架构
Twinkle 采用解耦的客户端-服务端架构,为最大灵活性和可扩展性而设计。
系统概览
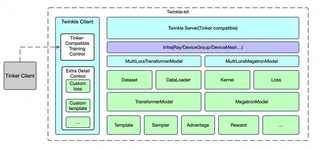
核心设计
Twinkle 的架构围绕三个基本原则构建:
- 组件解耦 — 每个组件(Dataset、Model、Sampler、Loss)独立运作,通过标准化接口通信
- 统一 API — 同一套训练代码可以在不同后端(torchrun、Ray、HTTP)上运行,只需极少改动
- 多租户 — 多个用户可以在共享基座模型上同时训练,配置完全隔离
客户端-服务端模型
客户端提供两条集成路径:
- Twinkle 原生 API — 与服务端接口一致的原生 API,端到端无缝衔接
- Tinker 兼容 API — 完整支持 Tinker API,开发者可以用 Tinker 客户端对接 Twinkle 后端
双路径设计确保无论使用哪种 API,都能访问 Twinkle 的训练服务。
核心组件
| 组件 | 描述 |
|---|---|
| Dataset | 数据加载与预处理,集成 ModelScope/HuggingFace |
| Template | 针对不同模型架构的编解码模板 |
| DataLoader | 支持 device mesh 感知的分布式数据加载 |
| Preprocessor | 数据 ETL,转换为标准格式 |
| Model | 大模型封装,支持 Transformers 和 Megatron |
| Sampler | 采样逻辑(如基于 vLLM),用于 RL 训练 |
| Loss | 可定制的损失函数(CrossEntropy、GRPO 等) |
| Reward | 强化学习的奖励函数 |
| Advantage | 策略优化的优势估计 |
DeviceGroup 与 DeviceMesh
DeviceGroup 和 DeviceMesh 是 Twinkle 分布式架构的核心:
import twinkle
from twinkle import DeviceMesh, DeviceGroup
# 定义资源组
device_group = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
]
# 定义并行拓扑
device_mesh = DeviceMesh.from_sizes(pp_size=2, tp_size=2, dp_size=2)
# 初始化
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_group)
DeviceGroup
定义训练所需的资源组数量。组件可以通过选择资源组实现远程执行:
model = TransformersModel(
model_id='Qwen/Qwen3.5-4B',
remote_group='model',
device_mesh=device_mesh
)
DeviceMesh
指定资源组内组件的并行拓扑:
- pp_size — 流水线并行
- tp_size — 张量并行
- dp_size — 数据并行
- fsdp_size — 全分片数据并行
- cp_size — 上下文并行
多租户架构
Twinkle 支持在共享基座模型上同时进行多租户训练:
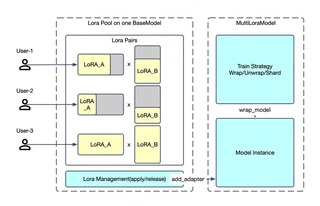
采用 LoRA Pool + 租户应用 架构:
- 租户 A:本地私有数据集,LoRA rank=8,SFT 训练
- 租户 B:开源数据集,LoRA rank=32,预训练
- 租户 C:GRPO 损失计算 + 采样
- 租户 D:对数概率推理
所有任务可并发执行,因为 Model 和 Sampler 被设计为任务无关的组件。
运行模式
单卡
无需分布式配置,直接训练:
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.forward_backward(inputs=batch)
torchrun 模式
使用 PyTorch torchrun 进行分布式训练:
twinkle.initialize(mode='local', global_device_mesh=device_mesh)
torchrun --nproc_per_node=8 train.py
Ray 模式
跨 Ray 集群的分布式训练:
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_group)
HTTP 模式
训练即服务部署:
# 服务端
twinkle.initialize(mode='http', ...)
# 客户端
client = init_twinkle_client(base_url='http://localhost:8000')
可定制组件
| 组件 | 基类 | 描述 |
|---|---|---|
| Loss | twinkle.loss.Loss | 训练损失函数 |
| Metric | twinkle.metric.Metric | 评估指标 |
| Patch | twinkle.patch.Patch | 模型训练补丁 |
| Preprocessor | twinkle.preprocessor.Preprocessor | 数据 ETL |
| Filter | twinkle.preprocessor.Filter | 数据校验 |
| InputProcessor | twinkle.processor.InputProcessor | 任务输入处理 |
| Model | twinkle.model.TwinkleModel | 大模型封装 |
| Sampler | twinkle.sampler.Sampler | 采样策略 |
| Reward | twinkle.reward.Reward | RL 奖励函数 |
| Advantage | twinkle.advantage.Advantage | 优势估计 |
| Template | twinkle.template.Template | 分词模板 |
| CheckpointEngine | twinkle.checkpoint_engine.CheckpointEngine | 权重同步 |
设计原则
Twinkle 遵循以下核心原则:
- 保留训练循环控制权 — 开发者可以清晰地查看和控制 forward、backward 和 step 操作
- 高内聚组件 — 每个组件职责明确,可独立工作
- 隐藏分布式复杂性 — 同一代码可运行在单卡、torchrun 或 Ray 集群
- 生产级部署 — 内置多租户、HTTP 服务和权重同步