Ray Distributed Training
Mar 1, 2026
·
1 min read
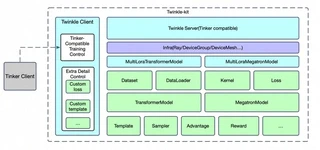 Twinkle Ray Training Architecture
Twinkle Ray Training ArchitectureTwinkle enables seamless scaling from single GPU training to multi-node Ray clusters. The same training code runs across different backends with minimal configuration changes.
Key Features
- Unified API: Same training code works with torchrun, Ray, and HTTP modes
- Flexible Parallelism: Support for FSDP, tensor parallelism, pipeline parallelism
- Model-Sampler Coordination: Efficient weight synchronization for RL training
- Dynamic Resource Management: Ray handles GPU allocation automatically
Example
import twinkle
from twinkle import DeviceMesh, DeviceGroup
device_groups = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
]
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_groups)
# Training code remains the same as single GPU!
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B', remote_group='model')

Authors
AI Research & Engineering
Building open-source AI infrastructure for the community. Twinkle is our lightweight LLM training framework.