The Dilemma of Centralized Agentic RL Large Models
In 2025, we witnessed the rapid development of large language model agents. As LLM agents and their supporting tools and runtimes become increasingly complex, both agent developers and cutting-edge LLM reinforcement learning researchers encounter various frustrating problems:
- Just as agent training shows promising results, an external API balance unexpectedly runs out, causing training to halt
- A simple reward modification requires waiting ages for training to restart, losing all progress after the last checkpoint
- An agent needs Docker as runtime, but lacks permission to start other containers, forcing time-consuming workarounds in agent source code
- MCP tool failures (browser MCP tools get IP banned, database MCP tools fail due to unexpected disk space exhaustion)
When too much energy is wasted on agent runtime stability, it becomes increasingly difficult to make "bold" algorithmic attempts that existing frameworks consider constrained:
- Why can't we simultaneously train different-sized models in multi-agent tasks for non-parameter-sharing multi-agent RL training?
- If a smaller model learns multiple completely different agent workflows or even tasks from entirely different domains at each gradient step, could it perform better?
- Why is there little research using complex agents like OpenCode for direct training?
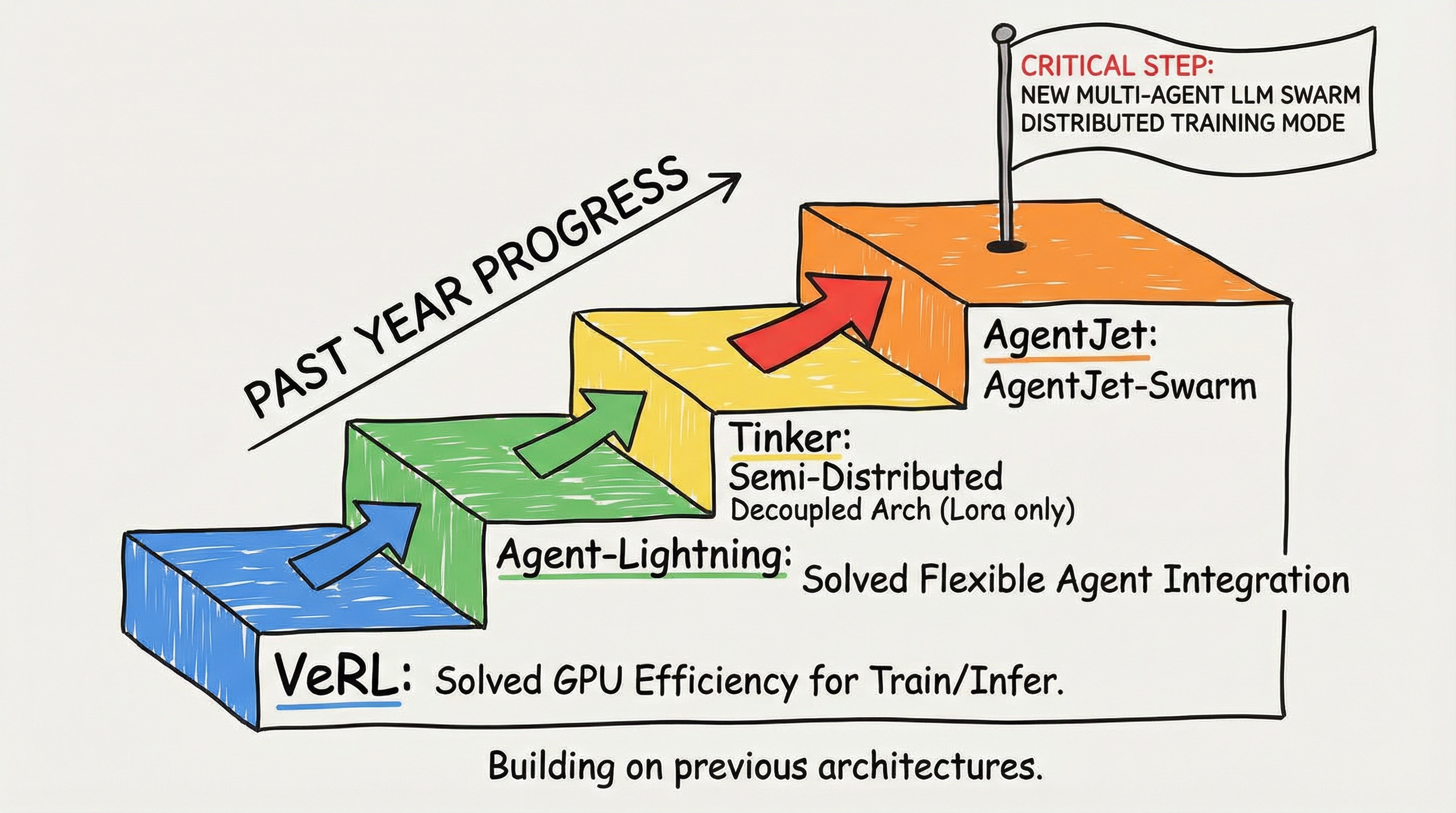
Where there are difficulties, there are always solutions. Over the past year, VERL solved GPU efficiency issues for training and inference, Agent-Lightning solved flexible integration of custom agents, and Tinker proposed a semi-distributed decoupled architecture (though limited to LoRA model training). The Tongyi EconML team's AgentJet, building on these project architectures, took a crucial step forward:
We propose a completely new multi-agent LLM swarm distributed training mode. In this framework, multiple swarm-server nodes support any number of models (like 7B + 14B + 32B) providing VLLM (SGLang) inference + policy gradient updates, while multiple swarm-client nodes support any agent workflows and any agent runtimes.
How great would it be to train LLM agents with full parameters on your laptop?
AgentJet Swarm: The First Open-Source Swarm Distributed Large Model Agent Training Framework
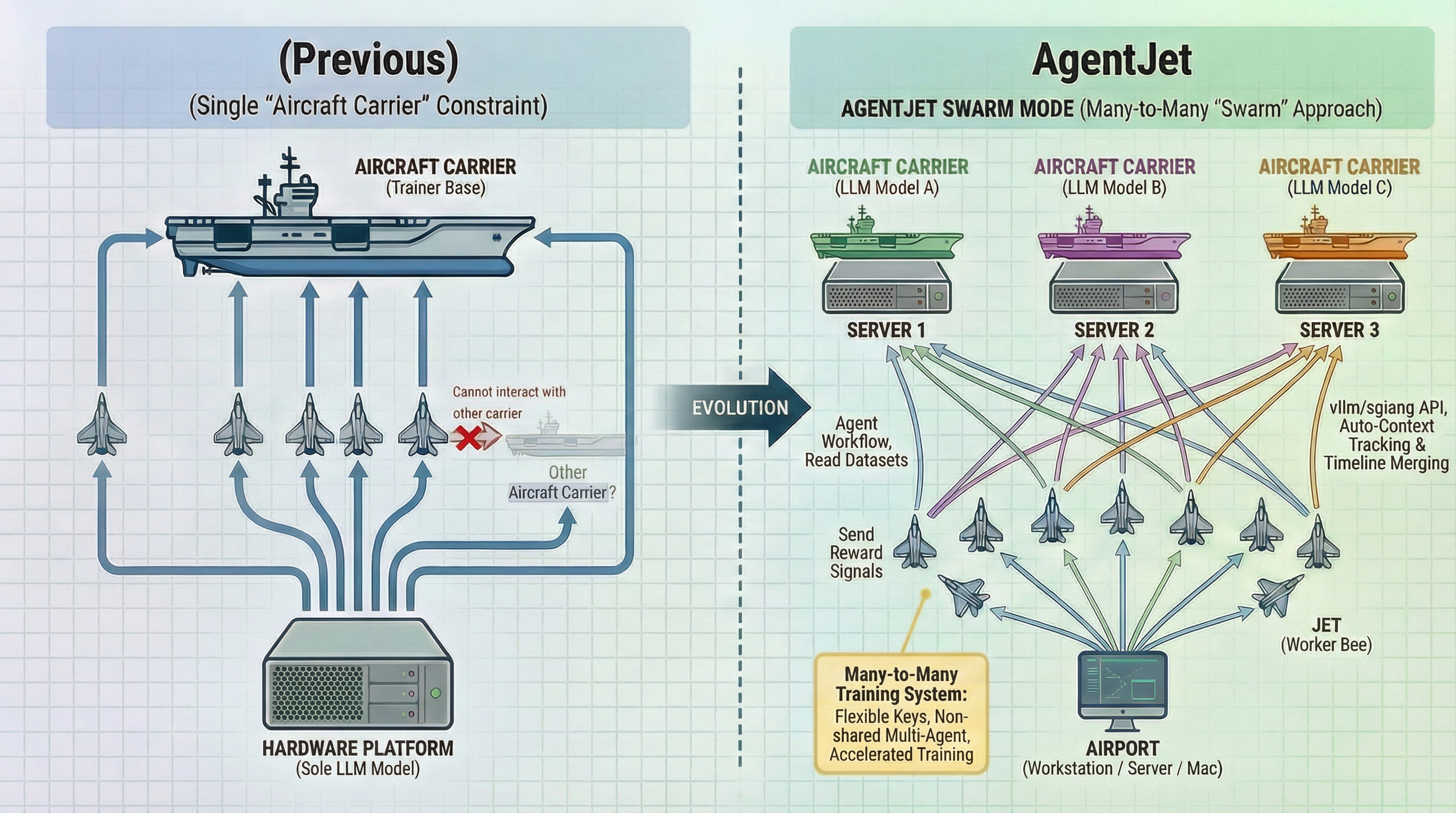
In previous training modes, VERL-supported training infrastructure resembled an "aircraft carrier," launching only lightweight "Jets" as agent execution vehicles from the "mothership." All Jets were tightly bound to the "mothership" - unable to use other models from different "motherships" for non-shared parameter multi-agent training, inconvenient switching of keys and reward parameters fixed in environment variables and code, and no free movement between multiple hardware setups. Any problem required terminating the entire process and returning to the previous checkpoint.
AgentJet Swarm pioneered a completely new training mode. Using the same metaphor, in swarm mode, researchers and agent engineers can freely deploy multiple "aircraft carriers" (Swarm Servers, each corresponding to a LLM model to be trained) on one or more servers. Then "launch" any number of Swarm Clients from "land-based platforms" (your workstation, server, or even MacBook) to run agent workflows, forming a many-to-many training system:
- Swarm Client: Reads datasets, runs agent workflows, and returns reward signals to various "motherships"
- Swarm Server: "Motherships" maintain training-inference CoLocate environments, provide vLLM/SGLang API interfaces (with AgentJet's automatic context tracking & timeline merging capabilities for significant training acceleration), collect & aggregate samples, and execute policy gradient computation
Next, let's demonstrate AgentJet swarm mode advantages with simple cases:
Full-Parameter Training of Agentic LLM Models on Laptops
Yes, in AgentJet swarm mode, your laptop can become a perfect Swarm Client. Imagine this scenario: your team deploys a Swarm Server on a remote GPU cluster, hosting a Qwen-32B model. Open your laptop, write the agent loop you need to train, specify dataset path, model path, and reward function - debugging and training can begin.
Your laptop (or workstation, Alibaba Cloud ECS, etc., no GPU needed) only handles agent workflow logic orchestration: reading datasets, calling remote Swarm Server inference interfaces (Base URL + API Key) for model outputs, executing tool calls, computing rewards, then sending results back to the Swarm Server.
All heavy lifting (model inference, gradient computation, parameter updates) is handled by the remote GPU cluster.
What does this mean? Agent developers and large model researchers no longer need to clearly distinguish between "inference" and "training," nor struggle with debugging workflows in specialized training pipelines. You can write and modify agent logic locally using your most familiar IDE. Without terminating training, you can achieve real-time modification of agent code and reward parameters. For example, when modifying rewards, simply change the code and restart the Swarm Client process after killing the old one. (Swarm Server automatically cleans up data remnants left by previous Swarm Clients.)
Since AgentJet swarm mode enables real-time feedback for agent code and reward modifications in the training system, you can even let advanced programming assistants like Claude Code or Cursor take over the entire process of Agent Loop writing + debugging + training, writing HTTP commands to remotely control Swarm Server training parameters.
External Runtime Crashes? Fix and Continue Without Missing a Beat
This is one of the most direct engineering benefits of AgentJet swarm architecture. Training crashes due to unstable external factors may have become a collective memory for many agent reinforcement learning researchers. In traditional centralized training frameworks, agent runtime and training loops are tightly coupled. Once an external dependency fails - browser MCP tools get IP banned by target websites, code sandbox Docker containers get killed due to OOM, or even just hitting a third-party API rate limit - the entire training process may crash. Then you must reload from the last checkpoint, losing all unsaved rollout data, and pray for better luck next time.
AgentJet Swarm architecturally solves this problem. Since Swarm Client and Swarm Server are completely decoupled independent processes, Client crashes only mean "one less data provider" to the Server. The Server continues waiting for data from other Clients or patiently waits for the failed Client to recover.
Specifically: - Client crashes: Rollout samples already collected by the Server aren't lost - they're safely stored in the Server's sample buffer. You just need to fix the issue (change IP, restart Docker, top up API balance), then restart the Client, which automatically continues submitting new rollouts from the breakpoint. - Partial task failures: Even if some tasks in a batch fail due to runtime issues, AgentJet gracefully skips failed samples and continues gradient updates with successfully completed samples, wasting no valid computation.
For agent training tasks depending on complex external environments (web browsing, terminal operations, database interactions), this fault tolerance isn't nice-to-have - it's essential.
Debugging Workflow Bugs? Adjusting Rewards? Get Traceback in 10 Seconds
AgentJet achieves true integration of training, inference, and debugging. In traditional frameworks, debugging an agent workflow's reward function is frustrating. You modify one line of reward calculation logic, then need to: restart the entire training script → wait for model loading (tens of seconds to minutes) → wait for vLLM engine initialization → wait for first rollout completion → finally see error messages. The entire cycle might take 5-10 minutes, when you might have just made an indentation error.
In swarm mode, this pain point is completely eliminated. Since Swarm Client is a lightweight CPU-only process that doesn't need to load any model weights, startup time is in seconds. Your debugging cycle becomes:
- Modify workflow code or reward functions in IDE (VS Code, Cursor, etc.)
- Restart Swarm Client (about 2-3 seconds)
- Client immediately connects to the running Swarm Server and begins executing new rollouts
- See results or traceback within seconds
This means you can develop agent training processes like developing ordinary Python projects - set breakpoints, examine variables, step through execution. The entire Client side is ordinary Python code, without Ray or any other distributed training framework "black magic." AI programming assistants like Cursor and Claude Code can directly participate in your agent training development and benefit from agent's immediate output feedback to automatically fix bugs.
Multi-Task Cocktail Training: Want to Simultaneously RL Train 40% Math Tasks, 30% Code Tasks, 30% Terminal Tasks with Completely Different Runtimes? No Problem!
Multi-task mixed training is key to improving model generalization, but practically difficult. Math tasks need a symbolic computation validator, code tasks need a secure Docker sandbox, terminal tasks need a complete Linux environment and filesystem - these three runtimes have completely different dependencies, permission requirements, and security policies. Cramming them into the same training process is both troublesome and insecure.
AgentJet swarm mode naturally solves this problem. You just need to deploy one Swarm Server hosting the target model, then start multiple Swarm Clients on different machines (even different network environments), with each Client handling one type of task. You can then use AgentJet's provided "throttler" to adjust different task ratios, or flexibly customize training logic to dynamically allocate ratios during training. Each Client runs independently with independent fault tolerance, without interfering with others.
This architecture brings an additional benefit: resource isolation. Code sandbox needs Docker permissions? Configure it on machine B without affecting other Clients. Browser MCP tools need special network proxies? Only configure on corresponding Client machines. Security boundaries and resource requirements for different tasks are naturally isolated.
Single Node - Multi Model: One Agent Workflow Training Two Heterogeneous Models Together? No Problem, Define Reward Functions and Start Immediately!
Multi-agent collaboration is a frontier direction in agent research, but existing frameworks almost all assume all agents share the same underlying model. This assumption is unreasonable in many scenarios: an agent responsible for high-level planning might need a 32B large model to ensure reasoning quality, while an agent responsible for specific execution might suffice with a 7B small model.
AgentJet Swarm natively supports multi-Server multi-model training topology. You can simultaneously start multiple Swarm Servers on multiple GPU servers, each Server hosting different-sized models, then use one Swarm Client to orchestrate their collaboration:
In workflows, Clients can route different inference requests to different Servers based on roles. Planning agent dialogue history goes to the 32B model, execution agent dialogue history goes to the 7B model. Both models collect their own rollout samples, compute their own gradients, update their own parameters, completing true non-parameter-sharing multi-agent reinforcement learning training.
This capability opens many previously difficult research directions: - Heterogeneous team games: Models of different capability levels form teams, each learning optimal strategies in competitive or cooperative environments - Cascaded decision optimization: Coarse-grained decisions by large models, fine-grained operations by small models, end-to-end joint optimization of the entire decision chain - Teacher-student collaborative training: Large models as teachers providing high-quality planning, small models as students learning execution, both co-evolving through RL signals
Efficient Training-Inference GPU CoLocate Based on VERL
AgentJet swarm architecture's flexibility doesn't come at the cost of GPU utilization efficiency or generating large GPU bubbles. Inside Swarm Servers, AgentJet still uses the battle-tested VERL training-inference CoLocate architecture: this means inference (rollout generation) and training (gradient update) share the same GPU group, avoiding GPU memory waste.
For researchers familiar with VERL, almost all algorithm implementations in VERL can be applied to AgentJet without loss. AgentJet adds swarm communication layers and timeline merging optimizations on this foundation, but keeps core training logic consistent. Low migration cost, guaranteed performance.
Framework Agnostic - Just Support OpenAI Protocol BaseUrl and ApiKey
AgentJet doesn't bind to any specific agent framework. Whether you use LangChain, AutoGen, CrewAI, MetaGPT, or hand-written agent logic based on raw HTTP requests, as long as your agent calls LLMs through OpenAI-compatible API protocols (base_url + api_key), you can seamlessly integrate with AgentJet for training. To your agent code, Swarm Server is no different from any other OpenAI-compatible inference service. The only difference is that AgentJet silently records complete dialogue context and token-level information for training in the background.
This means you can directly use existing, debugged agent workflows for RL training without rewriting any inference call logic. Even some closed-source agent black boxes could theoretically integrate with AgentJet training by simply modifying base_url and api_key in environment variables.
Stable, Reproducible, Version-by-Version Performance Tracking, No Worries
For a training framework, "running" is just the minimum requirement - "running correctly" and "running stably" are what researchers truly care about. AgentJet invests heavily in engineering quality, ensuring every training result is trustworthy.
Version-by-Version Performance Tracking: We maintain a public performance tracking dashboard, continuously recording AgentJet's training curves and final performance across multiple standard tasks (mathematical reasoning, code generation, tool usage, etc.), across major Git versions, across different training backends (VERL, etc.). With every code update, test robots execute benchmark tests, immediately catching any performance regressions. This means: - When upgrading AgentJet versions, you can clearly know how new versions perform on tasks you care about - If an update introduces hidden bugs causing training degradation, we catch them immediately - Researchers can confidently cite AgentJet experimental results because they're reproducible
Token Consistency Auto-Alert & Repair: A hidden issue in agent training is token drift: the same text might be encoded as different token sequences during inference and training phases, causing logprob calculation errors and polluting policy gradient computation accuracy. AgentJet has built-in automatic re-tokenization drift detection and repair mechanisms, enabled by default, automatically validating and correcting token sequences before each rollout sample enters the training pipeline, eliminating such issues.
High-Resolution Logging: When deep diagnosis of training behavior is needed, AgentJet provides token-level rollout logs, recording each token's ID, loss mask status, and logprob values. This information is crucial for understanding model learning dynamics, troubleshooting reward signal anomalies, and verifying workflow logic correctness.
Powerful Training Framework
As an agent training framework, simply implementing a distributed architecture is far from enough. How to provide stable, instantly usable, trustworthy training environments is also a topic we need to research. Therefore, AgentJet possesses and open-sources these core capabilities:
- Rich Tutorial Library: Provides interesting examples as tutorial materials
- Automatic Timeline Merging: Supports multi-agent workflows and uses context merging technology to accelerate training by 1.5x to 10x in multi-turn (or multi-agent) dialogue scenarios (similar to "tree structure" processing capabilities mentioned in Minimax Forge technical reports)
- Reliable and Reproducible: We continuously track framework performance across different tasks + major Git versions + different training backends (data continuously aggregating), what you see is what you get, hidden bugs discovered instantly
- Token Consistency Auto-Alert & Repair: AgentJet automatically performs re-tokenization drift repair based on Token IDs returned by vLLM engines by default
- Multi-Training Backend Support: Supports multiple training backends including VERL, actively working on supporting other training backends like TRL
Summary and Outlook
The core philosophy of AgentJet swarm training framework can be summarized in one sentence: Make agent training flexibility match agent complexity itself.
When agent workflows become increasingly complex, dependent external tools multiply, and involved models become more heterogeneous, training frameworks shouldn't become bottlenecks. AgentJet achieves the following by completely decoupling training inference (Server) from agent runtime (Client):
- Developer Friendly: Debug agent workflows in IDEs on laptops, connect to remote swarms for immediate training
- Engineering Robust: External runtime failures don't affect training progress, seamless continuation after repairs
- Algorithm Flexible: Multi-task mixed training, heterogeneous multi-model collaborative training, dynamic data ratio adjustment - everything configurable
- Performance Reliable: Inherits VERL's efficient CoLocate architecture, supplemented with timeline merging acceleration tricks and version-by-version performance tracking capabilities, ensuring trustworthy results
We believe that when training frameworks are no longer limiting factors, researchers and engineers can invest more energy in truly important things - designing better agent architectures, exploring more effective reward signals, attempting bolder multi-agent collaboration strategies.
AgentJet is fully open-sourced on GitHub. We welcome community researchers and developers to try, provide feedback, and contribute. Let's together push LLM agent training into the swarm era.
Project: https://github.com/modelscope/AgentJet Performance Dashboard: https://benchmark.agentjet.top/ Official Documentation: https://modelscope.github.io/AgentJet/