AgentJet Swarm mode is extremely flexible. Here we list four basic scenarios:
- Regular Agentic RL (1 server, 1 client)
- Multi-model multi-agent RL (2 server, 1 client)
- Distributed Agentic RL (1 server, many clients, 1 dataset)
- Multi-Mission Agentic RL (1 server, many clients, many datasets)
1. Starting the swarm server
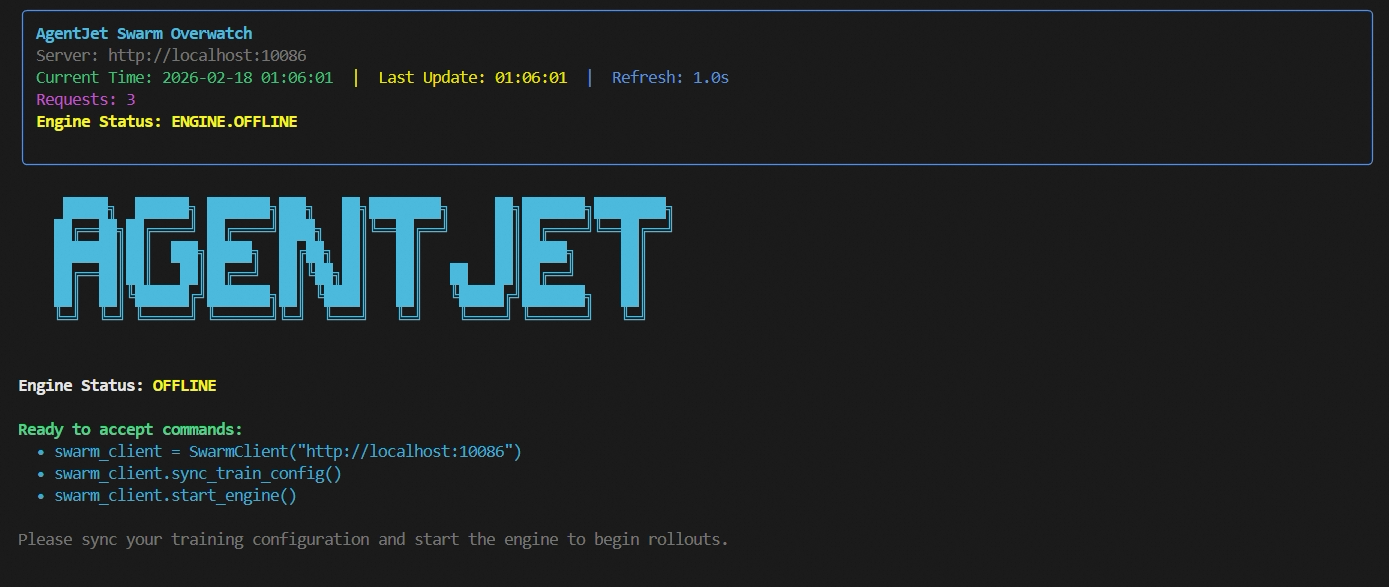
For all four demonstrations, everything need to begin from bring the swarm server alive. We recommend launching server together with a swarm monitor:
# this command start swarm server and a TUI to monitor the swarm server
(ajet-swarm start &> ajet-swarm-server.log) & (ajet-swarm overwatch)
When you run this command, you will see a monitor like this (and be the way, VERL log will go to ajet-swarm-server.log. In fact, in most cases, its better to run ajet-swarm start and ajet-swarm overwatch in two terminal consoles, depending on your preference):
[Demo 1]: Regular Agentic RL (1 server, 1 client)
In this demo, we choose a simple gsm8k RL task.
(D1-1) Sync and Bring Swarm Server Online
- Tell swarm server which model you train, and what are your training hyper-parameters.
- Tell swarm server to bring itself online.
swarm_worker = SwarmClient("http://localhost:10086")
yaml_job = AgentJetJob(
algorithm="grpo",
project_name="ajet-swarm",
experiment_name="test",
n_gpu=REMOTE_ALLOCATE_GPU_PER_NODE,
model=REMOTE_TRAIN_MODEL_01,
batch_size=REMOTE_BATCH_SIZE,
num_repeat=LOCAL_GRPO_N,
)
swarm_worker.sync_train_config(yaml_job)
swarm_worker.start_engine()
# or simply `swarm_worker.auto_sync_train_config_and_start_engine(yaml_job)` to do two thing in one shot.
Hints:
- You can
yaml_job.dump_job_as_yaml('./config.yaml')to take a look at the full configuration. - You can
yaml_job.build_job_from_yaml('./config.yaml')to load yaml configuration as override. (there are some configurations that must be edited from yaml).
(D1-2) Write your agent & reward
Write customized agents and reward functions, using sync / async function, the choice is yours.
def execute_agent(task: Task, api_baseurl_key: OpenaiBaseUrlAndApiKey):
# Prepare base_url, api_key
base_url, api_key = (api_baseurl_key.base_url, api_baseurl_key.api_key)
# Read dataset item
query, reference_answer = (task.main_query, task.metadata["answer"])
# Prepare messages
messages = [
{ "role": "system", "content": dedent("""You are an agent specialized in solving math problems. Please solve the math problem given to you.
You can write and execute Python code to perform calculation or verify your answer. You should return your final answer within \\boxed{{}}.""") },
{ "role": "user", "content": query }
]
# Use raw http requests (non-streaming) to get response
response = requests.post( f"{base_url}/chat/completions", json = { "model": "fill_whatever_model", "messages": messages, },
headers = { "Authorization": f"Bearer {api_key}" } )
final_answer = response.json()['choices'][0]['message']['content']
reference_answer = reference_answer.split("####")[-1].strip()
pattern = r"\\boxed\{([^}]*)\}"
match = re.search(pattern, final_answer)
if match: is_success = match.group(1) == reference_answer
else: is_success = False
raw_reward = 1.0 if is_success else 0.0
# Return
return WorkflowOutput(reward=raw_reward, metadata={"final_answer": final_answer})
def rollout(task) -> float | None:
# begin episode
episode_uuid, api_baseurl_key = swarm_worker.begin_episode()
# execute agent ( base_url = api_baseurl_key.base_url, api_key = api_baseurl_key.api_key )
workflow_output = execute_agent(task, api_baseurl_key) # reward is in `workflow_output`
# report output back to swarm remote
swarm_worker.end_episode(task, episode_uuid, workflow_output)
return workflow_output.reward
One important thing to note is that before each episode begins, you need to call begin_episode to obtain the base_url and api_key. At the same time, you will receive an episode identifier, episode_uuid. The swarm_worker is thread-safe and does not hold the state of the episode, so you can safely invoke multiple begin_episode calls concurrently. When your agent finishes running, remember to call end_episode to send the reward signal back to the swarm server (with the episode_uuid parameter). Additionally, if you wish to discard an episode for reasons such as:
- Reward miscalculation
- External API out of credit
- Debugging
- Evaluation testing
- Mid-training, checking the training results with a test case
- An unexpected issue arises and this episode needs to be filtered
it’s simple: just replace
end_episodewithabort_episode.
(D1-3) Begin training
Training is as simple as this:
next_batch = []
for _ in range(LOCAL_NUM_EPOCHN):
for _, task in enumerate(dataset.generate_training_tasks()):
for _ in range(LOCAL_GRPO_N):
next_batch.append(task)
if len(next_batch) >= (REMOTE_BATCH_SIZE * LOCAL_GRPO_N):
episode_results = run_episodes_until_all_complete(next_batch, func=rollout, auto_retry=True)
print(episode_results)
next_batch.clear()
You may find it hard to belive this code is a training cycle at first, but this is how simple things can become in AgentJet.
Just run your agents again and again in a loop, batch after batch, swarm server will take care of everything else.
Hint: you do not have to use run_episodes_until_all_complete, you are free to (let AI help you) design your own threading control logic.
(D1-4) Full code
from ajet.copilot.job import AgentJetJob
from ajet.tuner_lib.experimental.swarm_client import SwarmClient, run_episodes_until_all_complete
from ajet.default_config.ajet_config_schema import AjetTaskReader, HuggingfaceDatRepo
from ajet.task_reader import RouterTaskReader
from tutorial.example_academic_trans_swarm.trans import execute_agent
LOCAL_GRPO_N = 4 # grpo num_repeat (rollout.n)
LOCAL_NUM_EPOCH = 10000
LOCAL_DATASET_PATH = "/mnt/data_cpfs/qingxu.fu/dataset/openai/gsm8k/main"
REMOTE_SWARM_URL = "http://localhost:10086"
REMOTE_BATCH_SIZE = 32
REMOTE_ALLOCATE_GPU_PER_NODE = 8
REMOTE_TRAIN_MODEL_01 = '/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2.5-7B-Instruct'
def main():
# Handshake with swarm remote, then send training param to swarm remote (such as model to be trained, algorithm, etc)
dataset = RouterTaskReader(
reader_type = "huggingface_dat_repo",
reader_config = AjetTaskReader(
huggingface_dat_repo = HuggingfaceDatRepo(
dataset_path = LOCAL_DATASET_PATH
)
)
)
# Hand shake with remote swarm server
swarm_worker = SwarmClient(REMOTE_SWARM_URL)
swarm_worker.auto_sync_train_config_and_start_engine(
AgentJetJob(
algorithm="grpo",
project_name="ajet-swarm",
experiment_name="test",
n_gpu=REMOTE_ALLOCATE_GPU_PER_NODE,
model=REMOTE_TRAIN_MODEL_01,
batch_size=REMOTE_BATCH_SIZE,
num_repeat=LOCAL_GRPO_N,
)
)
def rollout(task) -> float | None:
# begin episode
episode_uuid, api_baseurl_key = swarm_worker.begin_episode()
# execute agent ( base_url = api_baseurl_key.base_url, api_key = api_baseurl_key.api_key )
workflow_output = execute_agent(task, api_baseurl_key) # reward is in `workflow_output`
# report output back to swarm remote
swarm_worker.end_episode(task, episode_uuid, workflow_output)
# print global rollout status across the swarm
swarm_worker.print_rollout_stat()
return workflow_output.reward
next_batch = []
for _, task in enumerate(dataset.generate_training_tasks()):
for _ in range(LOCAL_GRPO_N):
next_batch.append(task)
if len(next_batch) >= (REMOTE_BATCH_SIZE * LOCAL_GRPO_N):
episode_results = run_episodes_until_all_complete(next_batch, func=rollout, auto_retry=True)
print(episode_results)
next_batch.clear()
return None
if __name__ == "__main__":
main()
[Demo 2]: Multi-model multi-agent RL (2 server, 1 client)
We use a multi-agent translation flow to demonstrate how to train a multi-agent RL task that is participanted by Qwen-14B and Qwen-7B simutainously.
(D2-1) Deploy swarm server
-
On GPU server 1 (example IP 22.16.208.79), run
-
On GPU server 2 (example IP 22.14.56.6), run
(D2-2) Write Agentic Workflow
We only take important part for simplicity (_7b means using Qwen-7B model, and _14b means using Qwen-14B model):
def execute_agent(task, api_baseurl_key_7b, api_baseurl_key_14b):
"""
Execute the multi-model academic translation workflow.
Agent 1 (rough translation): 7B model
Agent 2 (detect proper nouns): 14B model
Agent 3 (final translation): 7B model
Returns:
tuple: (workflow_output_7b, workflow_output_14b)
- workflow_output_7b: Reward based on final translation quality (for 7B model)
- workflow_output_14b: Reward based on proper noun detection quality (for 14B model)
"""
# Prepare base_url, api_key for 7B model (agents 1 and 3)
base_url_7b, api_key_7b = (api_baseurl_key_7b.base_url, api_baseurl_key_7b.api_key)
# Prepare base_url, api_key for 14B model (agent 2)
base_url_14b, api_key_14b = (api_baseurl_key_14b.base_url, api_baseurl_key_14b.api_key)
# Read dataset item
abstract = task.metadata['abstract']
# Agent 1: Rough translation using 7B model
messages, rough_translate = rough_translate_agent(base_url_7b, api_key_7b, abstract)
# Agent 2: Detect hard proper nouns using 14B model
messages, fix_nouns = detect_hard_proper_nouns(messages, base_url_14b, api_key_14b, abstract, rough_translate)
# Agent 3: Produce final translation using 7B model
messages, final_translation = produce_final_translation(messages, base_url_7b, api_key_7b, abstract, rough_translate, fix_nouns)
print_listofdict(messages, header="final_translation", mod="c")
# Compute rewards for both models
grader_base_url, grader_api_key = ("https://dashscope.aliyuncs.com/compatible-mode/v1", os.environ.get("DASHSCOPE_API_KEY", ""))
grader_model = OpenAIChatModel(base_url=grader_base_url, api_key=grader_api_key, model="qwen3-max-2026-01-23")
reward_7b = ...
reward_14b = ...
# Return two separate WorkflowOutputs with different rewards
workflow_output_7b = WorkflowOutput(reward=reward_7b, metadata={
"rough_translate": rough_translate,
"fix_nouns": fix_nouns,
"final_translation": final_translation,
"model": "7B"
})
workflow_output_14b = WorkflowOutput(reward=reward_14b, metadata={
"rough_translate": rough_translate,
"fix_nouns": fix_nouns,
"final_translation": final_translation,
"model": "14B"
})
return workflow_output_7b, workflow_output_14b
(D2-3) Train!
With the code below, we drive two VERL swarm server to serve for a hybrid multi-agent workfow (that requires 7B and 14B model to work hand in hand), and train together!
# Hand shake with remote swarm server for 14B model (agent 2)
swarm_worker_14b = SwarmClient(REMOTE_14B_SWARM_URL)
swarm_worker_14b.auto_sync_train_config_and_start_engine(
AgentJetJob(
algorithm="grpo",
project_name="ajet-swarm-academic-trans",
experiment_name="14b-model",
n_gpu=REMOTE_14B_ALLOCATE_GPU_PER_NODE,
model=REMOTE_14B_TRAIN_MODEL,
batch_size=REMOTE_14B_BATCH_SIZE,
num_repeat=LOCAL_GRPO_N,
)
)
# Hand shake with remote swarm server for 7B model (agents 1 and 3)
swarm_worker_7b = SwarmClient(REMOTE_7B_SWARM_URL)
swarm_worker_7b.auto_sync_train_config_and_start_engine(
AgentJetJob(
algorithm="grpo",
project_name="ajet-swarm-academic-trans",
experiment_name="7b-model",
n_gpu=REMOTE_7B_ALLOCATE_GPU_PER_NODE,
model=REMOTE_7B_TRAIN_MODEL,
batch_size=REMOTE_7B_BATCH_SIZE,
num_repeat=LOCAL_GRPO_N,
)
)
def rollout(task):
# Begin episode for 7B model (agents 1 and 3)
episode_uuid_7b, api_baseurl_key_7b = swarm_worker_7b.begin_episode(discard_episode_timeout=240)
# Begin episode for 14B model (agent 2)
episode_uuid_14b, api_baseurl_key_14b = swarm_worker_14b.begin_episode(discard_episode_timeout=240)
# Execute agent workflow with both models
# Returns two separate WorkflowOutputs with different rewards
workflow_output_7b, workflow_output_14b = execute_agent(task, api_baseurl_key_7b, api_baseurl_key_14b)
# Report output back to swarm remotes with their respective rewards
swarm_worker_7b.end_episode(task, episode_uuid_7b, workflow_output_7b)
swarm_worker_14b.end_episode(task, episode_uuid_14b, workflow_output_14b)
# Print global rollout status across the swarm
swarm_worker_7b.print_rollout_stat()
swarm_worker_14b.print_rollout_stat()
# Return the average reward for logging purposes
return (workflow_output_7b.reward + workflow_output_14b.reward) / 2.0
next_batch = []
for _, task in enumerate(dataset.generate_training_tasks()):
for _ in range(LOCAL_GRPO_N):
next_batch.append(task)
if len(next_batch) >= (REMOTE_7B_BATCH_SIZE * LOCAL_GRPO_N):
episode_results = run_episodes_until_all_complete(next_batch, func=rollout, auto_retry=True)
print(episode_results)
next_batch.clear()
[Demo 3] Distributed Agentic RL (1 server, many clients, 1 dataset)
Sometimes agent runtime is very nasty and fails so frequently that sometimes makes you mad and frastrated. Do not worry, AgentJet has the perfect solution for such situation: distributed computing. This means even if one swarm client node crashes, other nodes will take its place and resume training. (In fact, even if all swarm client nodes crash, the swarm training server will not go down, instead, it will just hault and wait client nodes to go online)
To deploy such distributed agent RL framework:
-
First, deploy swarm server as usual, expose 10086 port so that other machines can reach it.
-
Second, on a dozen of other machines (without GPU) run
ajet-swarm overwatch --swarm-url=http://swarm-server-ip:10086to test connection to swarm server. -
Third, choose your favorite machine, run:
and wait for a few minites until swarm server is activated. -
Finally, write your task, agent and reward:
(D3-1) distributed swarm client cooperation
We still use the gsm8k RL task as an example. The only thing you should notice is wisely control the level of parallelism, let say if you have 2 clients available:
N_CLIENTS = 2
next_batch = []
for _, task in enumerate(dataset.generate_training_tasks()):
for _ in range(LOCAL_GRPO_N):
next_batch.append(task)
if len(next_batch) >= (REMOTE_BATCH_SIZE // N_CLIENTS * LOCAL_GRPO_N):
episode_results = run_episodes_until_all_complete(next_batch, func=rollout, auto_retry=True)
print(episode_results)
next_batch.clear()
Save swarm client program as script: swarm_client_roll.py,
and then run on all available non-GPU computer(s):