Multi-Tenancy
Twinkle supports simultaneous multi-tenant training on a shared base model, dramatically reducing deployment costs.
Overview
Using a LoRA Pool + Tenant Application architecture, Twinkle enables up to N tenants to train in parallel with complete isolation.
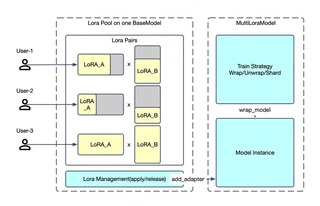
Key Benefits
- Resource Efficiency: Single base model deployment serves multiple tenants
- Isolation: Each tenant has separate LoRA weights, optimizer states, and configurations
- Flexibility: Heterogeneous training configurations (different ranks, optimizers, loss functions)
- Concurrent Access: Multiple tenants train simultaneously without interference
Tenant Configurations
Each tenant can have unique configurations:
| Tenant | Dataset | LoRA Rank | Training Type |
|---|---|---|---|
| A | Local private data | 8 | SFT |
| B | Open-source dataset | 32 | Pre-training |
| C | RL dataset | 16 | GRPO |
| D | Inference only | - | Log probability |
Server Setup
Start the multi-tenant training server:
# server.py
import twinkle
from twinkle import DeviceGroup, DeviceMesh
device_groups = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
DeviceGroup(name='utility', ranks=0, device_type='cpu'),
]
twinkle.initialize(mode='http', groups=device_groups)
Client Training
Tenant A: SFT Training
from twinkle_client import init_twinkle_client
from twinkle_client.model import MultiLoraTransformersModel
from peft import LoraConfig
client = init_twinkle_client(base_url='http://server:8000')
model = MultiLoraTransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.add_adapter_to_model('tenant_a', LoraConfig(r=8, lora_alpha=32))
model.set_loss('CrossEntropyLoss')
model.set_optimizer('AdamW', lr=1e-4)
for batch in dataloader:
model.forward_backward(inputs=batch)
model.step()
Tenant B: RL Training
model = MultiLoraTransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.add_adapter_to_model('tenant_b', LoraConfig(r=32, lora_alpha=64))
model.set_loss('GRPOLoss', epsilon=0.2)
model.set_optimizer('AdamW', lr=1e-5)
sampler = vLLMSampler(model_id='ms://Qwen/Qwen3.5-4B')
for batch in dataloader:
# Sample completions
responses = sampler.sample(inputs=batch, adapter_uri=adapter_path)
# Compute rewards and advantages
rewards = reward_fn(responses)
advantages = advantage_fn(rewards)
# Train
model.forward_backward(inputs=responses, advantages=advantages)
model.step()
Tenant C: Inference Only
sampler = vLLMSampler(model_id='ms://Qwen/Qwen3.5-4B')
# Use a specific adapter
responses = sampler.sample(
inputs=prompts,
sampling_params={'max_tokens': 1024},
adapter_uri='path/to/adapter'
)
Tinker API Compatibility
Twinkle also supports Tinker-compatible APIs:
from tinker import ServiceClient, types
service_client = ServiceClient(
base_url='http://server:8000',
api_key='your-api-key'
)
training_client = service_client.create_lora_training_client(
base_model='Qwen/Qwen3.5-4B',
rank=16
)
# Training loop
for batch in dataloader:
input_datum = [input_feature_to_datum(f) for f in batch]
fwdbwd_future = training_client.forward_backward(input_datum, 'cross_entropy')
optim_future = training_client.optim_step(types.AdamParams(learning_rate=1e-4))
fwdbwd_future.result()
optim_future.result()
# Save checkpoint
training_client.save_state('checkpoint-name').result()
Resource Management
Adapter Lifecycle
- Creation: Adapter created when
add_adapter_to_modelis called - Training: Adapter weights updated during training
- Saving:
model.save()persists adapter to disk - Loading: Sampler loads adapter via
adapter_uri - Cleanup: Adapter released when training completes
Weight Synchronization
For RL training, sync model weights to sampler:
# Save current adapter weights
adapter_path = model.save(name='step-100', save_optimizer=False)
# Sampler uses the saved weights
responses = sampler.sample(inputs=batch, adapter_uri=adapter_path)
Best Practices
- Unique Adapter Names: Use distinct names for each tenant’s adapter
- Resource Limits: Configure GPU memory limits per tenant
- Checkpoint Management: Implement cleanup policies for old checkpoints
- Monitoring: Track per-tenant metrics for resource allocation