架构设计
Sirchmunk 采用清晰分离的层次化架构,遵循关注点分离原则。
系统概览
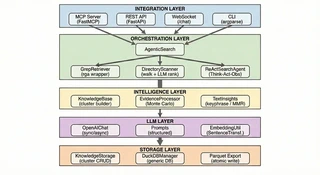
核心组件
| 组件 | 说明 |
|---|---|
| AgenticSearch | 搜索编排器,具备 LLM 增强检索能力 |
| KnowledgeBase | 将原始结果转化为结构化知识簇并附带证据 |
| EvidenceProcessor | 基于蒙特卡洛重要性采样的证据处理 |
| GrepRetriever | 高性能 无索引 文件检索,支持并行处理 |
| OpenAIChat | 统一 LLM 接口,支持流式与用量统计 |
| MonitorTracker | 实时系统与应用指标采集 |
多阶段搜索管线
Sirchmunk 的核心是一个多阶段搜索管线,其设计原则是每个阶段内最大并行化与阶段之间严格的依赖关系。
阶段 0 — 知识簇复用
在任何计算开始之前,系统会检查是否有语义相似的查询已被回答过。将查询的轻量级嵌入通过余弦相似度与存储的知识簇进行比较。如果找到近似匹配(超过可配置的相似度阈值),缓存的知识簇会立即返回——为重复或改述的查询提供亚秒级响应时间。
这不仅仅是缓存——它是知识复利积累的起点。每次复用都会将新查询追加到知识簇的历史中,让系统记住哪些问题导向了哪些洞见。
阶段 1 — 并行探测
四个独立的探测并发启动,收集多样化信号:
- LLM 关键词提取 — LLM 将查询分解为多层级关键词,从粗粒度(高召回)到细粒度(高精度),每个关键词附带稀有度评分。这种多粒度方法确保同时捕获广泛主题和特定术语。
- 目录结构扫描 — 遍历文件系统收集路径元数据:文件名、大小、修改时间和内容预览。这是智能推断的基础——利用结构线索(命名规范、目录层级、文件类型)在读取内容之前就缩小最有可能的候选范围。
- 知识缓存查找 — 在现有知识簇中进行部分匹配搜索,复用先前获取的知识。
- 指定路径上下文加载 — 从缓存中加载已知路径的预计算上下文。
阶段 2 — 检索与排序
两种互补策略并行运行:
- 基于内容的检索 — IDF 加权关键词搜索原始文件内容
- 基于结构的排序 — LLM 引导的候选文件元数据评估
阶段 3 — 知识簇构建
结果被合并、去重,并通过蒙特卡洛证据采样处理。LLM 将证据片段合成为结构化的知识簇。
阶段 4 — 摘要或 ReAct 精炼
- 找到证据 → LLM 生成结构化简报
- 未找到证据 → ReAct 智能体启动进行迭代探索
阶段 5 — 持久化
有价值的知识簇连同其嵌入一起保存,供未来复用。
核心算法
蒙特卡洛证据采样
传统检索系统要么读取完整文档,要么依赖固定大小的分块,导致 Token 浪费或上下文丢失。Sirchmunk 借鉴蒙特卡洛方法,采用了截然不同的策略——将证据提取视为一个采样问题而非解析问题。
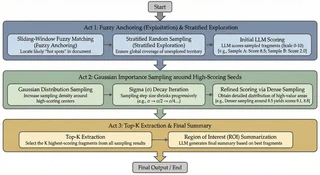
该算法分为三个阶段:
第一阶段 — 撒网(探索): 模糊锚定匹配结合分层随机采样。系统在识别潜在相关种子区域的同时,通过随机探测保持广泛覆盖,确保不会遗漏高价值区域。
第二阶段 — 聚焦(利用): 以第一阶段高分种子为中心进行高斯重要性采样。采样密度集中在最有前景的区域,提取上下文并对每个片段评分。
第三阶段 — 合成: 将 Top-K 评分片段传递给 LLM,合成为连贯的兴趣区域(ROI)摘要,并附带置信度标志——使管线能够判断证据是否充分,或是否需要启用 ReAct 智能体进行更深层的自适应检索。
核心特性:
- 文档无关性: 同一算法在 2 页备忘录和 500 页技术手册上同样有效,无需针对特定文档的分块启发式规则。
- Token 高效: 仅将最相关的区域发送给 LLM,相比全文档方案大幅降低 Token 消耗。
- 探索-利用平衡: 随机探索防止视野盲区,重要性采样确保在关键区域深入挖掘。
ReAct 智能体
自主的"思考 → 行动 → 观察"循环:
- 优先工具策略(关键词搜索 → 文件读取 → 知识查询 → 目录扫描)
- 双预算机制(Token 预算 + 循环次数)
- 记忆已探索的途径
自进化知识簇(Knowledge Cluster)
Sirchmunk 不会在回答完查询后丢弃搜索结果。相反,每次搜索都会产生一个 KnowledgeCluster(知识簇)——一个结构化、可复用的知识单元,随着使用不断变得更加智能。这正是系统具备_自进化_能力的核心机制。
什么是 KnowledgeCluster?
KnowledgeCluster 是一个丰富标注的对象,完整记录了单次搜索周期的认知产出:
| 字段 | 用途 |
|---|---|
| Evidences(证据) | 通过蒙特卡洛采样提取的源文件片段,包含文件路径、摘要和原始文本 |
| Content(内容) | LLM 合成的结构化 Markdown 分析,附带引用 |
| Patterns(模式) | 从证据中提炼的 3–5 条设计原则或核心机制 |
| Confidence(置信度) | 共识评分 \[0, 1\],指示知识簇的可靠性 |
| Queries(查询历史) | 贡献或复用该知识簇的历史查询(FIFO,最多 5 条) |
| Hotness(热度) | 反映查询频率和时效性的活跃度评分 |
| Embedding(嵌入向量) | 由累积查询生成的 384 维向量,用于语义检索 |
生命周期:从创建到进化
┌─────── 新查询 ───────┐
│ ▼
│ ┌───────────────────────────────┐
│ │ 阶段 0:语义复用 │──── 匹配命中 ──→ 返回缓存知识簇
│ │ (余弦相似度 ≥ 0.85) │ + 更新热度/查询/嵌入
│ └──────────┬────────────────────┘
│ 未匹配
│ ▼
│ ┌───────────────────────────────┐
│ │ 阶段 1–3:完整搜索 │
│ │ (关键词 → 检索 → │
│ │ 蒙特卡洛采样 → LLM 合成) │
│ └──────────┬────────────────────┘
│ ▼
│ ┌───────────────────────────────┐
│ │ 构建新知识簇 │
│ │ 确定性 ID: C{sha256} │
│ └──────────┬────────────────────┘
│ ▼
│ ┌───────────────────────────────┐
│ │ 阶段 5:持久化 │
│ │ 嵌入查询 → DuckDB → │
│ │ Parquet(原子写入同步) │
└─────└───────────────────────────────┘
复用检查(阶段 0): 在任何检索开始之前,查询会被嵌入并通过余弦相似度与所有已存储知识簇进行比对。若发现高置信度匹配,系统直接返回已有知识簇——完全省去 LLM 推理和搜索开销。
创建(阶段 1–3): 当无复用匹配时,完整管线运行:关键词提取、文件检索、蒙特卡洛证据采样、LLM 合成,最终生成新的
KnowledgeCluster。持久化(阶段 5): 知识簇存储在内存中的 DuckDB 表中,并定期刷写为 Parquet 文件。原子写入和基于文件修改时间的重载机制确保多进程安全。
复用时进化: 每当知识簇被复用时,系统会:
- 将新查询追加到知识簇的查询历史中(FIFO,最多 5 条)
- 提升热度(+0.1,上限 1.0)
- 基于更新后的查询集重新计算嵌入——扩展知识簇的语义覆盖范围
- 更新版本号和时间戳
核心特性
- 零成本加速: 重复或语义相似的查询直接从缓存知识簇获取答案,无需任何 LLM 推理,后续搜索几乎瞬时完成。
- 查询驱动的嵌入: 知识簇嵌入基于_查询_而非内容生成,确保检索与用户的实际提问方式对齐——而非文档的书写方式。
- 语义拓展: 随着多样化查询复用同一知识簇,其嵌入会漂移以覆盖更广的语义邻域,自然提升相关未来查询的召回率。
- 轻量级持久化: DuckDB 内存存储 + Parquet 磁盘持久化——无需外部数据库基础设施。后台守护线程同步,可配置刷写间隔,开销极小。
数据存储
所有持久化数据存储在配置的 SIRCHMUNK_WORK_PATH(默认:~/.sirchmunk/):
{SIRCHMUNK_WORK_PATH}/
├── .cache/
├── history/ # 聊天会话历史(DuckDB)
│ └── chat_history.db
├── knowledge/ # 知识簇(Parquet)
│ └── knowledge_clusters.parquet
└── settings/ # 用户设置(DuckDB)
└── settings.db
设计原则
Sirchmunk 遵循 SOLID 原则:
- 单一职责 — 每个组件有一个明确的用途
- 开放封闭 — 通过抽象扩展,而非修改
- 里氏替换 — 所有实现遵守抽象契约
- 接口隔离 — 最小化、聚焦的接口
- 依赖倒置 — 高层逻辑依赖抽象
欲了解全面的技术分析,请阅读 技术深度报告。