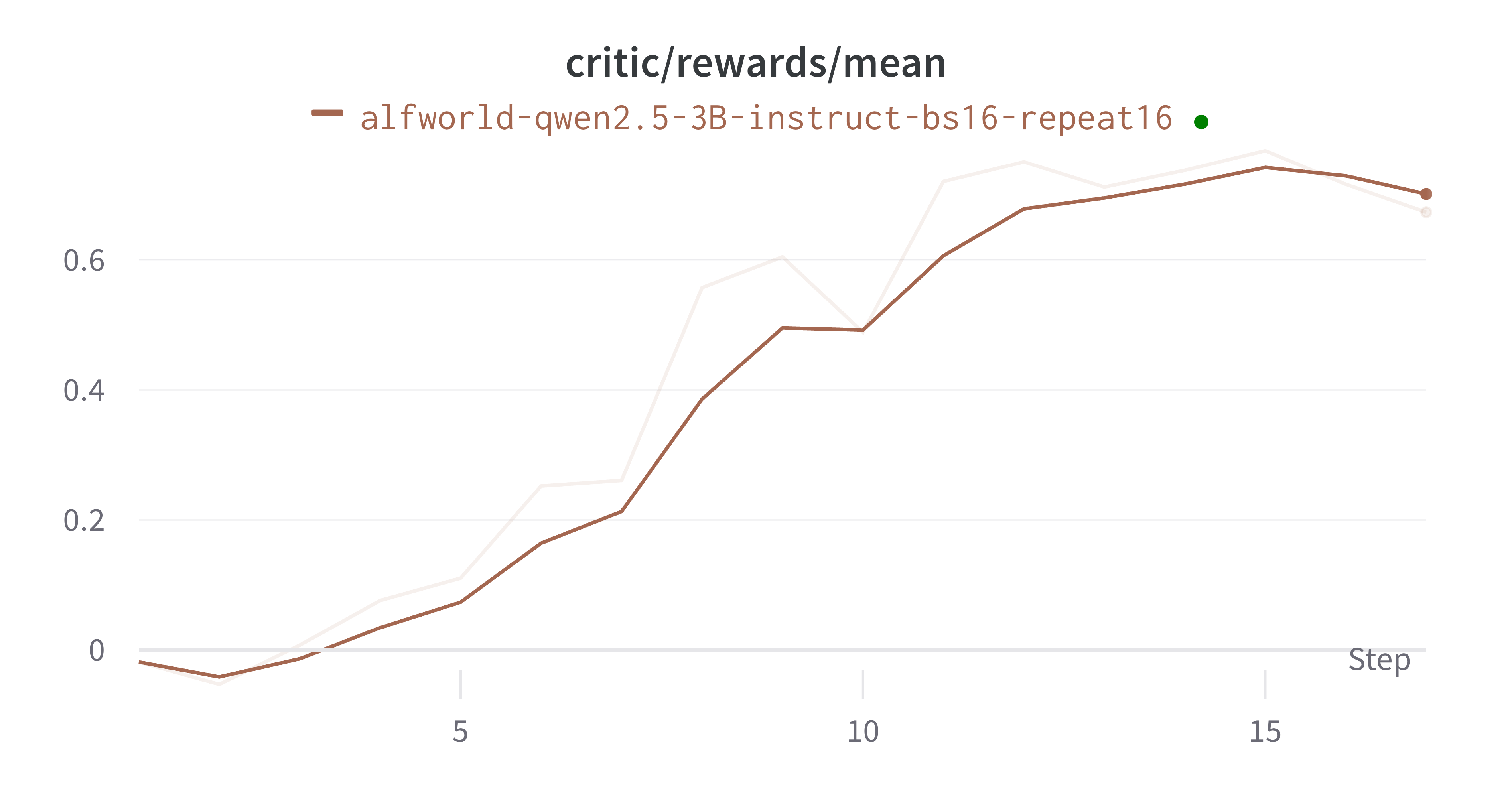
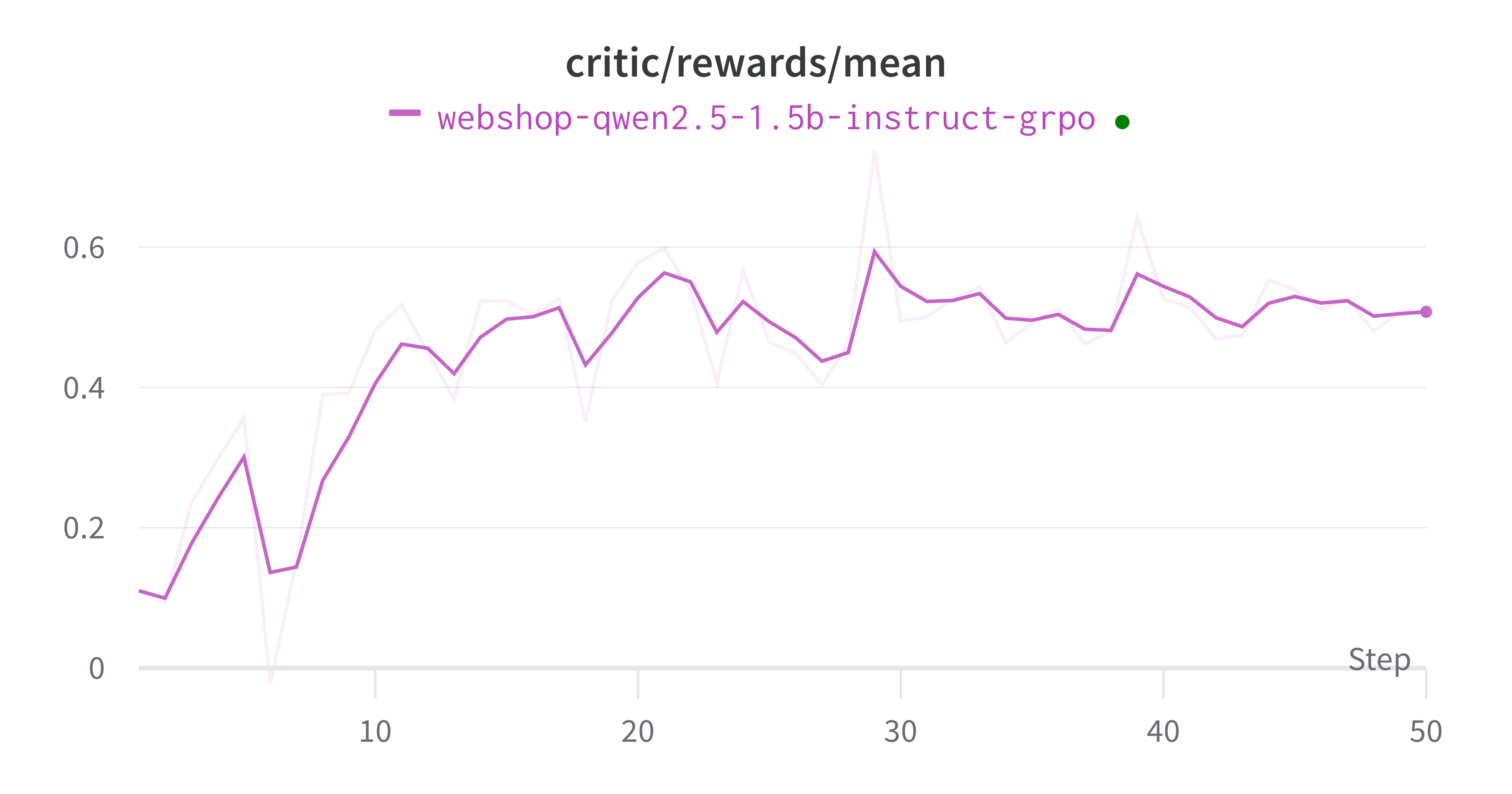
多轮对话拼接任务#
在 Trinity-RFT 中,我们支持与环境进行多轮交互的 Agentic RL。
Trinity 的解耦设计允许你通过 Workflow 配置,轻松定义环境与 Agent(智能体)之间的自定义交互方式,以收集用于 RL 训练的相应 experiences。
接下来,我们将以 ALFworld 和 WebShop 两个多轮环境为例,展示多轮交互的实现方式。
以下是运行这两个示例的逐步说明。
第一步:环境与数据准备#
环境准备#
要运行 ALFworld 和 WebShop 环境,你需要先配置相应的环境。
ALFworld 是一个基于文本的交互式环境,模拟家庭场景。Agent 需要理解自然语言指令,并在虚拟家庭环境中完成诸如寻找物品、移动物体和操作设备等各种家务任务。
WebShop 是一个模拟在线购物的环境,Agent 在此学习根据用户需求进行购物。该平台允许 Agent 浏览商品、比较选项并做出购买决策,模拟真实世界的电商交互。
准备 ALFWorld 环境
使用 pip 安装:
pip install alfworld[full]设置路径:
export ALFWORLD_DATA=/path/to/alfworld/data下载环境:
alfworld-download
现在你可以在 $ALFWORLD_DATA 目录下找到环境,并继续后续步骤。
准备 WebShop 环境
安装 Python 3.8.13
安装 Java
下载源代码:
git clone https://github.com/princeton-nlp/webshop.git webshop创建虚拟环境:
conda create -n webshop python=3.8.13并激活:conda activate webshop通过
setup.sh脚本在webshop虚拟环境中安装依赖:./setup.sh [-d small|all]
接下来,你可以继续执行后续步骤。
你可以参考它们的原始项目以获取更多细节。
数据准备#
我们的数据集遵循 Huggingface datasets 库的格式,因此我们需要将环境数据集进行相应转换。
只需查看数据准备脚本并运行以下命令:
# 对于 ALFworld 环境
python examples/grpo_alfworld/get_alfworld_data.py
# 对于 WebShop 环境
python examples/grpo_webshop/get_webshop_data.py
任务被描述为一个环境,而不是单个提示。
对于 ALFworld 环境,任务描述是
game_file文件路径。对于 Webshop 环境,任务描述是环境的
task_id,它作为 session_id 传递给环境用于重置。
第二步:配置准备并运行实验#
你可以参考 快速开始 来设置配置和其他内容。默认配置文件分别为 alfworld.yaml 和 webshop.yaml。
你可以适当修改配置并运行实验!
# 对于 ALFworld 环境
trinity run --config examples/grpo_alfworld/alfworld.yaml
# 对于 WebShop 环境
trinity run --config examples/grpo_webshop/webshop.yaml
进阶:如何构建你自己的环境#
我们提供了一种简便方式,让你通过创建新的 workflow 来构建自己的环境流程。
请参考 trinity/common/workflows/envs/alfworld/alfworld_workflow.py 示例,了解如何构建一个多轮 workflow。
你可以使用消息格式与环境交互,并调用 self.process_messages_to_experience 函数将消息和奖励转换为我们所需的 experience,然后发送到缓冲区。
class AlfworldWorkflow(MultiTurnWorkflow):
"""A workflow for alfworld task."""
...
def generate_env_inference_samples(self, env, rollout_num) -> List[Experience]:
print("Generating env inference samples...")
experience_list = []
for i in range(rollout_num):
observation, info = env.reset()
final_reward = -0.1
memory = []
memory.append({"role": "system", "content": AlfWORLD_SYSTEM_PROMPT})
for r in range(self.max_env_steps):
format_obs = format_observation(observation)
memory = memory + [{"role": "user", "content": format_obs}]
response_text = self.get_model_response_text(memory)
memory.append({"role": "assistant", "content": response_text})
action = parse_action(response_text)
observation, reward, done, info = env.step(action)
if done:
final_reward = reward
break
experience = self.process_messages_to_experience(
memory, final_reward, {"env_rounds": r, "env_done": 1 if done else 0}
)
experience_list.append(experience)
# Close the env to save cpu memory
env.close()
return experience_list
def run(self) -> List[Experience]:
...
game_file_path = self.task_desc
rollout_n = self.repeat_times
...
env = create_environment(game_file_path)
return self.generate_env_inference_samples(env, rollout_n)
同时,记得注册你的 workflow:
@WORKFLOWS.register_module("alfworld_workflow")
class AlfworldWorkflow(MultiTurnWorkflow):
"""A workflow for alfworld task."""
...
并在初始化文件 trinity/common/workflows/__init__.py 中包含它:
# -*- coding: utf-8 -*-
"""Workflow module"""
from .workflow import WORKFLOWS, MathWorkflow, SimpleWorkflow
+from .envs.alfworld.alfworld_workflow import AlfworldWorkflow
__all__ = [
"WORKFLOWS",
"SimpleWorkflow",
"MathWorkflow",
+ "AlfworldWorkflow",
]
这样就完成了!整个过程非常简单😄,并且在这两个环境中的训练过程都能收敛。