Architecture
Twinkle features a decoupled Client-Server architecture designed for maximum flexibility and scalability.
System Overview
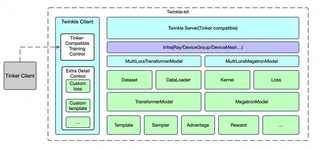
Core Design
Twinkle’s architecture is built around three fundamental principles:
- Decoupled Components — Each component (Dataset, Model, Sampler, Loss) operates independently with standardized interfaces
- Unified API — The same training code runs across different backends (torchrun, Ray, HTTP) with minimal changes
- Multi-Tenancy — Multiple users can train on a shared base model simultaneously with isolated configurations
Client-Server Model
The client-side provides two distinct integration paths:
- Twinkle Native API — A conforming API that mirrors the server-side interface for seamless end-to-end integration
- Tinker Compatibility — Full support for the native Tinker API, enabling developers to leverage Twinkle’s backend using Tinker client
This dual-path design ensures access to Twinkle’s training services using either API.
Core Components
| Component | Description |
|---|---|
| Dataset | Data loading and preprocessing with ModelScope/HuggingFace integration |
| Template | Encoding and decoding for different model architectures |
| DataLoader | Data distribution and batching with device mesh awareness |
| Preprocessor | Data ETL transformations to standard format |
| Model | Large model wrapper supporting Transformers and Megatron |
| Sampler | Sampling logic (e.g., vLLM-based) for RL training |
| Loss | Customizable loss functions (CrossEntropy, GRPO, etc.) |
| Reward | Reward functions for reinforcement learning |
| Advantage | Advantage estimation for policy optimization |
DeviceGroup and DeviceMesh
DeviceGroup and DeviceMesh are the core of Twinkle’s distributed architecture:
import twinkle
from twinkle import DeviceMesh, DeviceGroup
# Define resource groups
device_group = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
]
# Define parallel topology
device_mesh = DeviceMesh.from_sizes(pp_size=2, tp_size=2, dp_size=2)
# Initialize
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_group)
DeviceGroup
Defines how many resource groups are needed for training. Components can run remotely by selecting resource groups:
model = TransformersModel(
model_id='Qwen/Qwen3.5-4B',
remote_group='model',
device_mesh=device_mesh
)
DeviceMesh
Specifies the parallel topology of components within a resource group:
- pp_size — Pipeline parallelism
- tp_size — Tensor parallelism
- dp_size — Data parallelism
- fsdp_size — Fully Sharded Data Parallelism
- cp_size — Context parallelism
Multi-Tenancy Architecture
Twinkle supports simultaneous multi-tenant training on a shared base model:
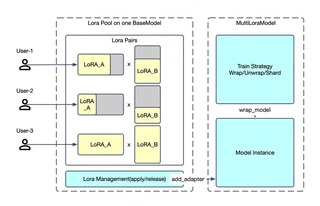
Using a LoRA Pool + Tenant Application architecture:
- Tenant A: Local private dataset, LoRA rank=8, SFT training
- Tenant B: Open-source dataset, LoRA rank=32, PT training
- Tenant C: GRPO loss calculation with sampling
- Tenant D: Log probability inference
All processes execute concurrently because Model and Sampler are integrated as task-agnostic components.
Runtime Modes
Single GPU
Direct training without distributed setup:
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.forward_backward(inputs=batch)
torchrun Mode
Distributed training with PyTorch’s torchrun:
twinkle.initialize(mode='local', global_device_mesh=device_mesh)
torchrun --nproc_per_node=8 train.py
Ray Mode
Distributed training across Ray clusters:
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_group)
HTTP Mode
Training as a Service deployment:
# Server
twinkle.initialize(mode='http', ...)
# Client
client = init_twinkle_client(base_url='http://localhost:8000')
Customizable Components
| Component | Base Class | Description |
|---|---|---|
| Loss | twinkle.loss.Loss | Training loss functions |
| Metric | twinkle.metric.Metric | Evaluation metrics |
| Patch | twinkle.patch.Patch | Model training fixes |
| Preprocessor | twinkle.preprocessor.Preprocessor | Data ETL |
| Filter | twinkle.preprocessor.Filter | Data validation |
| InputProcessor | twinkle.processor.InputProcessor | Task-specific input handling |
| Model | twinkle.model.TwinkleModel | Large model wrapper |
| Sampler | twinkle.sampler.Sampler | Sampling strategies |
| Reward | twinkle.reward.Reward | RL reward functions |
| Advantage | twinkle.advantage.Advantage | Advantage estimation |
| Template | twinkle.template.Template | Tokenization templates |
| CheckpointEngine | twinkle.checkpoint_engine.CheckpointEngine | Weight synchronization |
Design Principles
Twinkle adheres to these core principles:
- Retain Training Loop Control — Developers can clearly see and control forward, backward, and step operations
- Highly Cohesive Components — Each component has clear responsibilities and works independently
- Hidden Distributed Complexity — Same code runs on single GPU, torchrun, or Ray clusters
- Production-Grade Deployment — Built-in multi-tenancy, HTTP services, and weight synchronization