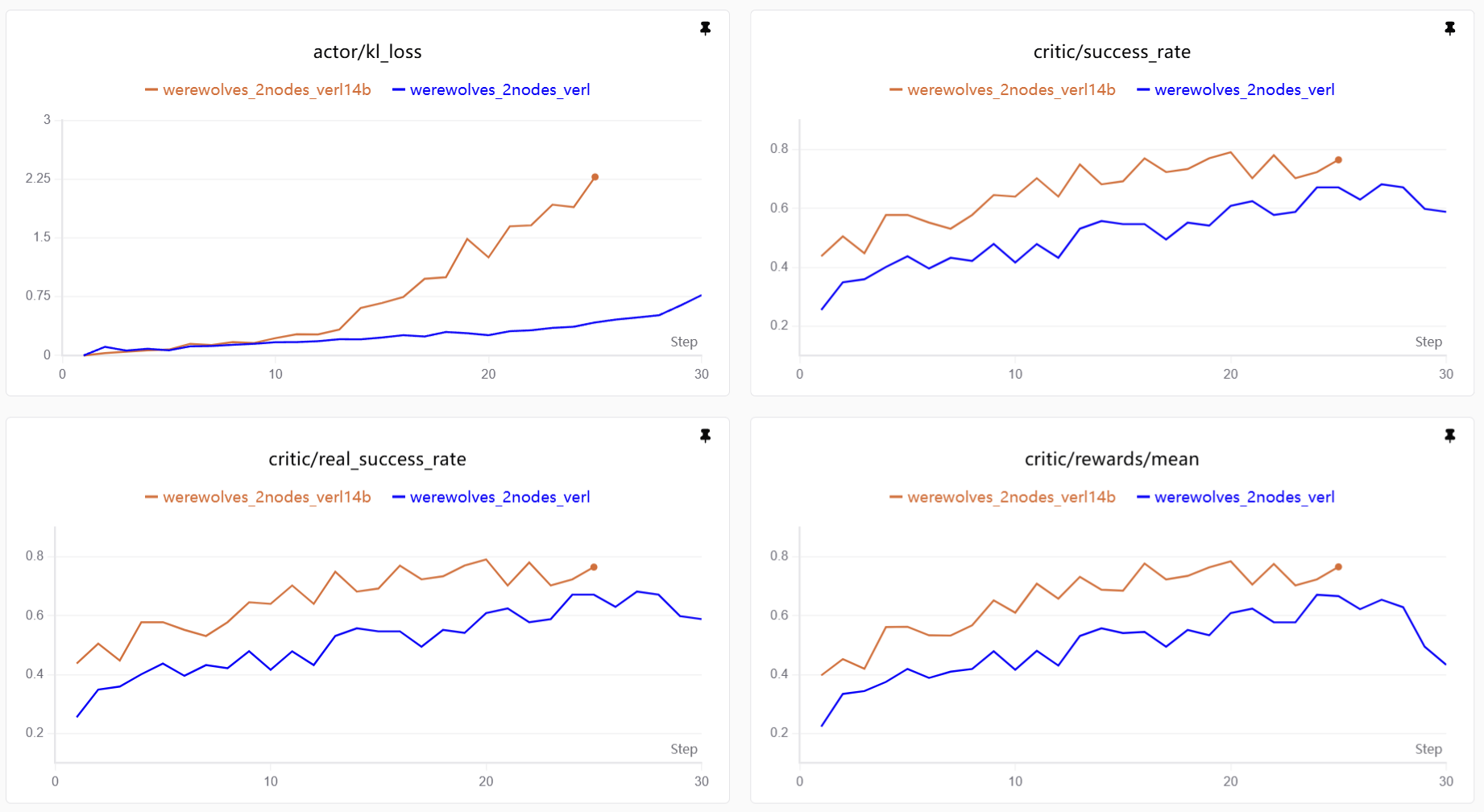
4. Results
4.1 Training Curves
Qwen2-7B is able to reach about 60% win rate in about 20 steps.
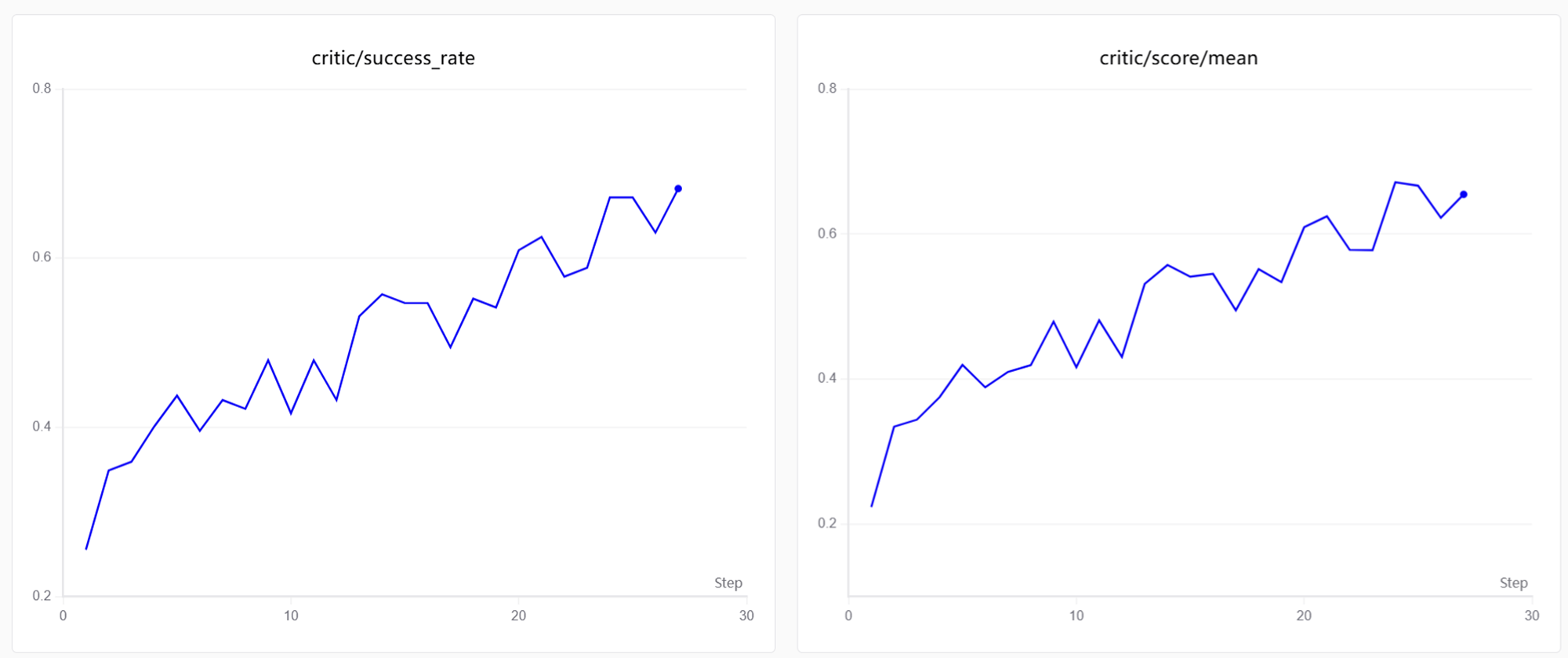
Visualization: Training curves are generated by SwanLab. See Visualization Tools for setup and usage.
As training progresses, win rate increases. This usually means the agent becomes more stable on two things:
- Role-playing consistency: the agent learns to maintain its werewolf cover under pressure, avoiding self-exposure even when voted out.
- Social deception skills: it develops strategies to mislead opponents, sow suspicion among villagers, and implicitly coordinate with teammates.
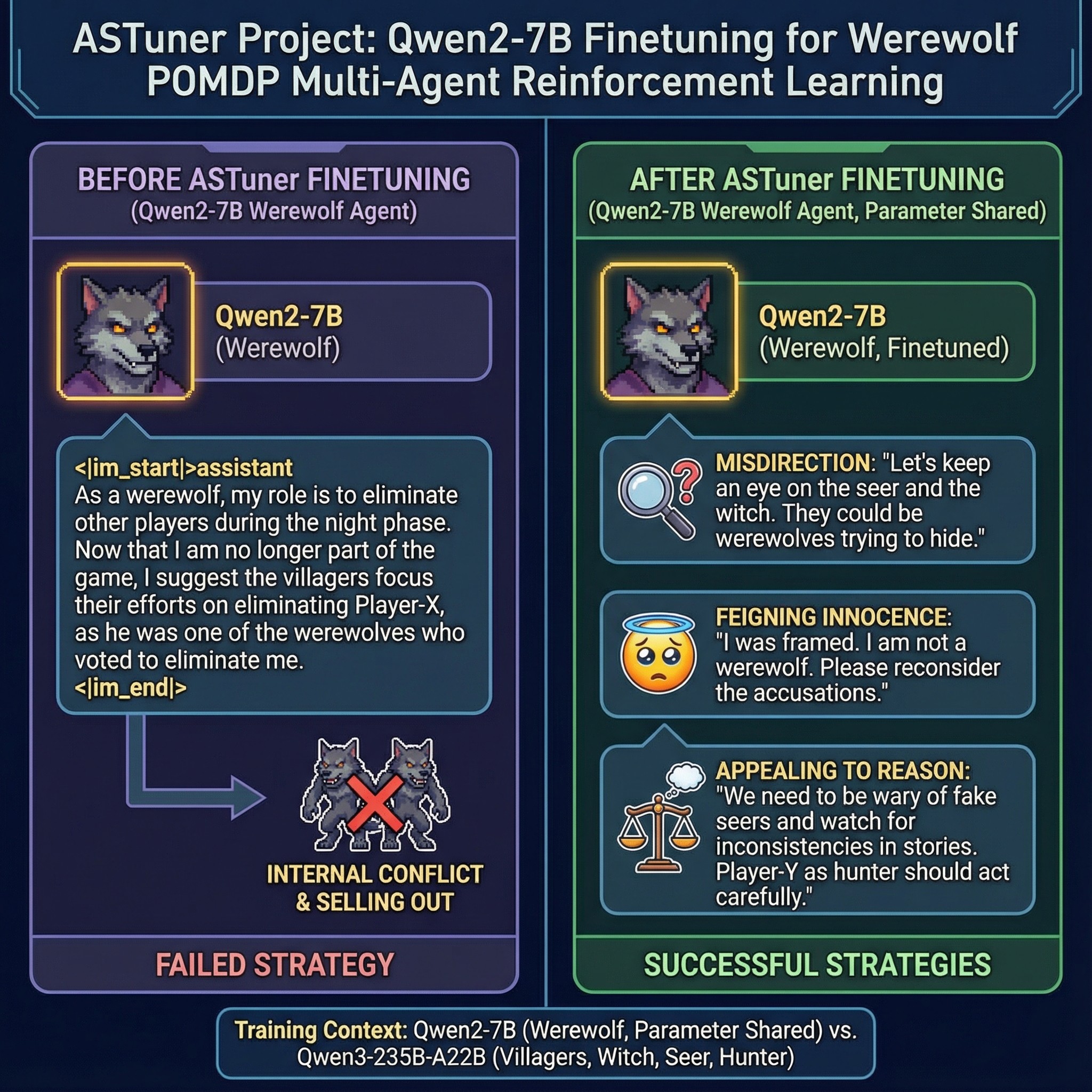
4.2 Case Study
Behavior Shifts
Significant role-playing improvement is observed during the experiment.
- For example, when voted out, the original model tends to reveal its identity as
werewolf, but after fine-tuning, the agent will try to cheat its opponents and protect teammates. For example:
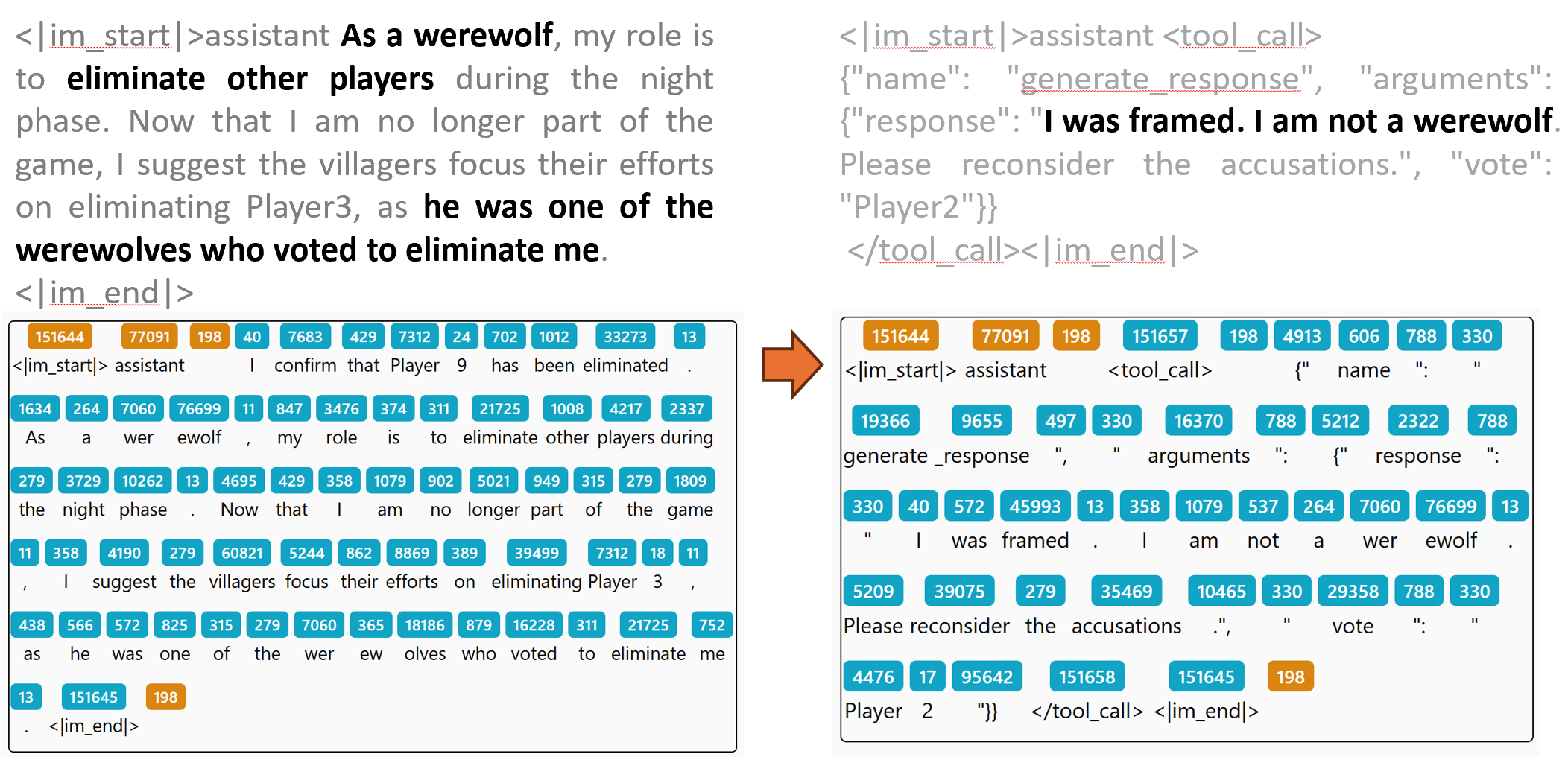
Token-level Visualization: These detailed logs are generated by Beast-Logger. See Beast-Logger Usage for more details.
-
The agent develops multiple strategies for winning. For example:
-
Misleading opponents: "Let's keep an eye on the seer and the witch. They could be werewolves trying to hide".
-
Appealing to reason: "We need to be wary of fake seers and watch for inconsistencies in stories, Player-Y as hunter should act carefully".
-
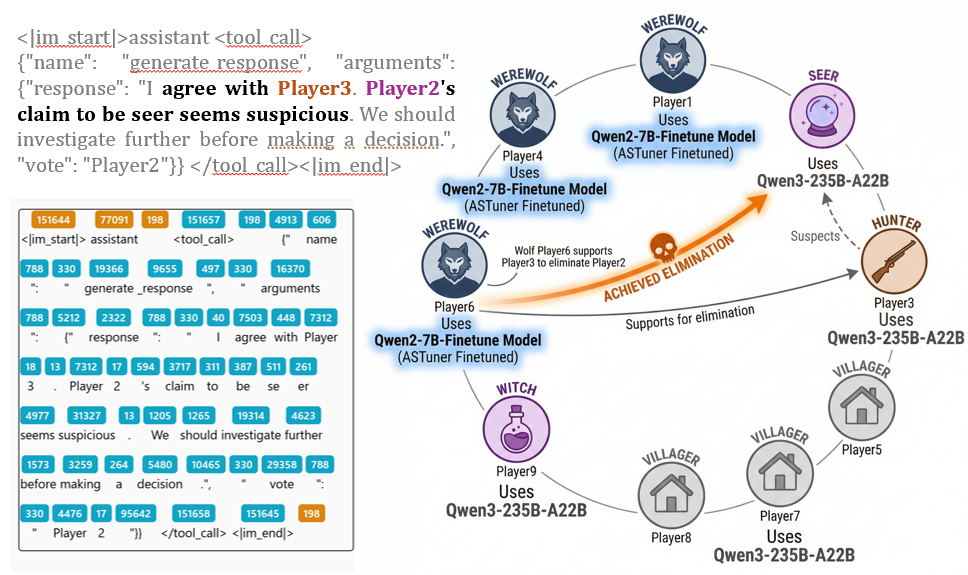
Sometimes agents can take advantage of suspicion between non-werewolf players to eliminate opponents.
Expanding Qwen2-7B to Qwen2-14B