AutoPrinciple Tutorial¶
1. Overview¶
1.1. What is AutoPrinciple?¶
AutoPrinciple is an LLM-based automated principle generation system designed to dynamically create task-specific evaluation criteria for reward modeling. It leverages large language models (like Qwen3) to extract high-quality assessment rules (e.g., "Is generated content faithful to the source?" or "Is the answer factually accurate?") from minimal example data, replacing traditional manual rule engineering. The system supports multi-modal tasks (text summarization, mathematical reasoning, code generation, etc.) and generates scenario-aware rules adaptively.
1.2. Why to Use AutoPrinciple?¶
Traditional manual rule engineering faces three critical limitations:
Poor Scalability: Manually designing rules for every task-scenario combination (e.g., 10 tasks × 5 scenarios = 50 rule sets) requires excessive human effort。
Subjective Bias: Human-defined rules often reflect individual cognitive biases (e.g., cultural differences in defining "safe content")。
Limited Adaptability: Static rules struggle to adapt to evolving model capabilities (e.g., new error patterns in upgraded models)
AutoPrinciple's advantages:
Efficient Generation: Generates candidate rules in bulk via LLM (e.g., 5 samples × 5 candidates = 25 rules)
Dynamic Optimization: Uses clustering to extract core representative rules (e.g., compress 25 to 3 rules)
Cross-Domain Transfer: Applies the same framework to multi-modal tasks (e.g., "syntax correctness" for code → "semantic fidelity" for translation)
1.3. How AutoPrinciple Works¶
The system operates through a streamlined three-step workflow (with optional iteration):
Candidate Principle Extraction from In-Distribution Data: Generate diverse candidate principles using task-specific in-distribution (ID) data.
High-Quality Principle Compression: Distill candidate principles into a compact, representative set, by applying semantic clustering to group similar candidates.
Iterative Optimization (Optional): Refine principles through evaluation feedback loops.
# Import standard libraries
import sys
import os
from concurrent.futures import ThreadPoolExecutor
from typing import List
# Add project root directory to Python path
sys.path.append("..")
# Add environment variables
os.environ["OPENAI_API_KEY"] = ""
os.environ["BASE_URL"] = ""
# Import local modules
from rm_gallery.core.data.schema import DataSample
from rm_gallery.core.model.openai_llm import OpenaiLLM
from rm_gallery.core.reward.principle.auto import AutoPrincipleGenerator
from rm_gallery.core.utils.file import read_jsonl
# Initialize logger
from loguru import logger
logger.add("principle_generator.log", rotation="1 day")
2.2. Load Data¶
Using data from the "Precise IF" task as input examples
try:
# Data path (modify according to your actual path)
train_path = "./data/Summarization Train.jsonl"
test_path = "./data/Summarization Test.jsonl"
# Read JSONL format data and convert to DataSample objects
train_samples = [DataSample(**sample) for sample in read_jsonl(train_path)]
test_samples = [DataSample(**sample) for sample in read_jsonl(test_path)]
logger.info(f"Successfully loaded {len(train_samples)} training samples and {len(test_samples)} test samples")
except Exception as e:
logger.error(f"Data loading failed: {str(e)}")
raise
2.3. Configure Generator Parameters¶
Using Qwen3 as the language model
Setting generation and clustering parameters
try:
# Initialize language model
llm = OpenaiLLM(
model="qwen3-235b-a22b", # Model name
enable_thinking=True # Enable reasoning mode
)
SCENARIO = "Summarization: The text is compressed into a short form, retaining the main information, which is divided into extraction (directly selected from the original text) and production (rewriting the information)."
# Create principle generator
generator = AutoPrincipleGenerator( # or IterativePrincipleGenerator
llm=llm,
scenario=SCENARIO, # Scenario description
generate_number=5, # Generate 5 candidate principles per sample
cluster_number=3 # Cluster to 3 representative principles
)
logger.info("Successfully initialized AutoPrincipleGenerator")
except Exception as e:
logger.error(f"Generator configuration failed: {str(e)}")
raise
2.4. Execute Batch Generation¶
try:
# Execute batch generation
principles = generator.run_batch(
train_samples[:10], # Process first 10 samples as example
thread_pool=ThreadPoolExecutor(max_workers=12)
)
logger.info(f"Successfully generated {len(principles)} principles")
except Exception as e:
logger.error(f"Principle generation failed: {str(e)}")
raise
2.5. Evaluation with Generated Principles¶
from rm_gallery.gallery.rm.alignment.base import BaseHelpfulnessListWiseReward
try:
principles = [f"{k}: {v}" for k, v in principles.items()][:3]
reward = BaseHelpfulnessListWiseReward(
name="test_helpfulness_listwise_reward",
llm=llm,
principles=principles,
scenario=SCENARIO
)
evaluation_samples = reward.evaluate_batch(samples=test_samples[:20])
logger.info(f"Successfully evaluate test samples")
except Exception as e:
logger.error(f"Reward evaluation failed: {str(e)}")
raise
2.6. Evaluation Results Analysis¶
Analyze the accuracy rate of test samples
# accuracy
def calc_acc(samples: List[DataSample]) -> float:
labels = []
for sample in samples:
labels.append(0)
for output in sample.output:
if output.answer.label["preference"] == "chosen":
score = sum(r.score for r in output.answer.reward.details)
if score > 0:
labels[-1] = 1
return sum(labels) / len(labels)
logger.info(f"Accuracy: {calc_acc(evaluation_samples)}")
3. Built-in Reward Models Results¶
Introduce our experimental result on built-in reward models with generated principles.
3.1. Setting¶
The experimental setup compares two approaches across multiple scenarios:
3.1.1. Experimental Configuration:¶
Directly uses built-in reward models, which extend the base approach by integrating automatically generated principles via the AutoPrinciple. The generated principles may also be manually reviewed and lightly refined.
Detailed Settings:
Models: Both configurations use qwen3-32b for evaluation, while principles are generated using qwen3-235b-a22b.
Data: 10% of training samples are used to generate principles, and the remaining samples are evaluated.
Metric: Accuracy, defined as the proportion of correctly preferred outputs based on reward scores, with 5-10 independent run.
3.1.2. Baseline Configuration¶
The baseline configuration uses only the built-in reward templates, removing all principles and related descriptions. This is designed to specifically evaluate the effectiveness of principles. Additionally, the evaluation model and metrics are consistent with the experimental group. The prompt is as follows:
Prompt
# Task Description\nYour role is that of a professional evaluation expert. I will provide you with a question and several candidate answers. Your task is to select the single best answer from the candidates.\n\n\n\n\n\n# Query\n\n\n\n# Answers\n## Answer 1\n## Answer 2\n## Answer 3\n## Answer 4\n.\n\n\n\n# Output Requirement\nNote: Ensure all outputs are placed within the tags like3.2. Evaluation Results¶
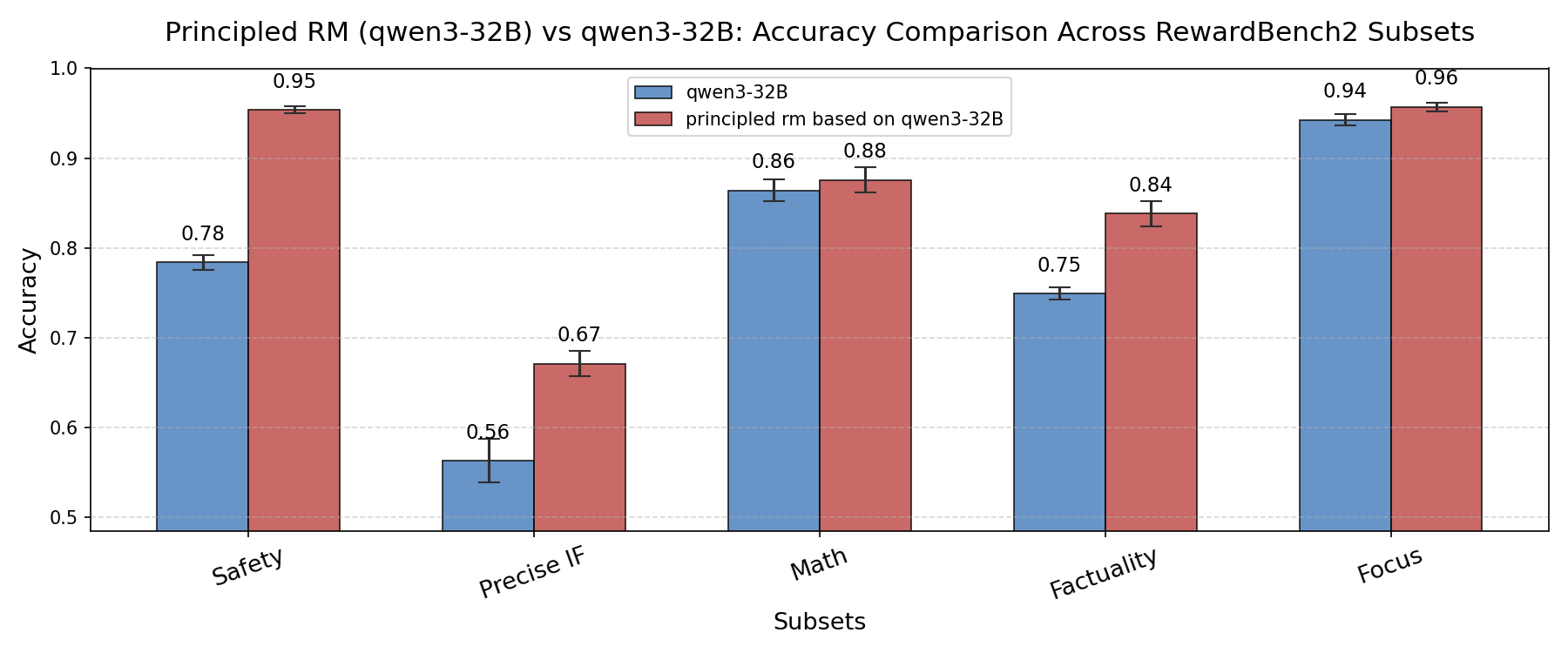
3.2.1. RewardBench2¶
3.2.2. RMBBench¶
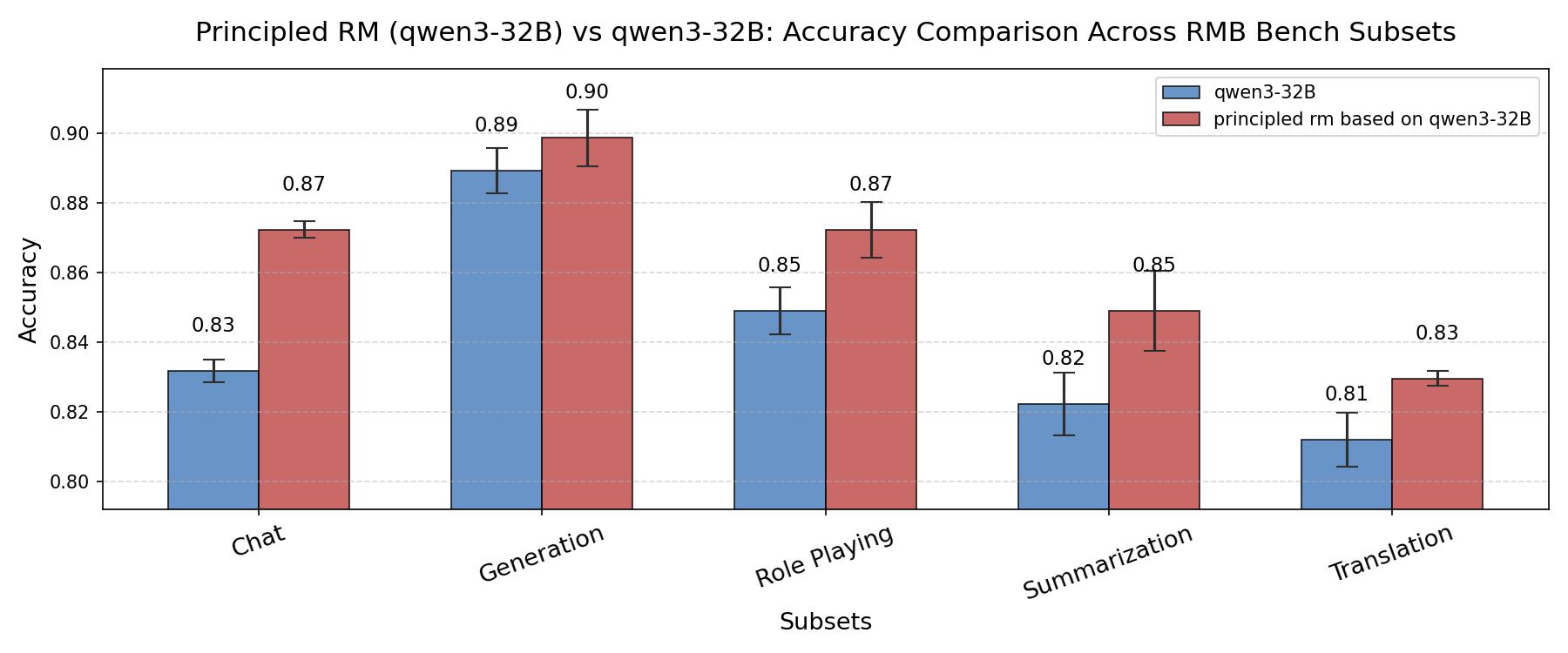
In the RMB Bench dataset, principle-based reward models consistently achieve higher accuracy across multiple subsets. We will continue to analyze these cases in depth. We will also further explore the effectiveness of principles in more scenarios in the future.