All Modalities
Mainstream Models LLM · VLM · MoE
3 Modes
Local · Ray · Client
TaaS
Training as a Service Cloud-native · Multi-tenant
<5min
Setup Time pip install & go
What is Twinkle?
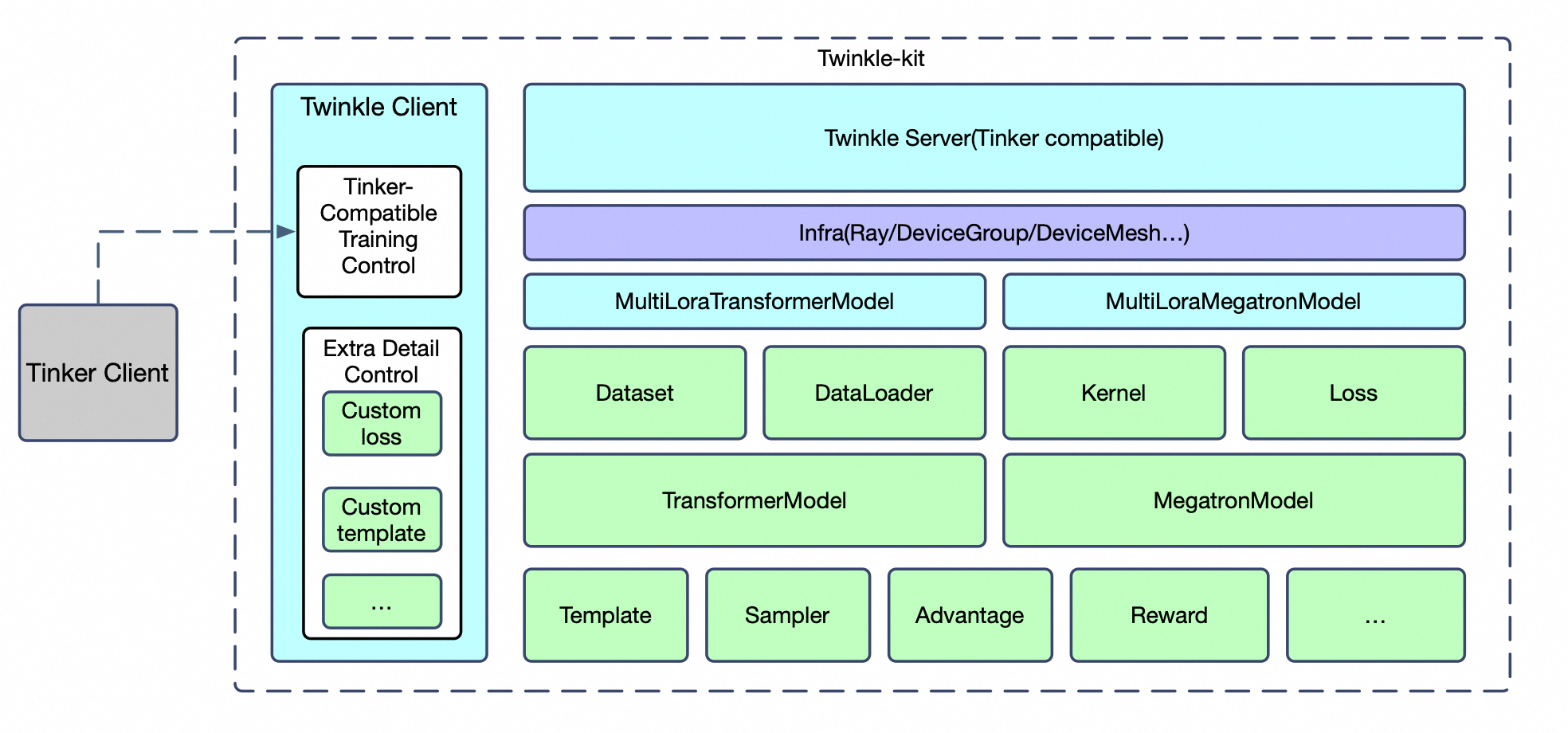
Twinkle is a client-server LLM training framework that separates what you train from how you train.
Write your training logic once with clean Python APIs. Then deploy it anywhere — locally with torchrun,
across Ray clusters, or as serverless Training-as-a-Service.
Train in 20 Lines
pip install 'twinkle-kit[ray]'
import twinkle
from twinkle import DeviceGroup
from twinkle.dataloader import DataLoader
from twinkle.dataset import Dataset, DatasetMeta
from twinkle.model import TransformersModel
# Choose your runtime: 'local' (torchrun), 'ray', or 'http'
twinkle.initialize(mode='ray', groups=[DeviceGroup(name='default', ranks=8)])
# Prepare data — works with ModelScope and Hugging Face
dataset = Dataset(dataset_meta=DatasetMeta('ms://swift/self-cognition'))
dataset.set_template('Qwen3_5Template', model_id='ms://Qwen/Qwen3.5-4B')
dataset.encode()
# Create model — full-parameter training by default
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B', remote_group='default')
# Optional: add LoRA for parameter-efficient training
# from peft import LoraConfig
# model.add_adapter_to_model('default', LoraConfig(r=8, lora_alpha=32))
model.set_optimizer(optimizer_cls='AdamW', lr=1e-4)
# Train — you control the loop
for batch in DataLoader(dataset=dataset, batch_size=8):
model.forward_backward(inputs=batch)
model.clip_grad_and_step()
model.save('my-finetuned-model')
Or train via ModelScope TaaS — no GPU required
import os
from twinkle import init_tinker_client
from twinkle.dataloader import DataLoader
from twinkle.dataset import Dataset, DatasetMeta
from twinkle.preprocessor import SelfCognitionProcessor
from twinkle.server.common import input_feature_to_datum
# Use ModelScope's official TaaS endpoint — free, no local GPU needed
base_url = 'https://www.modelscope.cn/twinkle'
api_key = os.environ.get('MODELSCOPE_TOKEN')
base_model = 'Qwen/Qwen3.6-27B'
# Prepare data locally
dataset = Dataset(dataset_meta=DatasetMeta('ms://swift/self-cognition'))
dataset.set_template('Qwen3_5Template', model_id=f'ms://{base_model}', max_length=256)
dataset.map(SelfCognitionProcessor('My Model', 'My Team'))
dataset.encode(batched=True)
# Connect to ModelScope TaaS
init_tinker_client()
from tinker import ServiceClient, types
service_client = ServiceClient(base_url=base_url, api_key=api_key)
training_client = service_client.create_lora_training_client(
base_model=base_model, rank=16
)
# Train — same loop, running on ModelScope's cluster
for batch in DataLoader(dataset=dataset, batch_size=8):
training_client.forward_backward(
[input_feature_to_datum(f) for f in batch], 'cross_entropy'
)
training_client.optim_step(types.AdamParams(learning_rate=1e-4))
training_client.save_state('my-lora').result()
🔌 Triple API
OpenAI-compatible /chat/completions, native Twinkle API, or Tinker-compatible API
🧩 Modular
25+ components: Dataset, Template, Model, Sampler, Loss, Reward, Metric...
🔀 Backend Agnostic
Transformers or Megatron — switch with one config change
Why Twinkle?
Scale Without Rewriting
Same interface runs on your laptop and on thousand-GPU clusters. Switch from torchrun to Ray to HTTP deployment without changing your training logic.
Multi-Tenancy Built-In
Train N different LoRAs on one base model simultaneously. Each tenant gets isolated optimizer, data pipeline, and loss function — sharing only compute.
You Own the Loop
No hidden magic. See and control every forward, backward, and optimizer step. Compose algorithms freely, customize completely.
Training as a Service
Built for production TaaS deployments with automated cluster management, dynamic scaling, and enterprise multi-tenant isolation.
All Training Methods
SFT, pre-training, GRPO, DPO, GKD, and more. Dense models and MoE architectures. Full FSDP, tensor parallelism, pipeline parallelism support.
Broad Model Support
Qwen 3.6/3.5/3/2.5, DeepSeek R1/V4, Gemma 4, GLM-4, InternLM2, and more. Both Hugging Face and ModelScope model hubs.
Multi-Tenancy: N Jobs, 1 Base Model
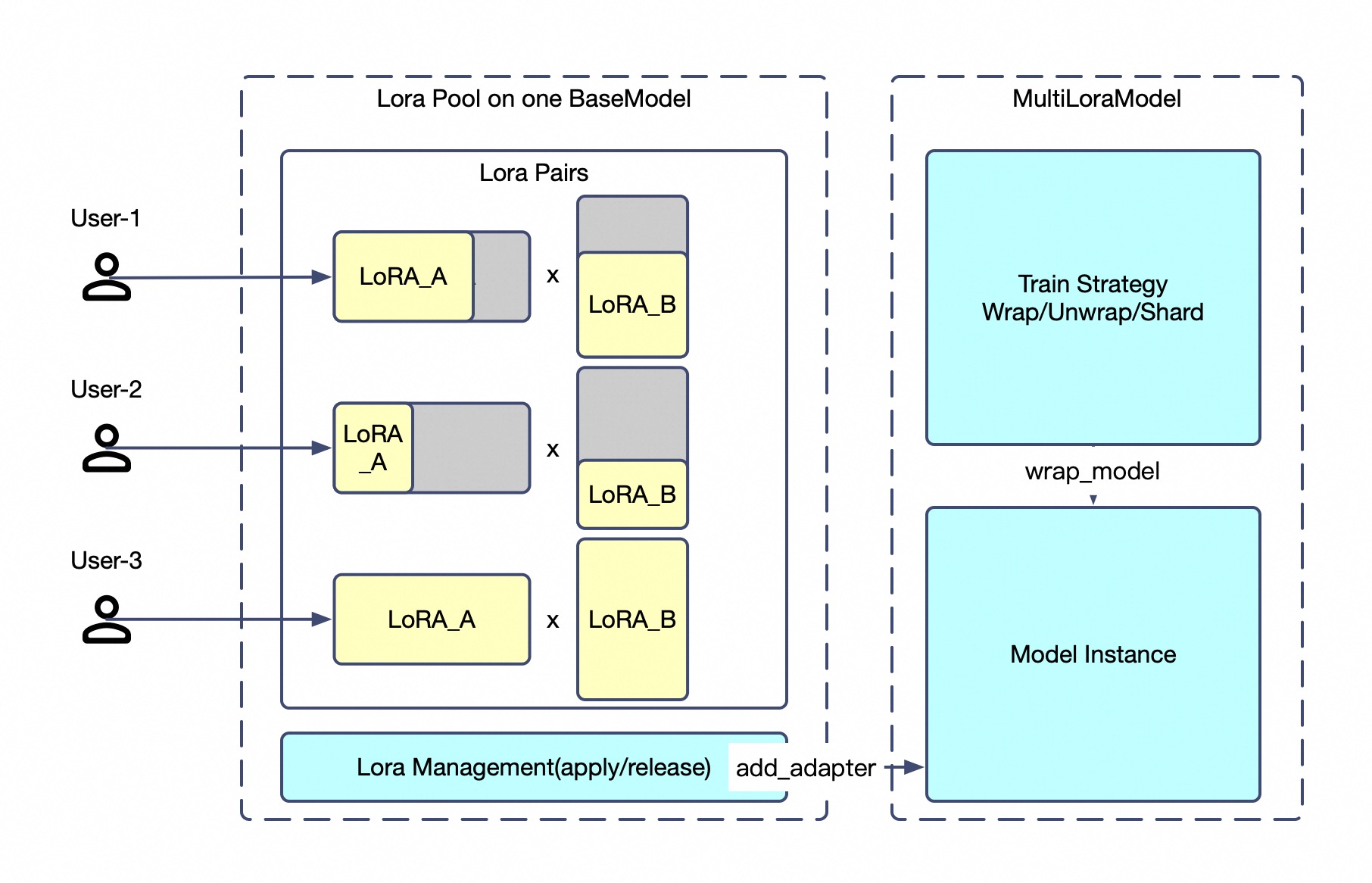
Run completely different training jobs on a shared deployment:
| Tenant | Setup | Task |
|---|---|---|
| A | Full-parameter, private data | SFT fine-tuning |
| B | LoRA r=32, Hub dataset | Continued pre-training |
| C | GRPO loss + Sampler | Reinforcement learning |
| D | Inference mode | Log-prob computation |
Each tenant is fully isolated — different optimizers, data pipelines, loss functions. They only share the base model’s compute. Checkpoints auto-sync to ModelScope or Hugging Face.
Supported Models
Works with mainstream LLMs & VLMs · NVIDIA · Ascend NPU · SFT / PT / GRPO / DPO / GKD / Embedding