Controllable diffusion methods have substantially expanded the practical utility of diffusion models, but they are typically developed as isolated, backbone-specific systems with incompatible training pipelines, parameter formats, and runtime hooks. This fragmentation makes it difficult to reuse infrastructure across tasks, transfer capabilities across backbones, or compose multiple controls within a single generation pipeline.
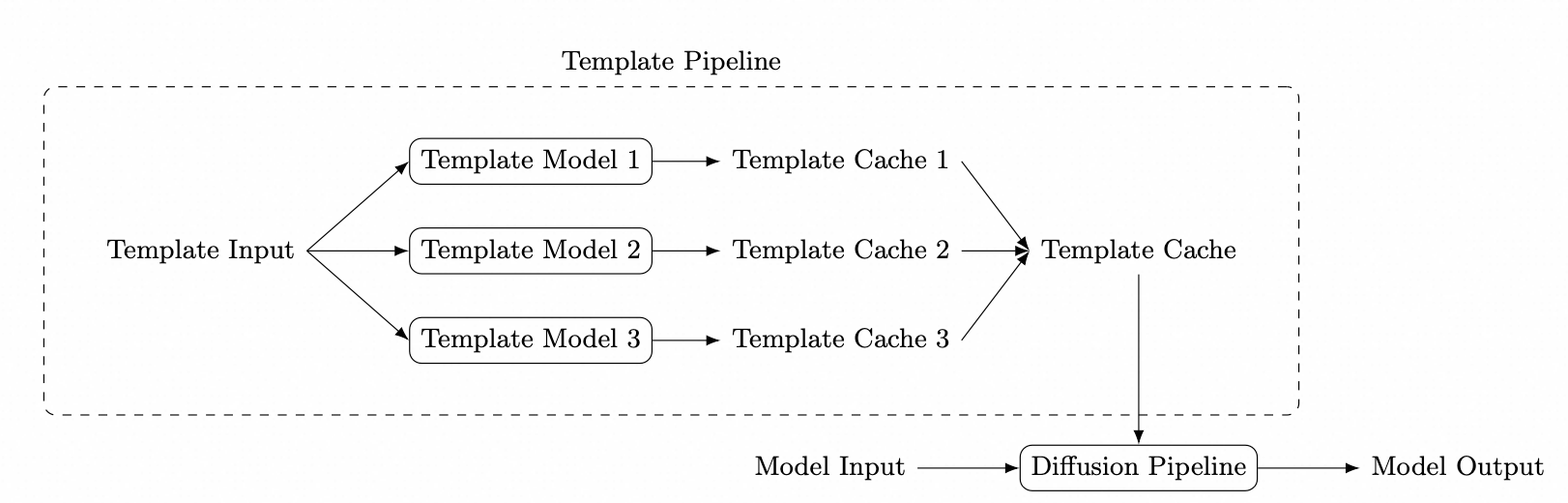
We present Diffusion Templates, a unified and open plugin framework that decouples base-model inference from controllable capability injection. The framework is organized around three components: Template models that map arbitrary task-specific inputs to an intermediate capability representation, a Template cache that functions as a standardized interface for capability injection, and a Template pipeline that loads, merges, and injects one or more Template caches into the base diffusion runtime. Because the interface is defined at the systems level rather than tied to a specific control architecture, heterogeneous capability carriers such as KV-Cache and LoRA can be supported under the same abstraction.
Based on this design, we build a diverse model zoo spanning structural control, brightness adjustment, color adjustment, image editing, super-resolution, sharpness enhancement, aesthetic alignment, content reference, local inpainting, and age control. These case studies show that Diffusion Templates can unify a broad range of controllable generation tasks while preserving modularity, composability, and practical extensibility across rapidly evolving diffusion backbones. All resources are open sourced, including code, models, and datasets.
A diverse set of Template models trained on FLUX.2-klein-base-4B, covering structural control, attribute adjustment, image editing, and more.
Guides spatial structure, contours, and perspective via reference images. Supports depth, outline, human pose, and normal maps.






Adjusts image brightness with a scalar value normalized to [0,1].






Controls color tone and temperature via R/G/B channel values.






Precisely edits images via natural language instructions, ~1.8x faster than the base model.






Aesthetic alignment via LoRA carrier, generalizes beyond the [0,1] training range.






Controls portrait age with a scalar parameter (10–90), trained on IMDB-WIKI.






Takes low-resolution input, preserves composition and semantics, recovers high-frequency details.






Encodes reference images via SigLIP2, converts to LoRA for flexible reference-based generation.






Precisely controls sharpness and detail level; lower values yield soft results, higher values produce crisp details.






Accepts an input image and mask, generates new content in the masked region via natural language prompts, seamlessly blending with the surrounding background.










A fun easter egg model that generates hilarious panda-head meme stickers.






A large-scale open dataset collection (~1.2 TB) for training Diffusion Templates models, covering text-to-image generation and diverse image editing tasks. All datasets are released under Apache License 2.0.
@article{duan2025diffusion,
author = {Duan, Zhongjie and Zhang, Hong and Chen, Yingda},
title = {Diffusion Templates: A Unified Plugin Framework for Controllable Diffusion},
year = {2025},
}