Multi-Tenancy Training
Mar 1, 2026
·
1 min read
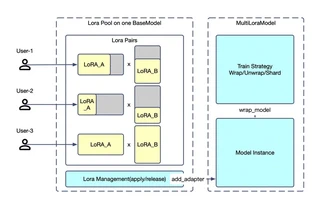 Twinkle Multi-Tenancy Architecture
Twinkle Multi-Tenancy ArchitectureTwinkle supports simultaneous multi-tenant training on a shared base model, dramatically reducing deployment costs while enabling flexible configurations per tenant.
Key Features
- Resource Efficiency: Single base model serves multiple concurrent training sessions
- Complete Isolation: Each tenant has separate LoRA weights, optimizers, and loss functions
- Heterogeneous Configs: Different ranks, learning rates, and training objectives per tenant
- Concurrent Access: No interference between training sessions
Use Cases
| Tenant | Dataset | LoRA Rank | Training Type |
|---|---|---|---|
| A | Private data | 8 | SFT |
| B | Open-source | 32 | Pre-training |
| C | RL dataset | 16 | GRPO |
| D | Inference | - | Log probability |
Example
from twinkle_client import init_twinkle_client
from twinkle_client.model import MultiLoraTransformersModel
client = init_twinkle_client(base_url='http://server:8000')
model = MultiLoraTransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.add_adapter_to_model('tenant_a', LoraConfig(r=8))
model.set_loss('GRPOLoss', epsilon=0.2)
for batch in dataloader:
model.forward_backward(inputs=batch)
model.step()

Authors
AI Research & Engineering
Building open-source AI infrastructure for the community. Twinkle is our lightweight LLM training framework.