Ray 分布式训练
2026年3月1日
·
1 分钟阅读时长
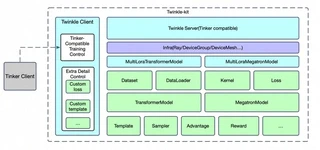 Twinkle Ray 训练架构
Twinkle Ray 训练架构Twinkle 支持从单卡训练无缝扩展到多节点 Ray 集群。相同的训练代码可以在不同后端运行,只需最少的配置更改。
核心特性
- 统一 API: 相同训练代码适用于 torchrun、Ray 和 HTTP 模式
- 灵活并行: 支持 FSDP、张量并行、流水线并行
- 模型-采样器协调: 高效的 RL 训练权重同步
- 动态资源管理: Ray 自动处理 GPU 分配
示例
import twinkle
from twinkle import DeviceMesh, DeviceGroup
device_groups = [
DeviceGroup(name='model', ranks=4, device_type='cuda'),
DeviceGroup(name='sampler', ranks=4, device_type='cuda'),
]
twinkle.initialize(mode='ray', nproc_per_node=8, groups=device_groups)
# 训练代码与单卡完全相同!
model = TransformersModel(model_id='ms://Qwen/Qwen3.5-4B', remote_group='model')

Authors
AI Research & Engineering
Building open-source AI infrastructure for the community. Twinkle is our lightweight LLM training framework.