多租户
Twinkle 支持在共享基座模型上同时进行多租户训练,大幅降低部署成本。
概述
采用 LoRA Pool + 租户应用 架构,Twinkle 支持最多 N 个租户 并行训练,完全隔离。
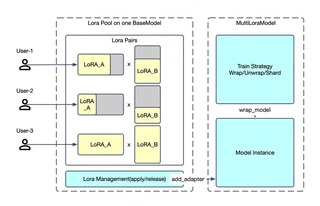
核心优势
- 资源高效:单一基座模型部署服务多个租户
- 完全隔离:每个租户拥有独立的 LoRA 权重、优化器状态和配置
- 异构配置:每个租户可使用不同的 rank、优化器、损失函数
- 并发访问:多个租户同时训练,互不干扰
租户配置
每个租户可以有独立的配置:
| 租户 | 数据集 | LoRA Rank | 训练类型 |
|---|---|---|---|
| A | 本地私有数据 | 8 | SFT |
| B | 开源数据集 | 32 | 预训练 |
| C | RL 数据 | 16 | GRPO |
| D | 仅推理 | - | 对数概率 |
服务端配置
启动多租户训练服务端:
# server.py
import twinkle
from twinkle import DeviceGroup, DeviceMesh
device_groups = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
DeviceGroup(name='utility', ranks=0, device_type='cpu'),
]
twinkle.initialize(mode='http', groups=device_groups)
客户端训练
租户 A:SFT 训练
from twinkle import init_twinkle_client
from twinkle_client.model import MultiLoraTransformersModel
from peft import LoraConfig
client = init_twinkle_client(base_url='http://server:8000')
model = MultiLoraTransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.add_adapter_to_model('tenant_a', LoraConfig(r=8, lora_alpha=32))
model.set_template('Qwen3_5Template')
model.set_processor('InputProcessor', padding_side='right')
model.set_loss('CrossEntropyLoss')
model.set_optimizer('Adam', lr=1e-4)
for batch in dataloader:
model.forward_backward(inputs=batch)
model.clip_grad_and_step()
租户 B:RL 训练
from twinkle_client.sampler import vLLMSampler
model = MultiLoraTransformersModel(model_id='ms://Qwen/Qwen3.5-4B')
model.add_adapter_to_model('tenant_b', LoraConfig(r=32, lora_alpha=64))
model.set_loss('GRPOLoss', epsilon=0.2)
model.set_optimizer('Adam', lr=1e-5)
model.set_template('Qwen3_5Template', model_id='ms://Qwen/Qwen3.5-4B')
sampler = vLLMSampler(model_id='ms://Qwen/Qwen3.5-4B')
sampler.set_template('Qwen3_5Template', model_id='ms://Qwen/Qwen3.5-4B')
for batch in dataloader:
# 采样生成
responses = sampler.sample(inputs=batch, adapter_uri=adapter_path)
# 计算奖励和优势
rewards = reward_fn(responses)
advantages = advantage_fn(rewards)
# 训练
model.forward_backward(inputs=responses, advantages=advantages)
model.clip_grad_and_step()
租户 C:仅推理
sampler = vLLMSampler(model_id='ms://Qwen/Qwen3.5-4B')
# 使用指定适配器
responses = sampler.sample(
inputs=prompts,
sampling_params={'max_tokens': 1024},
adapter_uri='path/to/adapter'
)
Tinker API 兼容
Twinkle 同样支持 Tinker 兼容 API:
from tinker import ServiceClient, types
service_client = ServiceClient(
base_url='http://server:8000',
api_key='your-api-key'
)
training_client = service_client.create_lora_training_client(
base_model='Qwen/Qwen3.5-4B',
rank=16
)
# 训练循环
for batch in dataloader:
input_datum = [input_feature_to_datum(f) for f in batch]
fwdbwd_future = training_client.forward_backward(input_datum, 'cross_entropy')
optim_future = training_client.optim_step(types.AdamParams(learning_rate=1e-4))
fwdbwd_future.result()
optim_future.result()
# 保存检查点
training_client.save_state('checkpoint-name').result()
资源管理
适配器生命周期
- 创建:调用
add_adapter_to_model时创建适配器 - 训练:训练过程中更新适配器权重
- 保存:
model.save()将适配器持久化到磁盘 - 加载:Sampler 通过
adapter_uri加载适配器 - 清理:训练完成后释放适配器
权重同步
用于 RL 训练时同步模型权重到 sampler:
# 保存当前适配器权重
adapter_path = model.save(name='step-100', save_optimizer=False)
# Sampler 使用保存的权重
responses = sampler.sample(inputs=batch, adapter_uri=adapter_path)
最佳实践
- 唯一适配器名称:每个租户的适配器使用不同名称
- 资源限制:为每个租户配置 GPU 显存上限
- 检查点管理:实施旧检查点清理策略
- 监控:跟踪每个租户的指标以优化资源分配