Architecture
Sirchmunk’s architecture is organized into cleanly separated layers, following the principle of Separation of Concerns.
System Overview
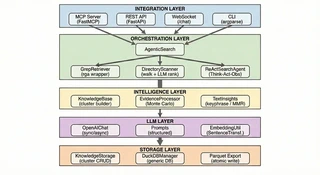
Core Components
| Component | Description |
|---|---|
| AgenticSearch | Search orchestrator with LLM-enhanced retrieval capabilities |
| KnowledgeBase | Transforms raw results into structured knowledge clusters with evidences |
| EvidenceProcessor | Evidence processing based on the Monte Carlo Importance Sampling |
| GrepRetriever | High-performance indexless file search with parallel processing |
| OpenAIChat | Unified LLM interface supporting streaming and usage tracking |
| MonitorTracker | Real-time system and application metrics collection |
Multi-Phase Search Pipeline
At the heart of Sirchmunk is a multi-phase search pipeline designed around maximum parallelism within each phase and strict phase dependencies between them.
Phase 0 — Knowledge Cluster Reuse
Before any computation begins, the system checks whether a semantically similar query has been answered before. A lightweight embedding of the query is compared via cosine similarity against stored knowledge clusters. If a close match is found (above a configurable threshold), the cached cluster is returned immediately — providing sub-second response times for repeated or paraphrased queries.
This is not merely a cache — it is the beginning of knowledge compounding. Each reuse appends the new query to the cluster’s history, so the system remembers which questions led to which insights.
Phase 1 — Parallel Probing
Four independent probes launch concurrently to gather diverse signals:
- LLM Keyword Extraction — The LLM decomposes the query into multi-level keywords, from coarse (high recall) to fine (high precision), each annotated with an estimated rarity score. This multi-granularity approach ensures that both broad topics and specific terms are captured.
- Directory Structure Scan — The file system is traversed to collect path metadata: file names, sizes, modification times, and content previews. This is the foundation for intelligent inference — using structural cues (naming conventions, directory hierarchy, file types) to narrow down the most promising candidates before ever reading their content.
- Knowledge Cache Lookup — Partial match search across existing clusters for potential reuse of previously acquired knowledge.
- Spec-Path Context Load — Previously computed context for known paths is loaded from cache.
Phase 2 — Retrieval & Ranking
Two complementary strategies run in parallel:
- Content-based retrieval — IDF-weighted keyword search through raw file contents
- Structure-based ranking — LLM-guided evaluation of candidate files by metadata
Phase 3 — Knowledge Cluster Construction
Results are merged, deduplicated, and processed through Monte Carlo evidence sampling. The LLM synthesizes evidence fragments into structured Knowledge Clusters.
Phase 4 — Summarization or ReAct Refinement
- Evidence found → LLM generates a structured briefing
- No evidence → ReAct agent activates for iterative exploration
Phase 5 — Persist
Valuable clusters are saved with their embeddings for future reuse.
Key Algorithms
Monte Carlo Evidence Sampling
Traditional retrieval systems read entire documents or rely on fixed-size chunks, leading to either wasted tokens or lost context. Sirchmunk takes a fundamentally different approach inspired by Monte Carlo methods — treating evidence extraction as a sampling problem rather than a parsing problem.
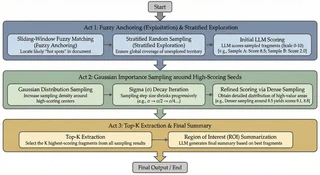
The algorithm operates in three phases:
Phase 1 — Cast the Net (Exploration): Fuzzy anchor matching combined with stratified random sampling. The system identifies seed regions of potential relevance while maintaining broad coverage through randomized probing — ensuring no high-value region is missed.
Phase 2 — Focus (Exploitation): Gaussian importance sampling centered around high-scoring seeds from Phase 1. The sampling density concentrates on the most promising regions, extracting surrounding context and scoring each snippet for relevance.
Phase 3 — Synthesize: The top-K scored snippets are passed to the LLM, which synthesizes them into a coherent Region of Interest (ROI) summary with a confidence flag — enabling the pipeline to decide whether evidence is sufficient or a ReAct agent should be invoked for deeper exploration.
Key properties:
- Document-agnostic: The same algorithm works equally well on a 2-page memo and a 500-page technical manual — no document-specific chunking heuristics needed.
- Token-efficient: Only the most relevant regions are sent to the LLM, dramatically reducing token consumption compared to full-document approaches.
- Exploration-exploitation balance: Random exploration prevents tunnel vision, while importance sampling ensures depth where it matters most.
ReAct Agent
An autonomous Think → Act → Observe loop with:
- Prioritized tool strategy (keyword search → file read → knowledge query → directory scan)
- Dual-budget mechanism (token budget + loop count)
- Memory of previously explored avenues
Self-Evolving Knowledge Clusters
Sirchmunk does not discard search results after answering a query. Instead, every search produces a KnowledgeCluster — a structured, reusable knowledge unit that grows smarter over time. This is what makes the system self-evolving.
What is a KnowledgeCluster?
A KnowledgeCluster is a richly annotated object that captures the full cognitive output of a single search cycle:
| Field | Purpose |
|---|---|
| Evidences | Source-linked snippets extracted via Monte Carlo sampling, each with file path, summary, and raw text |
| Content | LLM-synthesized markdown with structured analysis and references |
| Patterns | 3–5 distilled design principles or mechanisms identified from the evidence |
| Confidence | A consensus score \[0, 1\] indicating the reliability of the cluster |
| Queries | Historical queries that contributed to or reused this cluster (FIFO, max 5) |
| Hotness | Activity score reflecting query frequency and recency |
| Embedding | 384-dim vector derived from accumulated queries, enabling semantic retrieval |
Lifecycle: From Creation to Evolution
┌─────── New Query ───────┐
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 0: Semantic Reuse │──── Match found ──→ Return cached cluster
│ │ (cosine similarity ≥ 0.85) │ + update hotness/queries/embedding
│ └──────────┬───────────────────┘
│ No match
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 1–3: Full Search │
│ │ (keywords → retrieval → │
│ │ Monte Carlo → LLM synth) │
│ └──────────┬───────────────────┘
│ ▼
│ ┌──────────────────────────────┐
│ │ Build New Cluster │
│ │ Deterministic ID: C{sha256} │
│ └──────────┬───────────────────┘
│ ▼
│ ┌──────────────────────────────┐
│ │ Phase 5: Persist │
│ │ Embed queries → DuckDB → │
│ │ Parquet (atomic sync) │
└─────└──────────────────────────────┘
Reuse Check (Phase 0): Before any retrieval, the query is embedded and compared against all stored clusters via cosine similarity. If a high-confidence match is found, the existing cluster is returned instantly — saving LLM tokens and search time entirely.
Creation (Phase 1–3): When no reuse match is found, the full pipeline runs: keyword extraction, file retrieval, Monte Carlo evidence sampling, and LLM synthesis produce a new
KnowledgeCluster.Persistence (Phase 5): The cluster is stored in an in-memory DuckDB table and periodically flushed to Parquet files. Atomic writes and mtime-based reload ensure multi-process safety.
Evolution on Reuse: Each time a cluster is reused, the system:
- Appends the new query to the cluster’s query history (FIFO, max 5)
- Increases hotness (
+0.1, capped at 1.0) - Recomputes the embedding from the updated query set — broadening the cluster’s semantic catchment area
- Updates version and timestamp
Key Properties
- Zero-cost acceleration: Repeated or semantically similar queries are answered from cached clusters without any LLM inference, making subsequent searches near-instantaneous.
- Query-driven embeddings: Cluster embeddings are derived from queries rather than content, ensuring that retrieval aligns with how users actually ask questions — not how documents are written.
- Semantic broadening: As diverse queries reuse the same cluster, its embedding drifts to cover a wider semantic neighborhood, naturally improving recall for related future queries.
- Lightweight persistence: DuckDB in-memory + Parquet on disk — no external database infrastructure required. Background daemon sync with configurable flush intervals keeps overhead minimal.
Data Storage
All persistent data is stored in the configured SIRCHMUNK_WORK_PATH (default: ~/.sirchmunk/):
{SIRCHMUNK_WORK_PATH}/
├── .cache/
├── history/ # Chat session history (DuckDB)
│ └── chat_history.db
├── knowledge/ # Knowledge clusters (Parquet)
│ └── knowledge_clusters.parquet
└── settings/ # User settings (DuckDB)
└── settings.db
Design Principles
Sirchmunk adheres to SOLID principles:
- Single Responsibility — Each component has one clear purpose
- Open/Closed — Extended through abstractions, not modifications
- Liskov Substitution — All implementations honor abstract contracts
- Interface Segregation — Minimal, focused interfaces
- Dependency Inversion — High-level logic depends on abstractions
For a comprehensive technical analysis, read the Technical Deep Dive.