Off-Policy RFT#
让我们继续使用 之前的 GSM8k 例子,区别在于从 on-policy 模式切换到 off-policy 模式。
在这个例子中,我们考虑一个名为 OPMD 的 off-policy 强化学习算法。
该算法的设计与分析详见我们的论文中的 Section 2.2。
本例子对应的配置文件为 opmd_gsm8k.yaml。
要尝试 OPMD 算法,请运行:
trinity run --config examples/opmd_gsm8k/opmd_gsm8k.yaml
注意,在此配置文件中,sync_interval 被设置为 10,也就是说,explorer 和 trainer 每 10 个训练步骤才同步一次模型权重,这导致了一个具有挑战性的 off-policy 场景(在 RFT 过程中可能出现剧烈的分布偏移)。
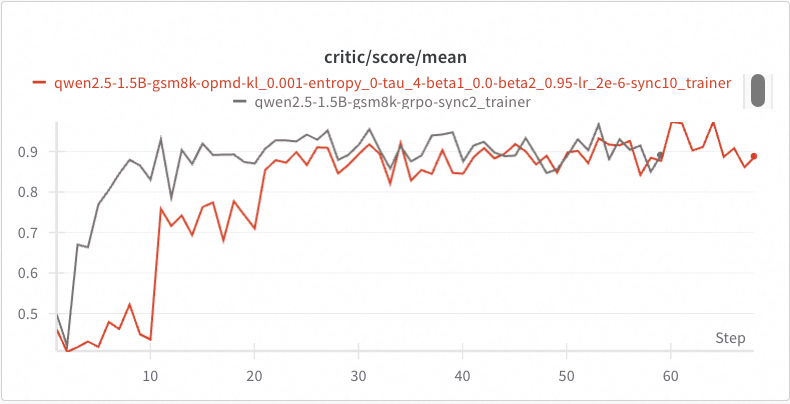
下图中的红色曲线展示了 OPMD 训练过程中 explorer 取得的分数。
由于 explorer 的模型权重在前 10 步保持不变,其得分也保持平稳。
然后,在第 10 步结束时,explorer 和 trainer 完成模型权重同步,我们在第 11 步观察到得分突然上升,这表明前 10 步的 off-policy 学习是有效的。
类似的性能提升在第 21 步再次出现,最终收敛的得分与在准在线策略情况下(sync_interval=2)GRPO 所达到的结果相当。
对 off-policy 强化学习算法感兴趣的读者,可以参考我们的论文。