Welcome to Trinity-RFT’s documentation!#
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models#
🚀 News#
[2025-09] ✨ [Release Notes] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
[2025-08] 🎵 Introducing CHORD: dynamic SFT + RL integration for advanced LLM fine-tuning (paper).
[2025-08] [Release Notes] Trinity-RFT v0.2.1 released.
[2025-07] [Release Notes] Trinity-RFT v0.2.0 released.
[2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: link.
[2025-06] [Release Notes] Trinity-RFT v0.1.1 released.
[2025-05] [Release Notes] Trinity-RFT v0.1.0 released, plus technical report.
[2025-04] Trinity-RFT open sourced.
💡 What is Trinity-RFT?#
Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It supports a wide range of applications and provides a unified platform for RL research in the era of experience.
The RFT process is modularized into three core components:
Explorer: Handles agent-environment interaction
Trainer: Manages model training
Buffer: Manages data storage and processing

✨ Key Features#
Flexible RFT Modes:
Supports synchronous/asynchronous, on-policy/off-policy, and online/offline training. Rollout and training can run separately and scale independently across devices.

Agent Framework Compatible Workflows:
Supports both concatenated and general multi-turn agentic workflows. Automatically collects training data from model API clients (e.g., OpenAI) and is compatible with agent frameworks like AgentScope.

Powerful Data Pipelines:
Enables pipeline processing of rollout and experience data, supporting active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
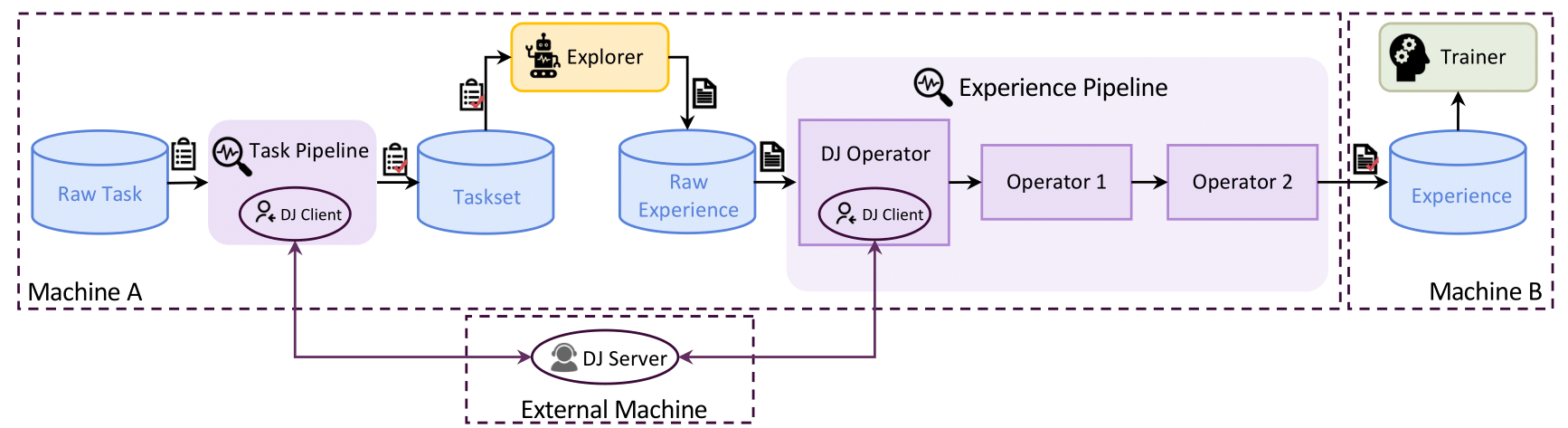
User-Friendly Design:
Modular, decoupled architecture for easy adoption and development. Rich graphical user interfaces enable low-code usage.

🛠️ What can I use Trinity-RFT for?#
Train agent applications with RL and minimal migration cost
Rapid RL algorithm design and validation
Develop custom RL algorithms (loss design, sampling strategy, etc.) in compact, plug-and-play classes (example).
Custom datasets and data pipelines for RFT
Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios (example).
Acknowledgements#
This project is built upon many excellent open-source projects, including:
verl and PyTorch’s FSDP for LLM training;
vLLM for LLM inference;
Data-Juicer for data processing pipelines;
AgentScope for agentic workflow;
Ray for distributed systems;
we have also drawn inspirations from RL frameworks like OpenRLHF, TRL and ChatLearn;
……
Citation#
@misc{trinity-rft,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
year={2025},
eprint={2505.17826},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.17826},
}