Swarm Intro (ZH)
分布式多智能体 LLM 蜂群训练框架 AgentJet。
中心化 Agentic RL 大模型的困境
在过去的2025年,我们见证了大语言模型Agent的飞速发展, 而随着LLM智能体以及配套工具和运行时越来越复杂,无论是agent开发者还是前沿llm强化学习研究者都会遇到各种苦恼问题:
- 还没来得及庆祝Agent训练效果初见成色,结果某个外部API余额意外耗尽导致训练中止;
- 只是简单地修改了一下奖励,却需要等待训练重启等到地老天荒,而且上个检查点(checkpoint)后未保存的进度都丢失了;
- 某Agent需要docker作为运行时,但因权限不足,无权启动其他容器,只能花大量时间修改Agent源码寻找workaround;
- MCP工具故障(浏览器MCP工具被封IP地址,数据库MCP工具因意外硬盘爆满故障);
- 远程连接服务器调试Agent很不方便,如果能在自己的笔记本电脑上运行 Agent 直接参与(全参)Agent RL训练该多好呀;
当太多的精力被浪费在Agent运行时的稳定性上,我们越来越难去做出一些现有框架桎梏下,被视为“大胆”的算法尝试:
- 为何多智能体任务中我们不能同时去训练不同大小的模型高低搭配,做非参数共享的多智能体RL训练?
- 如果让一个较小的模型在每个Gradient Step同时学习多个完全不同Agent工作流(Workflow),甚至完全不同领域的任务,是否有可能表现得更好?
- 为什么鲜有研究使用 opencode 等带复杂 Runtime 的复杂 Agent 直接进行训练?
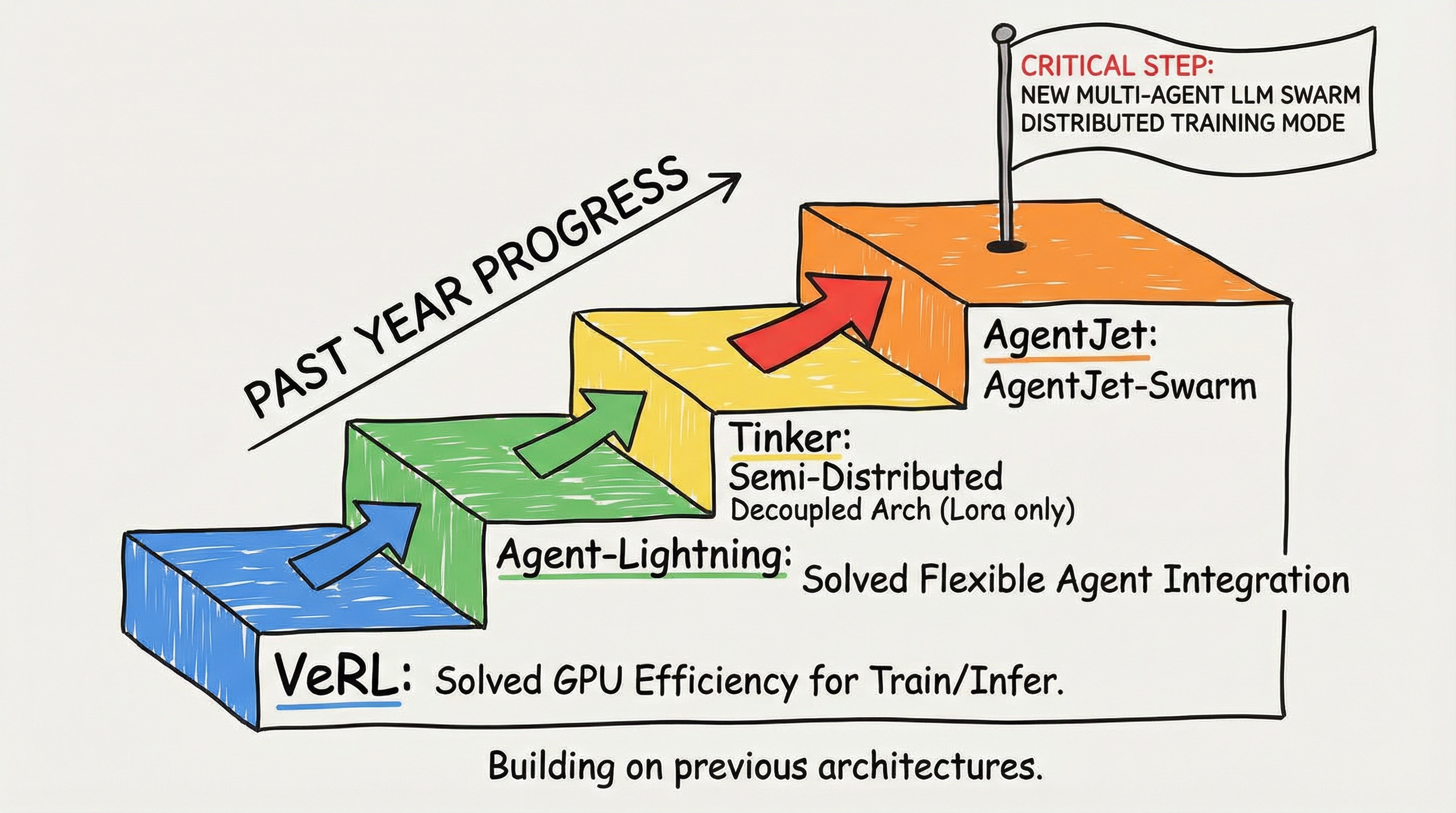
有困难就总会有解决方法。在过去的一年中,VERL解决了训推GPU效率的问题,Agent-Lightning解决了灵活接入自定义智能体的问题, Tinker提出了一个半分布式解耦架构(可惜只能训练Lora模型)。而通义EconML团队,AgentJet在充分学习这些项目架构的基础上,走出了关键一步: 我们提出了一种全新的多智能体LLM蜂群分布式训练模式, 在这一框架中, 一方面支持任意多的swarm-server节点承载任意多的模型(如7B + 14B + 32B)提供VLLM(SGLang)推理 + 策略梯度更新, 另一方面支持任意多的swarm-client节点承载任意Agent工作流和任意的Agent运行时。
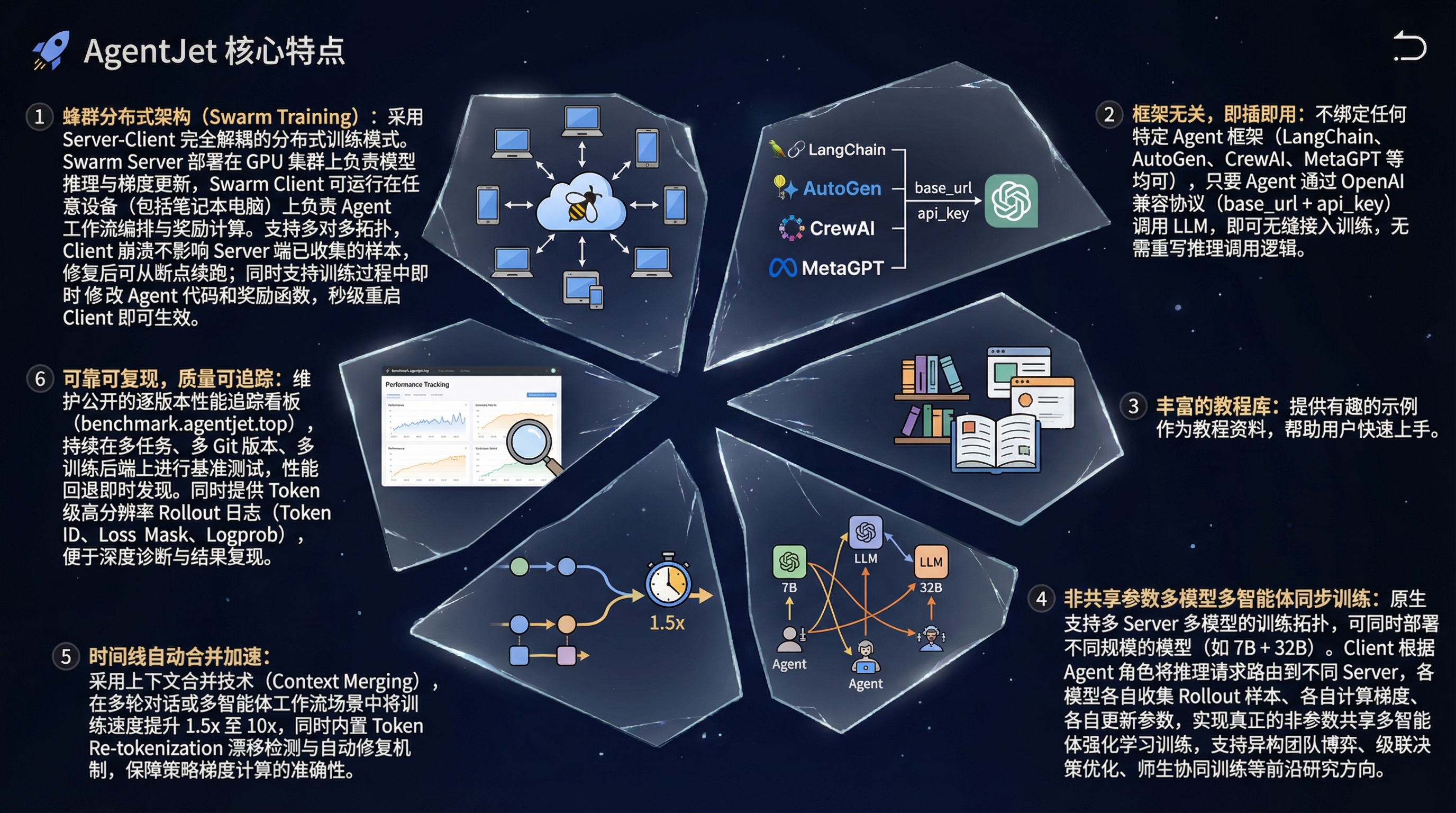
AgentJet Swarm: 首个开源的蜂群分布式大模型 Agent 训练框架
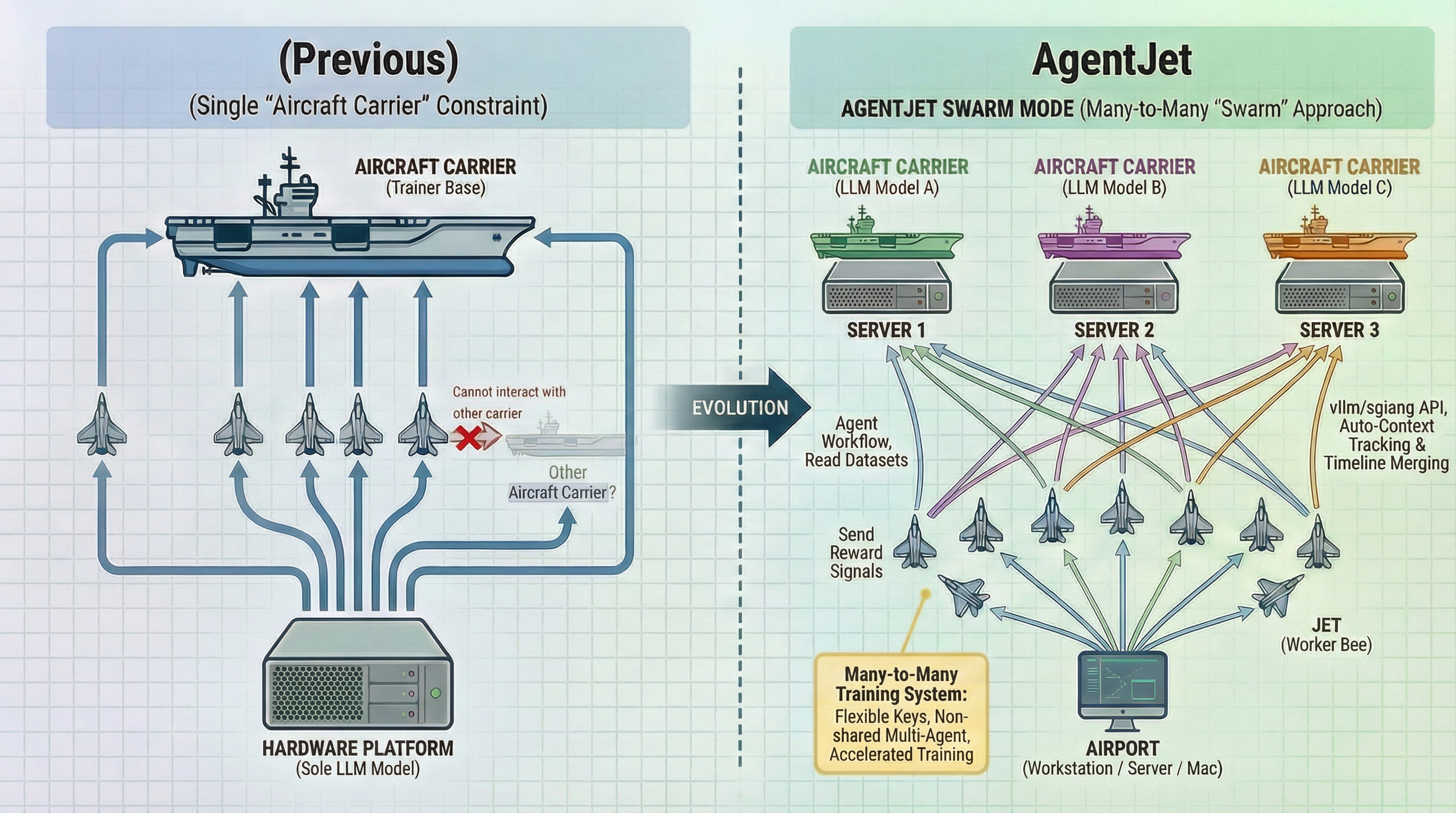
在以往的训练模式下,VERL支撑的训练基座可以比作“航空母舰”,从“母舰”上,只能起飞轻型的“Jet”作为Agent运行的载体,且所有Jet与“母舰”强绑定, 即无法使用其他“母舰”的其他模型实现非共享参数多智能体训练,也不能方便地切换固定在环境变量和代码中的密钥和奖励参数,更不能在多个硬件之间随心流转。一旦遇到任何问题,只能终止整个进程返回到上一检查点。
而AgentJet Swarm蜂群训练模式开创了一种全新的训练模式。沿用前面的比喻,在蜂群模式下,研究者和Agent工程师可以自由地在一台或多台服务器上部署多艘“航空母舰”(Swarm Server,每个Server对应一个待训LLM模型)。 然后从“陆基平台”(例如你的工作站、服务器、甚至是你的Macbook,对于硬件、操作系统、智能体Runtime都没有任何限制)上 “起飞” 任意多个 Swarm Client 运行Agent工作流,形成一个多对多的训练体系:
- Swarm Client:负责读取数据集,运行Agent工作流,最后奖励信号返回给各个“母舰”。
- Swarm Server:“母舰”负责维护训练推理CoLocate环境,提供vLLM/SGLang的api接口(附带AgentJet的自动context追踪 & 时间线合并能力,大幅加速训练),采集&归纳样本,并执行策略梯度计算。
接下来,用简单的几个case展示 AgentJet 蜂群模式的优势:
用笔记本电脑全参训练Agentic LLM模型
没错,在 AgentJet 蜂群模式下,你的笔记本电脑完全可以成为一个完美 Swarm Client。想象这样一个场景:你的团队在远程GPU集群上部署了一个 Swarm Server,挂载着一个 Qwen-32B 模型。此时打开你的 Laptop,写好你需要训练的Agent Loop,指定数据集路径、模型路径和奖励函数,调试和训练就可以开始了。
你的笔记本(或工作站、阿里云ECS等,不需要GPU)只负责运行Agent工作流的逻辑编排:读取数据集、调用远程 Swarm Server 的推理接口(Base Url + Api Key)获取模型输出、执行工具调用、计算奖励,然后将结果回传给 Swarm Server。
另一方面所有的重活(模型推理、梯度计算、参数更新)全部由远端的 GPU 集群完成。
这意味着什么?Agent 开发者和大模型研究者不再需要清晰地区分“推理”和“训练”之间的界限, 也不再需要在专门的训练链路中艰难地调试工作流。你完全可以在本地用你最熟悉的 IDE 编写和修改 Agent 逻辑。 在不终止训练的情况下,你还可以随时实现对智能体代码与奖励参数的即时修改。 例如当需要修改奖励时,只需要修改代码后,只需要杀死运行旧Swarm Client进程重启即可。 (Swarm Server会自动清理之前 Swarm Client 留下的数据残骸。)
由于 AgentJet 蜂群模式实现了智能体代码与奖励修改在训练系统中的即时反馈, 你甚至可以直接让Claude Code或者Cursor等先进编程辅助工具 接管 Agent Loop 编写+调试+训练的全部流程,编写http命令遥控调整 Swarm Server 的训练参数。
| 特征 | Tinker | AgentJet-Swarm |
|---|---|---|
| 开源性质 | ❌ 闭源 | ✅ 开源免费 |
| 收费模式 | 付费服务 | ✅ 完全免费 |
| 任务 | 各种 LLM 训练 | 专精 Agent RL训练 |
| 架构模式 | 托管服务 + 单点客户端 API | ✅ 服务器和客户端都可按需拓展 |
| 多客户端共同参与训练 | ❌ 不支持 | ✅ 支持 |
| 训练方式 | 仅限 LoRA 微调 | ✅ 全量 LLM 模型训练 |
| 最大模型规模 | Llama 70B、Qwen 235B | ✅ 取决于用户 GPU 集群配置 |
| 通信协议 | 专有 API | ✅ 专有API + OpenAI兼容API |
| 推理引擎后端 | 内置未知推理服务 | ✅ vLLM/SGLang任选 |

外部运行时崩溃,修好接着跑,一秒不耽误
这是 AgentJet 蜂群架构带来的最直观的工程收益之一。 不稳定的外部因素导致训练崩溃,或许已经成为了不少Agent强化学习研究者的集体记忆。 在传统的中心化训练框架中,Agent 运行时和训练循环是紧耦合的。一旦某个外部依赖出了问题。比如浏览器 MCP 工具被目标网站封禁了 IP、代码沙箱的 Docker 容器因 OOM 被 kill、甚至只是某个第三方 API 的 Rate Limit 触发了,整个训练进程就有概率会崩溃。 接下来就不得不从上一个 checkpoint 重新加载,丢失所有未保存的 rollout 数据,然后祈祷下次运气好一点。
AgentJet Swarm 从架构层面根治了这个问题。由于 Swarm Client 和 Swarm Server 是完全解耦的独立进程,Client 的崩溃对 Server 来说只是"少了一个数据供给者",Server 会继续等待其他 Client 的数据,或者耐心等待故障 Client 恢复。
具体而言:
- Client 崩溃:Server 端已收集到的 rollout 样本不会丢失,它们安全地存储在 Server 的样本缓冲区中。你只需要修复问题(换个 IP、重启 Docker、充值 API 余额),然后重新启动 Client,它会自动从断点处继续提交新的 rollout。
- 部分任务失败:即使一个 batch 中有部分任务因运行时故障而失败,AgentJet 会优雅地跳过这些失败样本,用已成功完成的样本继续梯度更新,不会浪费任何有效计算。
对于那些依赖复杂外部环境的 Agent 训练任务(网页浏览、终端操作、数据库交互),这种容错能力不是锦上添花,而是刚需。
修工作流BUG?调试奖励?10秒获取 Traceback
AgentJet 做到了真正意义上的训练、推理、调试三位一体。在传统框架下,调试一个 Agent 工作流的奖励函数是一件令人崩溃的事情。你修改了一行奖励计算逻辑,然后需要:重新启动整个训练脚本 → 等待模型加载(几十秒到几分钟)→ 等待 vLLM 引擎初始化 → 等待第一个 rollout 完成 → 终于看到报错信息。整个循环可能需要 5-10 分钟,而你可能只是写错了一处缩进。
在蜂群模式下,这个痛点被彻底消除。因为 Swarm Client 是一个轻量级的纯 CPU 进程,它不需要加载任何模型权重,启动时间在秒级。你的调试循环变成了:
- 在 IDE(VS Code、Cursor 等)中修改工作流代码或奖励函数
- 重启 Swarm Client(约 2-3 秒)
- Client 立即连接到已经在运行的 Swarm Server,开始执行新的 rollout
- 几秒内看到结果或 traceback
这意味着你可以像开发普通 Python 项目一样开发 Agent 训练流程——设断点、看变量、单步执行。整个 Client 端就是普通的 Python 代码,没有Ray也没有任何其他分布式训练框架的“黑魔法”。Cursor、Claude Code 这些 AI 编程助手也可以直接参与你的 Agent 训练开发并受益于 Agent 的即时输出反馈自动修复Bug。
多任务鸡尾酒训练:要同时RL训练40%数学任务、30%代码任务、30%终端任务,且Runtime完全不一样?没问题!
多任务混合训练是提升模型泛化能力的关键手段,但在实践中却困难重重。数学任务需要一个符号计算验证器,代码任务需要一个安全的 Docker 沙箱,终端任务需要一个完整的 Linux 环境和文件系统——这三种运行时的依赖、权限要求、安全策略完全不同,把它们塞进同一个训练进程既麻烦,还不安全。
AgentJet 蜂群模式天然地解决了这个问题。你只需要部署一个 Swarm Server 承载目标模型,然后在不同的机器(甚至不同的网络环境)上启动多个 Swarm Client,每个 Client 负责一类任务。接下来,可使用 AgentJet 提供的“节流器”实现不同任务的比例调节;也可以灵活地自定义训练逻辑,在训练过程中动态调配配比。 每个 Client 独立运行、独立容错,互不干扰。
这种架构还带来了一个额外的好处:资源隔离。代码沙箱需要 Docker 权限?给机器 B 配置就好,不影响其他 Client。浏览器 MCP 工具需要特殊的网络代理?只在对应的 Client 机器上配置。不同任务的安全边界和资源需求被自然地隔离开来。
单节点-多模型:一个Agent工作流两个异构模型一起训练?没问题,定义好奖励函数,即刻开始!
多智能体协作是 Agent 研究的前沿方向之一,但现有框架几乎都假设所有 Agent 共享同一个底层模型。这个假设在很多场景下是不合理的:一个负责高层规划的 Agent 可能需要一个 32B 的大模型来保证推理质量,而负责具体执行的 Agent 用一个 7B 的小模型就足够了。
AgentJet Swarm 原生支持多 Server 多模型的训练拓扑。你可以在多个GPU服务器上,同时启动多个 Swarm Server,每个 Server 承载不同大小的模型,然后用一个 Swarm Client 编排它们的协作:
在工作流中,Client 可以根据角色将不同的推理请求路由到不同的 Server。规划 Agent 的对话历史发送给 32B 模型,执行 Agent 的对话历史发送给 7B 模型。两个模型各自收集自己的 rollout 样本,各自计算梯度,各自更新参数,完成真正的非参数共享多智能体强化学习训练。
这种能力打开了许多此前难以实现的研究方向:
- 异构团队博弈:不同能力等级的模型组成团队,在竞争或合作环境中各自学习最优策略。
- 级联决策优化:粗粒度决策由大模型负责,细粒度操作由小模型执行,端到端联合优化整个决策链路。
- 师生协同训练:大模型做 teacher 提供高质量规划,小模型做 student 学习执行,两者同时通过 RL 信号共同进化。
基于VERL的高效训推 GPU CoLocate
AgentJet蜂群架构的灵活性并不以牺牲 GPU 利用效率 & 产生大量GPU空泡为代价。在 Swarm Server 内部,AgentJet 依然采用了经过实战检验的 VERL 训练推理 CoLocate 架构:这意味着推理(rollout generation)和训练(gradient update)共享同一组 GPU,避免了 GPU 显存的浪费。
对于熟悉 VERL 的研究者来说,几乎所有 VERL 实现的算法实现,都可无损地应用到 AgentJet 中。AgentJet 在此基础上增加了蜂群通信层和时间线合并优化,但核心的训练逻辑保持一致。迁移成本低,性能表现有保障。
不挑Agent框架,能支持OpenAI协议的BaseUrl和ApiKey就行
AgentJet 不绑定任何特定的 Agent 框架。无论你使用的是 LangChain、AutoGen、CrewAI、MetaGPT,还是自己手写的基于裸 HTTP 请求 Agent 逻辑,只要你的 Agent 通过 OpenAI 兼容的 API 协议(base_url + api_key)调用 LLM,就可以无缝接入 AgentJet 进行训练。
对于你的 Agent 代码来说,Swarm Server 和任何其他 OpenAI 兼容的推理服务没有任何区别。唯一的不同是,AgentJet 在背后默默地记录了完整的对话上下文和 token 级别的信息用于训练。
这意味着你可以直接拿现有的、已经调试好的 Agent 工作流进行 RL 训练,无需重写任何推理调用逻辑。甚至某些闭源Agent黑盒智能体,理论上只需要修改环境变量中的 base_url 和 api_key,就可以接入 AgentJet 进行训练。
稳定、可复现、逐版本性能追踪,无后顾之忧
对于一个训练框架而言,"能跑"只是最低要求,"跑得对"和"跑得稳"才是研究者真正关心的。 AgentJet 在工程质量上投入了大量精力,确保每一次训练结果都是可信赖的。
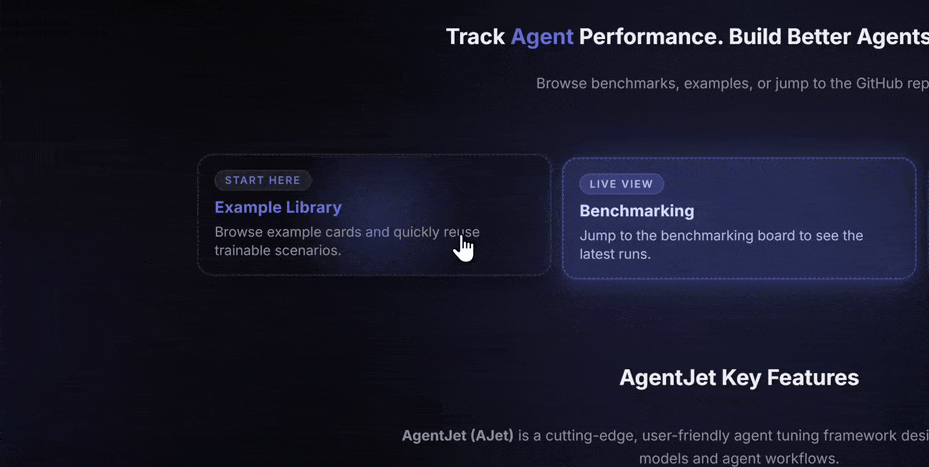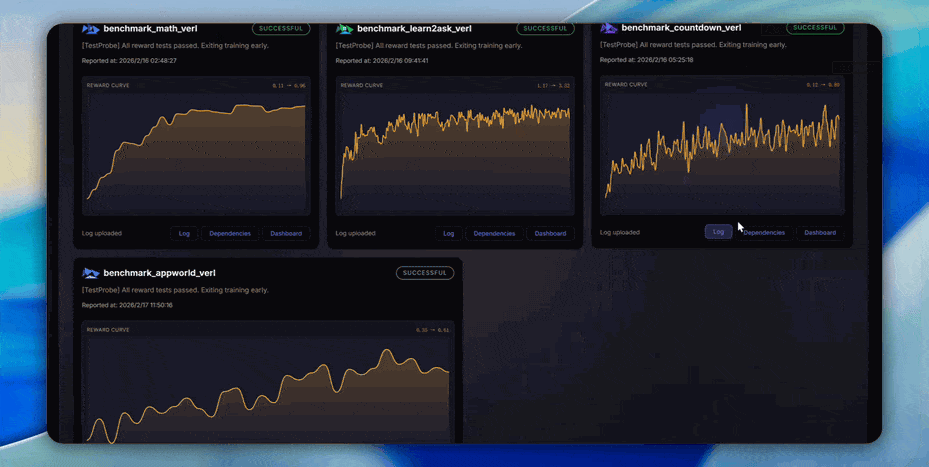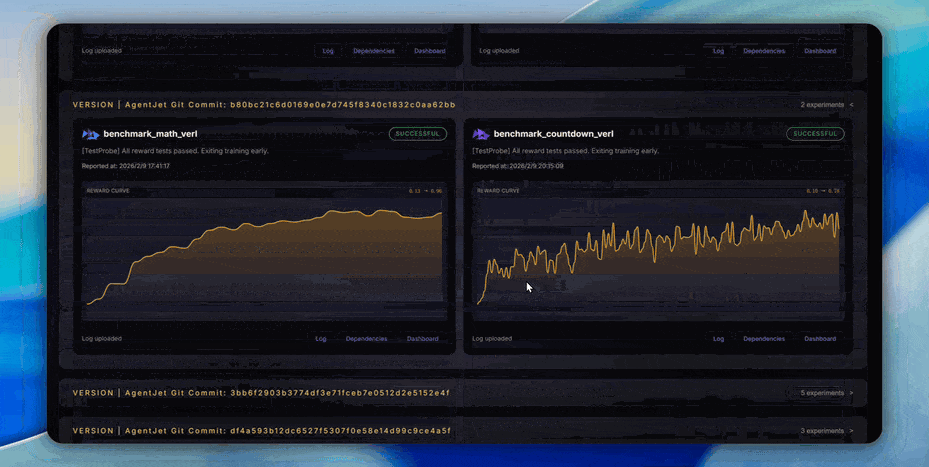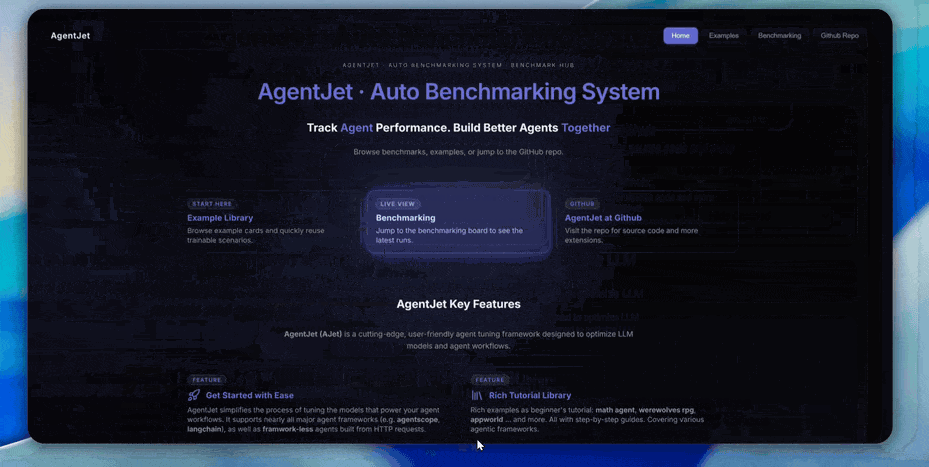
逐版本性能追踪: 我们维护了一个公开的 性能追踪看板,持续记录 AgentJet 在多项标准任务(数学推理、代码生成、工具使用等)上、跨主要 Git 版本、跨不同训练后端(VERL 等)的训练曲线和最终性能。每一次代码更新,测试机器人都会执行基准测试,任何性能回退都会被立即发现。这意味着: - 升级 AgentJet 版本时,可以明确知道新版本在你关心的任务上表现如何。 - 如果某次更新引入了隐性 bug 导致训练效果下降,我们会在第一时间捕获。 - 研究者可以放心地引用 AgentJet 的实验结果,因为它们是可复现的。
Token 一致性自动告警与修复:在 Agent 训练中,一个隐蔽问题是 token 漂移:同一段文本在推理和训练阶段可能被编码为不同的 token 序列,导致 logprob 计算错误,进而污染策略梯度计算的准确性。AgentJet 内置了自动 re-tokenization 漂移检测与修复机制,默认开启,在每个 rollout 样本进入训练管线前自动校验并修正 token 序列,杜绝这类问题。
高分辨率日志:当需要深入诊断训练行为时,AgentJet 提供 token 级别的 rollout 日志,记录每个 token 的 ID、loss mask 状态和 logprob 值。这些信息对于理解模型的学习动态、排查奖励信号异常、验证工作流逻辑的正确性至关重要。
实力派训练框架
作为一个 Agent 训练框架而言,仅仅实现一个分布式架构是远远不够的。如何提供稳定、秒上手、值得信赖的训练环境,也是我们需要研究的课题。 因此,AgentJet具备并开源提供这些核心硬实力:
- 丰富的教程库:提供有趣的 示例 作为教程资料。
- 时间线自动合并能力: 支持 多智能体工作流 并采用上下文合并技术,在多轮(或多智能体)对话场景中将训练加速 1.5x 到 10x。(类似于minimax forge技术报告中提到的“树形结构”处理能力。)
- 可靠可复现:我们持续跟踪框架在多项 不同任务 + 主要 Git 版本 + 不同训练后端 上的性能(数据持续汇总中),所见即所得,隐形Bug秒发现。
- Token一致性自动告警&修复:AgentJet默认情况下会自动根据 vLLM 引擎返回的 Token ID 进行 Re-tokenization 漂移修复。
- 多训练后端支持:支持包括 VERL 在内的多个训练后端,正着手支持 TRL 等其他训练后端。
总结与展望
AgentJet 蜂群训练框架的核心理念可以用一句话概括:让 Agent 训练的灵活性匹配 Agent 本身的复杂性。
当 Agent 的工作流越来越复杂、依赖的外部工具越来越多、涉及的模型越来越异构时,训练框架不应该成为瓶颈。AgentJet 通过将训练推理(Server)与 Agent 运行时(Client)彻底解耦,实现了:
- 开发者友好:在笔记本上用 IDE 调试 Agent 工作流,连接远端蜂群就能即刻训练。
- 工程鲁棒:外部运行时故障不影响训练进度,修复后无缝续跑。
- 算法灵活:多任务混合训练、异构多模型协同训练、动态数据配比调整,一切皆可配置。
- 性能可靠:继承 VERL 的高效 CoLocate 架构,辅以时间线合并加速技巧,以及逐版本性能追踪能力,确保结果可信。
我们相信,当训练框架不再是限制因素时,研究者和工程师可以将更多精力投入到真正重要的事情上——设计更好的 Agent 架构、探索更有效的奖励信号、尝试更大胆的多智能体协作策略。
AgentJet 已在 GitHub 上完全开源,欢迎社区的研究者和开发者试用、反馈和贡献。让我们一起推动 LLM Agent 训练进入蜂群时代。
项目地址:https://github.com/modelscope/AgentJet
性能看板:https://benchmark.agentjet.top/
官方文档:https://modelscope.github.io/AgentJet/