Sirchmunk:技术深度报告
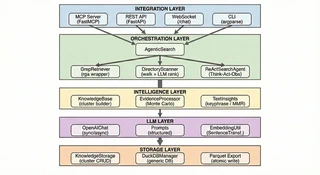 Sirchmunk 架构
Sirchmunk 架构Sirchmunk 是一款开源、无需向量嵌入的智能搜索引擎,能够将原始数据实时转化为自进化智能。与依赖静态向量嵌入、预计算索引和复杂 ETL 管线的传统 RAG(检索增强生成)系统不同,Sirchmunk 直接操作原始文件 — 无需任何预处理即可提供即时、完整保真度的检索。
本报告全面技术分析了 Sirchmunk 的设计哲学和架构原则,涵盖其多阶段搜索管线、蒙特卡洛证据采样、基于 ReAct 的智能体精炼、自进化知识聚类,以及跨 MCP、OpenClaw、REST、WebSocket、CLI 和 Web UI 的集成接口。
1. 摘要
Sirchmunk 是一款开源、无需向量嵌入的智能搜索引擎,能够将原始数据实时转化为自进化智能。与依赖静态向量嵌入、预计算索引和复杂 ETL 管线的传统 RAG(检索增强生成)系统不同,Sirchmunk 直接操作原始文件 — 无需任何预处理即可提供即时、完整保真度的检索。
本报告全面技术分析了 Sirchmunk 的设计哲学和架构原则,涵盖其多阶段搜索管线、蒙特卡洛证据采样、基于 ReAct 的智能体精炼、自进化知识聚类,以及跨 MCP、OpenClaw、REST、WebSocket、CLI 和 Web UI 的集成接口。
2. 设计动机与哲学
基于向量检索构建的智能管线通常是僵化而脆弱的。它们存在三个根本性问题:
- 计算成本高昂 — 构建和维护向量索引需要大量计算和时间。
- 对实时变化无感知 — 底层数据一旦变化,嵌入即刻过时。
- 脱离原始上下文 — 向量近似会丢失信息;检索本质上是有损的。
Sirchmunk 的设计哲学建立在三个支柱之上:
| 支柱 | 原则 | Sirchmunk 的实现方式 |
|---|---|---|
| 无嵌入 | 以最纯粹的形式处理数据 | 无索引检索,零信息损失。基于路径元信息和探测采样的智能推理定位最可能的目标文件 — 无需构建向量索引。 |
| 自进化 | 数据是流,不是快照 | 知识簇随每次搜索进化;LLM 驱动的自主性确保系统的理解随时间深化。 |
| Token 高效 | 最大化智能,最小化成本 | 仅在必要时触发 LLM 推理;蒙特卡洛采样从文档中提取精确证据,无需完整阅读。 |
与传统 RAG 的对比
| 维度 | 传统 RAG | Sirchmunk |
|---|---|---|
| 搭建成本 | 高 — 向量数据库、图数据库、文档解析器、ETL 管线 | 零 — 放入文件即刻搜索 |
| 数据时效性 | 过时 — 需要批量重新索引 | 即时 — 直接搜索实时文件 |
| 信息保真度 | 有损 — 向量近似丢失细节 | 完整 — 原始内容,零损失 |
| 可扩展性 | 数据量增长带来线性成本增长 | 低资源消耗 — 流式搜索、内存分析 |
| 准确性 | 近似匹配 — 可能遗漏或产生幻觉 | 确定性 — 基于证据,附带置信度分数 |
| 知识演进 | 静态 — 索引是时间快照 | 自进化 — 知识簇随每次搜索增长 |
| Token 效率 | 将整个文档块发送给 LLM | 蒙特卡洛采样仅选择最相关的区域 |
| 失败模式 | 返回向量索引匹配的内容 — 无补救措施 | ReAct 智能体自适应检索,进行迭代深度探索 |
3. 系统架构
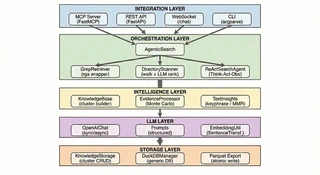
4. 核心搜索管线
Sirchmunk 的核心是一个多阶段搜索管线。核心设计原则是每个阶段内最大并行化与阶段之间严格的依赖关系。这同时实现了速度和正确性:独立任务并发竞争,而每个阶段都建立在前一阶段汇聚的输出之上。
Sirchmunk 支持两种搜索模式:FAST 模式(默认)采用贪心策略,结合两级关键词级联、上下文窗口采样和 early stopping,仅需 2 次 LLM 调用即可在 2–5 秒内完成检索(速度约为 DEEP 模式的 10 倍)。DEEP 模式 则激活下文所述的完整管线,包括蒙特卡洛证据采样和多轮 ReAct 自适应推理,适用于复杂查询场景下的最大召回(10–30 秒)。
Query
|
v
+----------------------------------------------+
| 阶段 0: 知识复用 |
| "我们之前见过类似问题吗?" |
| 是 -> 立即返回 | 否 -> 继续 |
+-------------------+--------------------------+
v
+----------------------------------------------+
| 阶段 1: 并行探测 |
| 四个独立探测并发运行: |
| - LLM 关键词提取(多粒度) |
| - 目录结构扫描(元数据) |
| - 知识缓存查找(部分复用) |
| - 指定路径上下文缓存加载 |
+-------------------+--------------------------+
v
+----------------------------------------------+
| 阶段 2: 检索与排序 |
| 两种策略并行运行: |
| - 基于关键词的内容检索(IDF) |
| - LLM 引导的文件候选排序 |
+-------------------+--------------------------+
v
+----------------------------------------------+
| 阶段 3: 知识簇构建 |
| 合并去重 -> 蒙特卡洛证据提取 |
| -> LLM 合成 -> 知识簇 |
+-------------------+--------------------------+
v
+----------------------------------------------+
| 阶段 4: 输出 |
| 找到证据? -> LLM 摘要 |
| 无证据? -> ReAct 智能体精炼 |
+-------------------+--------------------------+
v
+----------------------------------------------+
| 阶段 5: 持久化 |
| 保存知识簇 + 嵌入供未来复用 |
+----------------------------------------------+
4.1 阶段 0 — 知识簇复用
在任何繁重计算开始之前,Sirchmunk 先问一个简单问题:“我们之前回答过语义相似的问题吗?” 系统计算传入查询的轻量级嵌入,并度量与所有存储知识簇的余弦相似度。如果找到近似匹配(超过可配置阈值),缓存的知识簇立即返回 — 为重复或改述的查询提供亚秒级响应时间。
这不仅仅是缓存 — 它是知识复利的开始。每次复用都会将新查询追加到知识簇的历史中,因此系统记住了哪些问题导致了哪些洞察。
4.2 阶段 1 — 并行探测
四个独立探测并发启动。设计意图是收集关于答案可能位置的多样化信号,而不是押注单一检索策略:
- LLM 关键词提取 — LLM 将查询分解为多级关键词,从粗粒度(高召回)到细粒度(高精度),每个关键词标注估计的稀有度分数。这种多粒度方法确保同时捕获广泛主题和特定术语。
- 目录结构扫描 — 遍历文件系统收集路径元数据:文件名、大小、修改时间和内容预览。这是智能推理的基础 — 利用结构线索(命名约定、目录层次、文件类型)在阅读文件内容之前就缩小最有前景的候选范围。
- 知识缓存查找 — 搜索现有知识簇进行部分匹配,使系统能够在已有知识的基础上继续构建。
- 指定路径上下文加载 — 从本地缓存加载相同搜索路径的已计算上下文,避免频繁搜索的目录进行冗余工作。
4.3 阶段 2 — 检索与排序
两种互补的检索策略并行运行,体现了双信号哲学:
- 基于内容的检索 — 使用阶段 1 中的多级关键词直接搜索文件内容。结果通过 IDF 加权公式评分,奖励稀有的辨别性术语,惩罚过长或琐碎的片段。这是自底向上的信号:“文本实际说了什么?”
- 基于结构的排序 — LLM 接收目录扫描中的候选文件摘要,并根据推理按相关性排序。这是自顶向下的信号:“根据文件的名称、路径和预览,它包含答案的可能性有多大?”
通过结合自底向上的内容匹配和自顶向下的结构推理,Sirchmunk 实现了比单一策略更高的召回率 — 我们称之为基于路径元信息和探测采样的智能推理。
4.4 阶段 3 — 知识簇构建
来自两种检索策略的文件路径被合并和去重。对于每个候选文件,蒙特卡洛证据采样算法(详见第 6 节)提取最相关的区域,而不读取整个文档。然后 LLM 将这些证据片段合成为结构化的知识簇 — 一个具有确定性身份、置信度分数和生命周期状态的自包含洞察单元。
4.5 阶段 4 — 摘要与 ReAct 精炼
管线现在根据收集证据的丰富程度进行分支:
- 找到证据:LLM 从知识簇生成结构化的 Markdown 简报。它还评估知识簇是否有足够价值进行持久化以供未来复用 — 一种自策展的形式。
- 未找到证据:系统不会简单放弃。相反,ReAct 搜索智能体(详见第 7 节)接管,执行迭代的推理-行动循环以探索替代检索策略,直到找到答案或耗尽预算。
这种自适应检索机制体现了一个核心原则:系统在承认无知之前应该总是更努力地尝试。
5. 无索引检索引擎
检索引擎是 Sirchmunk “放即搜” 哲学的基础。没有索引步骤、没有嵌入生成、没有数据库需要设置。用户只需将系统指向一个目录,即可立即搜索。
走向无索引的理由
传统检索系统需要前期投入:解析每个文档、分割成块、计算嵌入、存储到向量数据库。这个管线成本高昂、脆弱,且数据一旦变化就立即过时。Sirchmunk 完全拒绝这种范式。
相反,它利用高性能的 Rust 全文搜索引擎(ripgrep-all),可以以流式方式搜索 100 多种文件格式 — PDF、Office 文档、压缩包、源代码和纯文本。核心洞察是:当结合 LLM 引导的探测采样时,原始文本搜索加上智能评分就已足够。
智能文件发现
系统不会盲目地搜索每个文件。基于路径元信息和探测采样,它进行智能推理以定位最可能的目标文件:
- 结构线索:文件名、目录层次和扩展名携带关于内容的强先验信号。
security/目录中名为authentication.py的文件比随机的utils.py更可能回答关于认证的问题。 - 多级关键词探测:系统不是用单个查询字符串搜索,而是将问题分解为多个粒度级别的关键词。粗粒度关键词撒下大网;细粒度关键词缩小焦点。每个级别的结果用 IDF 加权相关性评分。
- LLM 引导的结构排序:LLM 根据候选文件的元数据(名称、路径、大小和内容预览)评估哪些文件最值得深入阅读。
这种自底向上的内容搜索和自顶向下的结构推理的组合意味着 Sirchmunk 可以在大型仓库中找到相关文件,其准确性与索引系统相当 — 但没有任何搭建成本。
评分哲学
并非所有匹配都是平等的。评分系统围绕几个原则设计:
- 稀有性很重要:稀有术语(高 IDF)的权重高于常见术语,因为对独特关键词的匹配比对停用词的匹配是更强的信号。
- 收益递减:术语频率受到对数饱和的约束 — 看到关键词 100 次并不比看到一次有价值 100 倍。
- 上下文质量:过短(碎片)或过长(噪声稀释)的片段会被惩罚。理想的匹配是简洁、信息密集的段落。
- 精度奖励:精确的、以空格分界的匹配会获得高于部分匹配的奖励,在不牺牲召回率的同时奖励精度。
6. 蒙特卡洛证据采样
Sirchmunk 最具创新性的贡献或许是其证据提取策略。根本挑战是:一个候选文件可能长达数百页,但只有几个段落是相关的。完整阅读文档的 LLM Token 成本过于昂贵。固定分块策略要么遗漏相关部分,要么将其淹没在噪声中。
Sirchmunk 通过受蒙特卡洛统计推断方法启发的探索-利用方法来解决这个问题。核心思想简单而强大:战略性采样,低成本评分,然后聚焦最佳区域。
三阶段启发式算法
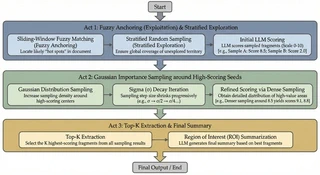
第一阶段:撒网
第一轮结合两种互补策略。模糊锚定(利用)使用快速的 Token 级模糊匹配来识别文档中与查询和关键词词汇相似的区域。这些计算成本低廉,提供良好的初始"热点"。分层随机采样(探索)用从文档中均匀间隔的层中抽取的样本补充锚点,确保没有区域被完全忽略 — 因为有时最相关的段落使用与查询不同的术语。
然后每个样本由 LLM 在 0-10 的相关性量表上评分,并附带结构化推理。这是循环中唯一的 LLM 调用,它在小窗口而非整个文档上操作 — 保持 Token 成本低廉。
第二阶段:聚焦
高分样本成为下一轮的"种子"。新样本从以每个种子为中心的高斯分布中抽取,sigma 随后续轮次衰减。这种渐进式收窄类似于模拟退火:早期轮次广泛探索,后期轮次以递增精度收敛于最高价值区域。
该过程包含提前停止:如果某个样本超过高置信阈值,算法立即终止,节省不必要的轮次。
第三阶段:合成
Top-K 评分片段被传递给 LLM,合成为连贯的兴趣区域(ROI)摘要。输出包含一个置信标志,指示是否发现了强证据,使管线能够做出知情决策:是继续进行摘要,还是启用 ReAct 智能体进行自适应检索。
设计洞察: 通过将证据提取视为采样问题而非解析问题,Sirchmunk 避免了对文档特定分块启发式的需求。同一算法在 2 页备忘录和 500 页技术手册上同样有效。
7. ReAct 搜索智能体
当标准管线未能找到足够证据时,Sirchmunk 不会简单返回"未找到结果"。相反,它激活一个 ReAct(推理 + 行动)智能体 — 一个通过工具使用迭代探索数据的自主推理循环,直到找到答案或耗尽预算。
思考 → 行动 → 观察 范式
ReAct 模式在 AI 研究社区中被提出,交替进行三个认知步骤:
- 思考:LLM 推理目前了解什么、缺少什么、以及什么行动最可能填补空白。
- 行动:LLM 选择并调用一个工具 — 关键词搜索、文件读取、知识查询或目录扫描。
- 观察:工具的结果作为新上下文反馈给 LLM,循环重复。
这种范式将搜索从单次检索转变为推理与证据之间的迭代对话。LLM 可以根据发现调整策略 — 如果没有找到结果则扩大搜索范围,或深入探索有前景的文件。
优先工具策略
智能体遵循有原则的搜索策略:先关键词搜索(最便宜、覆盖最广),然后文件读取(对有前景的候选),然后知识缓存查询(利用现有洞察),最后目录扫描(当其他方法都失败时)。这种优先顺序在最大化早期找到相关证据的概率的同时最小化成本。
预算约束的探索
无界智能体循环是智能体 AI 系统中众所周知的风险。Sirchmunk 通过双预算机制解决这个问题:
- Token 预算:消耗的 LLM Token 总量的硬上限,防止成本失控。
- 循环计数:思考-行动-观察循环的最大次数,确保终止。
此外,智能体维护一个已尝试操作的记忆 — 已读取的文件、已执行的搜索 — 以避免浪费性重复。这不仅是效率;它是一种认知纪律,使智能体专注于未探索的途径。
8. 自进化知识系统
Sirchmunk 中的知识不是静态索引 — 它是一个随每次搜索不断积累的活的、进化的洞察图谱。这或许是与传统 RAG 最深刻的哲学分歧:系统不仅检索;它还在学习。
知识簇
知识的基本单元是知识簇 — 一个从原始证据中由 LLM 合成的自包含洞察。每个知识簇携带:
- 一个确定性身份(内容哈希),使相同的洞察始终收敛到同一知识簇。
- 证据单元链接回原始源文件和片段 — 每个结论都可追溯。
- 一个置信度分数,反映底层证据的强度和一致性。
- 一个抽象级别(技术 → 原则 → 范式 → 基础 → 哲学)— 分类洞察的可推广程度。
- 一个生命周期状态(萌芽 → 稳定 → 弃用或有争议)— 建模知识的自然演进。
- 一个热度分数,反映知识簇被访问的频率,使系统能够优先处理常需的知识。
知识簇如何进化
知识的演进遵循自然生命周期:
- 创建:新搜索产生的证据与任何现有知识簇不匹配。蒙特卡洛采样提取证据;LLM 将其合成为新知识簇。
- 复用:类似查询到达。轻量级嵌入上的余弦相似度识别匹配的知识簇,立即返回。新查询追加到知识簇的历史中。
- 成熟:随着知识簇被多次查询复用和验证,其置信度增长,生命周期从"萌芽"过渡到"稳定"。
- 弃用:当底层数据变化且证据不再支持知识簇时,它可能过渡到"有争议"或"已弃用"。
知识图谱
知识簇不是孤立存在的。两种类型的语义边将它们编织成图谱:
- 弱语义边:轻量级的加权连接,指示主题相关性。
- 丰富认知边:类型化关系(路径、障碍、类比、捷径、解决方案),在更深层次建模洞察之间的关系 — 为未来的认知图谱导航和思维链检索等能力赋能。
设计洞察: 通过使用生命周期状态和抽象级别建模知识,Sirchmunk 将其知识库视为一个活的有机体而非死的档案。知识可以诞生、成长并最终退休 — 映射人类专业知识的演进方式。
9. 存储与持久化哲学
Sirchmunk 的存储设计遵循我们称之为**“默认快速,重要时持久”**的原则。系统在运行时完全在内存中操作以获得最高速度,同时后台进程透明地将状态同步到磁盘以确保持久性。
内存优先,磁盘其次
所有知识簇、聊天历史和设置在执行期间存在于内存分析数据库(DuckDB)中。这提供微秒级读写访问。守护线程定期使用列式 Parquet 文件将内存状态同步到磁盘 — 选择 Parquet 是因为其出色的压缩率、分析查询性能和生态系统兼容性。
原子持久化
磁盘写入使用原子模式:数据首先写入临时文件,然后原子性地重命名到目标位置。这意味着磁盘上的状态始终一致,即使进程在写入过程中崩溃。没有损坏窗口。
嵌入感知存储
每个知识簇的嵌入向量(384 维)与知识簇数据一起存储,为阶段 0 的复用机制提供高效的相似性搜索。这是一种刻意的混合方案:虽然 Sirchmunk 在检索方面是"无嵌入"的,但它在知识管理方面使用轻量级嵌入 — 这是一个务实的选择,避免了对每个文档进行嵌入的成本,同时仍然实现语义知识簇匹配。
10. 集成层:MCP、OpenClaw、API 及更多
Sirchmunk 的设计理念是被使用,而非被部署。它不要求用户围绕它构建应用,而是通过多个标准接口暴露其智能 — 在用户已经工作的地方与他们会面。自 v0.0.6post1 起,Sirchmunk 亦以 OpenClaw 技能 形式发布,任何兼容 OpenClaw 的 Agent 均可通过自然语言调用其搜索流程,与 MCP 原生及 HTTP 客户端并存。
模型上下文协议 (MCP)
模型上下文协议集成或许是最具前瞻性的接口。MCP 允许 Claude Desktop 和 Cursor IDE 等 AI 助手将 Sirchmunk 的搜索作为原生工具调用。设计原则是零摩擦的 AI 到 AI 通信:AI 助手可以无缝地请求 Sirchmunk 搜索用户的本地文件,结果作为结构化上下文回流。
MCP 服务器支持两种传输模式:stdio(用于与桌面 AI 工具的本地集成)和 HTTP(用于远程或网络化场景)。搜索、目录扫描和知识管理能力都作为 MCP 工具暴露,任何兼容的客户端都可以发现和调用。
REST API 与实时聊天
对于编程访问,完整的 REST API 提供搜索、知识管理、系统监控和设置配置。设计遵循渐进式披露原则:单个搜索端点足以满足基本使用,而高级参数允许对搜索深度、文件过滤和输出格式进行精细控制 — 例如 return_context 用于在响应中包含扩展上下文(替代旧版 return_cluster 参数)。
实时聊天由 WebSocket 连接驱动,支持带内嵌搜索日志和来源引用的流式响应。聊天系统支持多种模式:纯 LLM 对话、文件 RAG 增强对话和网络增强搜索 — 用户可在运行时选择。
Web UI
Web 界面围绕透明智能原则构建:用户不仅应该看到答案,还应该理解系统是如何得出答案的。UI 提供流式搜索日志、来源引用、知识簇浏览和系统监控仪表盘 — 全部集成在一个现代界面中,支持深色/浅色主题和双语本地化(英文和中文)。
CLI
命令行界面作为所有操作的主要入口:初始化、服务器管理、直接搜索、Web UI 服务和 MCP 服务器启动。设计原则是一个工具,所有模式 — 单个二进制文件覆盖从快速本地搜索到完整生产部署的每种用例。
11. 结论
Sirchmunk 代表了我们思考检索增强生成方式的范式转变。通过消除嵌入瓶颈并拥抱智能体驱动的、基于证据的方法,它实现了:
- 零基础设施开销 — 无需向量数据库、图数据库或 ETL 管线。只有文件。
- 实时数据时效性 — 始终搜索实时文件系统,永远不是过时的索引。
- Token 效率 — 蒙特卡洛采样最小化 LLM 成本,同时最大化提取证据的相关性。
- 自进化智能 — 知识簇随时间积累,使重复查询更快更丰富。
- 自适应检索 — 当标准管线未找到内容时,ReAct 智能体自主进行更深入的探索而非放弃。
- 通用集成 — MCP、OpenClaw、REST、WebSocket、CLI 和 Web UI 在用户工作的任何地方与之会面。
技术栈
| 层 | 技术 |
|---|---|
| 语言 | Python 3.10+ |
| 全文搜索 | ripgrep-all(基于 Rust,100+ 格式) |
| 文本提取 | Kreuzberg |
| 模糊匹配 | RapidFuzz |
| 嵌入 | SentenceTransformers(通过 ModelScope) |
| LLM 接口 | OpenAI 兼容(任何供应商) |
| 存储 | DuckDB(内存)+ Apache Parquet(持久化) |
| API | FastAPI + Uvicorn |
| MCP | FastMCP |
| 前端 | Next.js 14 + Tailwind CSS + React |
| 许可证 | Apache License 2.0 |
本技术报告通过分析 Sirchmunk 源代码(v0.0.6post1)生成。 github.com/modelscope/sirchmunk · ModelScope
Sirchmunk:从原始数据到自进化智能,实时。
