全
主流模型 LLM · VLM · MoE
3
运行模式 本地 · Ray · HTTP
∞
多租户 并行 LoRA 训练
<5分钟
上手时间 pip install 即用
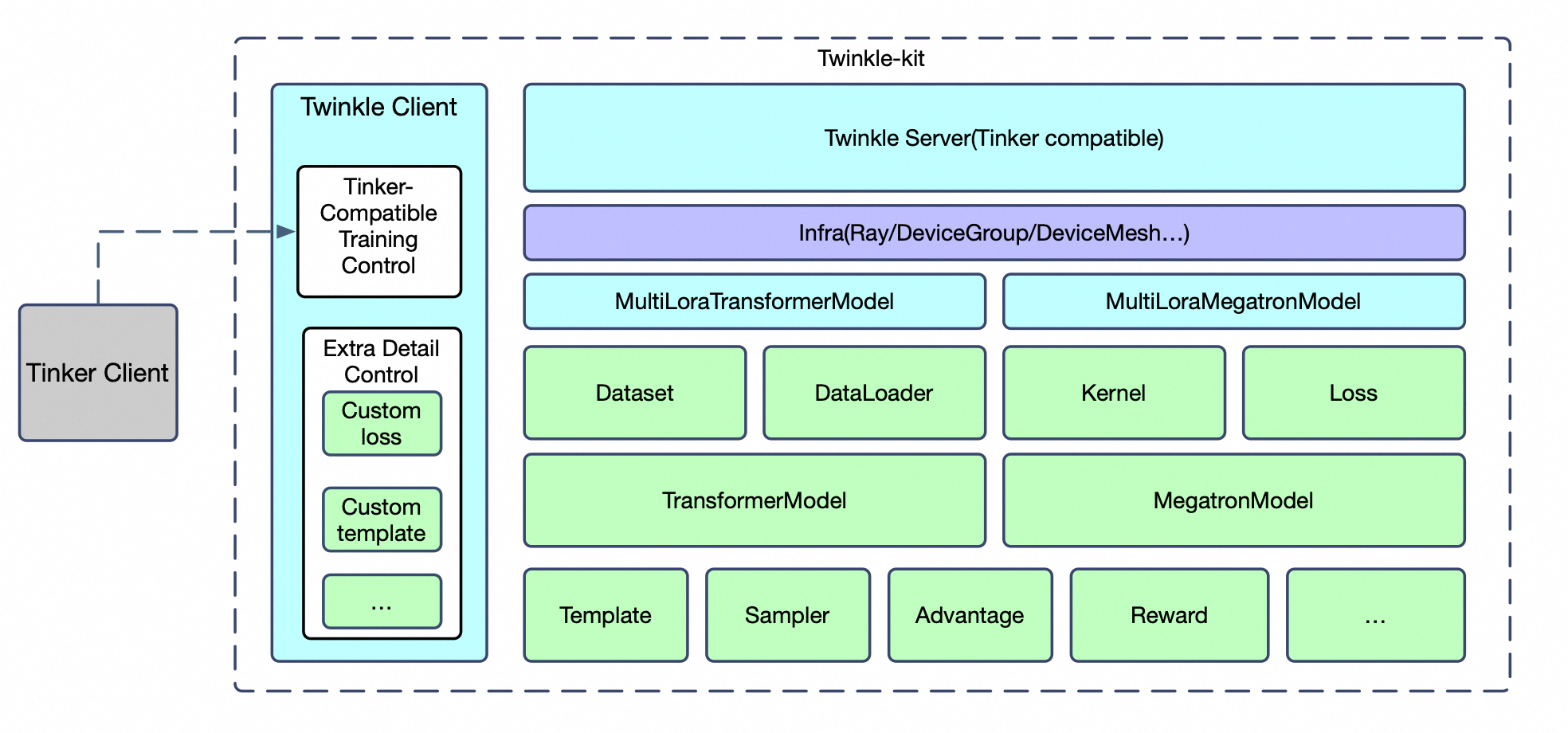
什么是 Twinkle?
Twinkle 是一个 客户端-服务端 LLM 训练框架,将训练什么与如何训练分离。
使用简洁的 Python API 编写训练逻辑,然后部署到任何地方 —— 本地 torchrun、
Ray 集群,或无服务器 Training-as-a-Service。
由 ModelScope 的 ms-swift 团队构建。
🔌 双 API
原生 Twinkle API 功能完整,Tinker 兼容 API 便于迁移
🧩 模块化
15+ 组件:Dataset、Template、Model、Sampler、Loss、Reward、Metric...
🔀 后端无关
Transformers 或 Megatron —— 一行配置切换
为什么选择 Twinkle?
无需重写即可扩展
相同代码运行在笔记本和千卡集群。从 torchrun 切换到 Ray 或 HTTP 部署,无需修改训练逻辑。
内置多租户
一个基座模型同时训练 N 个不同的 LoRA。每个租户拥有独立的优化器、数据流水线和损失函数 —— 只共享算力。
你掌控训练循环
没有隐藏的魔法。查看和控制每一个 forward、backward 和优化器步骤。自由调试,完全定制。
训练即服务
为生产级 TaaS 部署而构建,支持自动化集群管理、动态扩缩容和企业级多租户隔离。
全训练方法
SFT、预训练、GRPO、GKD 等。稠密模型和 MoE 架构。完整的 FSDP、张量并行、流水线并行支持。
广泛的模型支持
Qwen 3.5/3/2.5、DeepSeek R1/V2、GLM-4、InternLM2 等。同时支持 Hugging Face 和魔搭模型库。
20 行代码开始训练
import twinkle
from peft import LoraConfig
from twinkle import DeviceGroup
from twinkle.dataloader import DataLoader
from twinkle.dataset import Dataset, DatasetMeta
from twinkle.model import TransformersModel
# 选择运行模式: 'local' (torchrun), 'ray', 或 'http'
twinkle.initialize(mode='ray', groups=[DeviceGroup(name='default', ranks=8)])
# 准备数据 — 支持魔搭和 Hugging Face
dataset = Dataset(dataset_meta=DatasetMeta('ms://swift/self-cognition'))
dataset.set_template('Template', model_id='ms://Qwen/Qwen3.5-4B')
dataset.encode()
# 创建带 LoRA 的模型
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B', remote_group='default')
model.add_adapter_to_model('default', LoraConfig(r=8, lora_alpha=32))
model.set_optimizer(optimizer_cls='AdamW', lr=1e-4)
# 训练 — 你掌控循环
for batch in DataLoader(dataset=dataset, batch_size=8):
model.forward_backward(inputs=batch)
model.clip_grad_and_step()
model.save('my-finetuned-model')
多租户:N 个任务,1 个基座模型
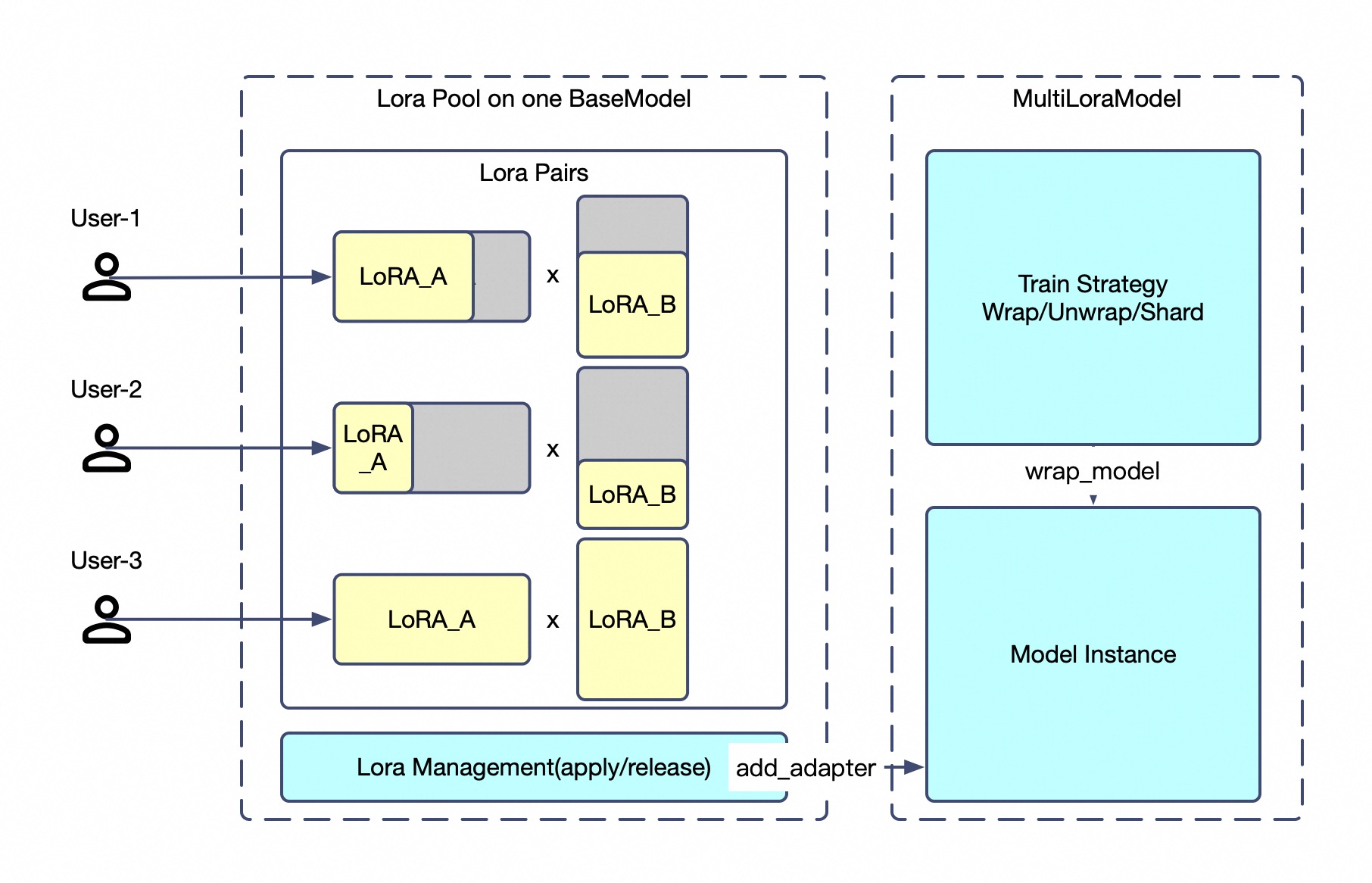
在共享部署上运行完全不同的训练任务:
| 租户 | 配置 | 任务 |
|---|---|---|
| A | LoRA r=8, 私有数据 | SFT 微调 |
| B | LoRA r=32, Hub 数据集 | 增量预训练 |
| C | GRPO 损失 + Sampler | 强化学习 |
| D | 推理模式 | 对数概率计算 |
每个租户完全隔离 —— 不同的优化器、数据流水线、损失函数。 只共享基座模型的算力。检查点自动同步到魔搭或 Hugging Face。
支持的模型
支持主流 LLM · NVIDIA · 昇腾 NPU · SFT / PT / GRPO / GKD