Quick Start¶
Dataset Configuration¶
DJ supports various dataset input types, including local files, remote datasets like huggingface; it also supports data validation and data mixture.
Two ways to configure a input file
Simple scenarios, single path for local/HF file
dataset_path: '/path/to/your/dataset' # path to your dataset directory or file
advanced method, supports sub-configuration items and more features
dataset:
configs:
- type: 'local'
path: 'path/to/your/dataset' # path to your dataset directory or file
Refer to Dataset Configuration Guide for more details.
Data Processing¶
Run
process_data.pytool ordj-processcommand line tool with your config as the argument to process your dataset.
# only for installation from source
python tools/process_data.py --config configs/demo/process.yaml
# use command line tool
dj-process --config configs/demo/process.yaml
Note: For some operators that involve third-party models or resources that are not stored locally on your computer, it might be slow for the first running because these ops need to download corresponding resources into a directory first. The default download cache directory is
~/.cache/data_juicer. Change the cache location by setting the shell environment variable,DATA_JUICER_CACHE_HOMEto another directory, and you can also changeDATA_JUICER_MODELS_CACHEorDATA_JUICER_ASSETS_CACHEin the same way:Note: When using operators with third-party models, it’s necessary to declare the corresponding
mem_requiredin the configuration file (you can refer to the settings in theconfig_all.yamlfile). During runtime, Data-Juicer will control the number of processes based on memory availability and the memory requirements of the operator models to achieve better data processing efficiency. When running with CUDA environments, if the mem_required for an operator is not declared correctly, it could potentially lead to a CUDA Out of Memory issue.
# cache home
export DATA_JUICER_CACHE_HOME="/path/to/another/directory"
# cache models
export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
# cache assets
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
Flexible Programming Interface: We provide various simple interfaces for users to choose from as follows.
#... init op & dataset ...
# Chain call style, support single operator or operator list
dataset = dataset.process(op)
dataset = dataset.process([op1, op2])
# Functional programming style for quick integration or script prototype iteration
dataset = op(dataset)
dataset = op.run(dataset)
Distributed Data Processing¶
We have now implemented multi-machine distributed data processing based on RAY. The corresponding demos can be run using the following commands:
# Run text data processing
python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
# Run video data processing
python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
To run data processing across multiple machines, it is necessary to ensure that all distributed nodes can access the corresponding data paths (for example, by mounting the respective data paths on a file-sharing system such as NAS).
The deduplication operators for RAY mode are different from the single-machine version, and all those operators are prefixed with
ray, e.g.ray_video_deduplicatorandray_document_deduplicator.More details can be found in the doc for distributed processing.
Users can also opt not to use RAY and instead split the dataset to run on a cluster with Slurm. In this case, please use the default Data-Juicer without RAY. Aliyun PAI-DLC supports the RAY framework, Slurm framework, etc. Users can directly create RAY jobs and Slurm jobs on the DLC cluster.
Data Analysis¶
Run
analyze_data.pytool ordj-analyzecommand line tool with your config as the argument to analyze your dataset.The analyzer will produce the overall distribution of the stats computed by the OPs for the whole dataset, the detailed distribution of each type of stats, and the correlation analysis among stats from different OPs.
# only for installation from source
python tools/analyze_data.py --config configs/demo/analyzer.yaml
# use command line tool
dj-analyze --config configs/demo/analyzer.yaml
# you can also use auto mode to avoid writing a recipe. It will analyze a small
# part (e.g. 1000 samples, specified by argument `auto_num`) of your dataset
# with all Filters that produce stats.
dj-analyze --auto --dataset_path xx.jsonl [--auto_num 1000]
Note: Analyzer only computes stats for Filters that produce stats or other OPs that produce tags/categories in meta. So other OPs will be ignored in the analysis process. We use the following registries to decorate OPs:
NON_STATS_FILTERS: decorate Filters that DO NOT produce any stats.TAGGING_OPS: decorate OPs that DO produce tags/categories in meta field.
Sometimes, “Glyph missing” warning occurs and invalid characters show in the analyzed results figures. Users can specify appropriate font using the environment variable
ANALYZER_FONT. For example:
export ANALYZER_FONT="Heiti TC" # Use Heiti for Chinese characters. And it's the default font for analyzer.
python tools/analyze_data.py --config configs/demo/analyzer.yaml
Data Visualization¶
Run
app.pytool to visualize your dataset in your browser.Note: only available for installation from source.
streamlit run app.py
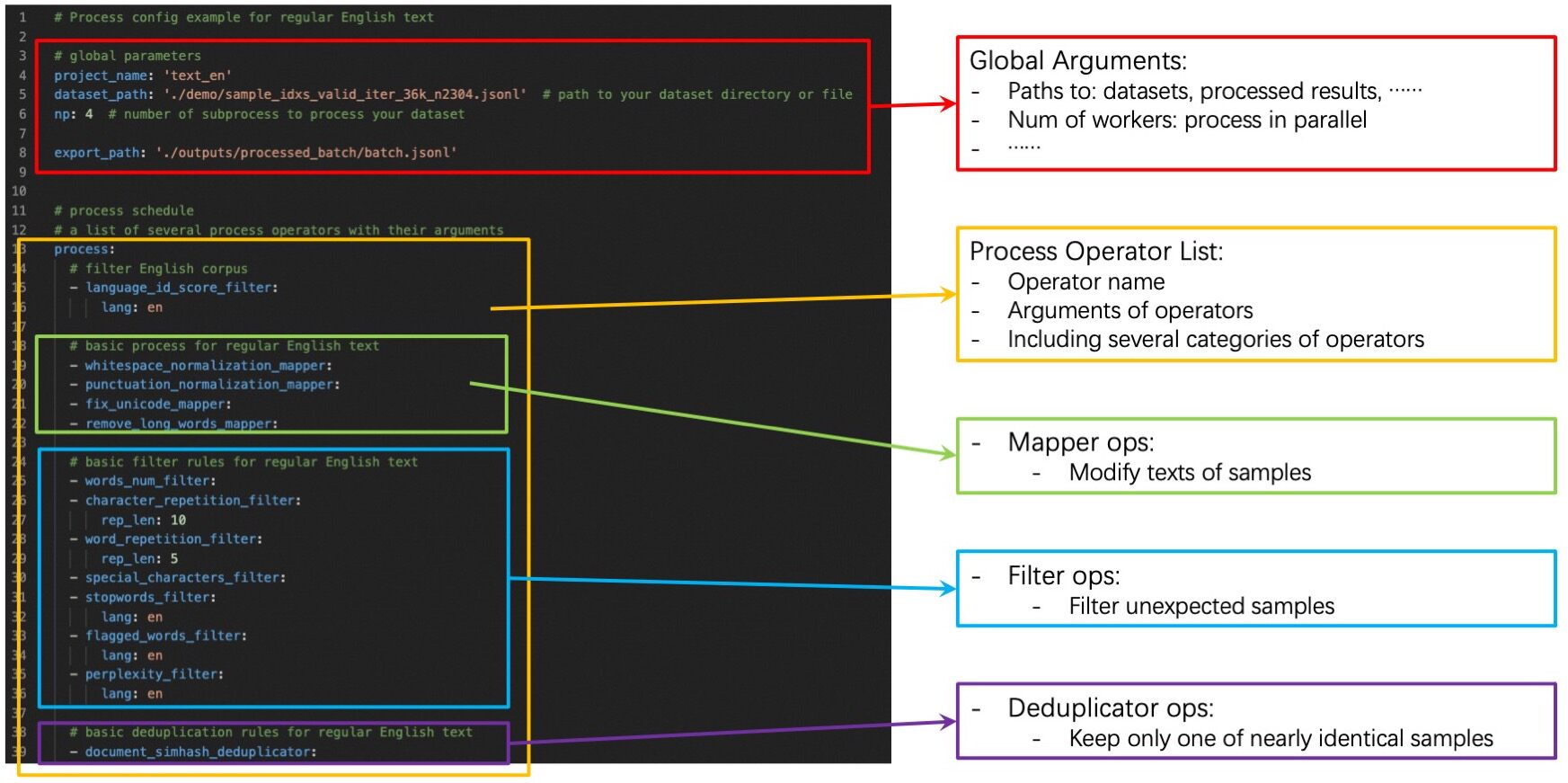
Build Up Config Files¶
Config files specify some global arguments, and an operator list for the data process. You need to set:
Global arguments: input/output dataset path, number of workers, etc.
Operator list: list operators with their arguments used to process the dataset.
You can build up your own config files by:
➖:Modify from our example config file
config_all.yamlwhich includes all ops and default arguments. You just need to remove ops that you won’t use and refine some arguments of ops.➕:Build up your own config files from scratch. You can refer our example config file
config_all.yaml, op documents, and advanced Build-Up Guide for developers.Besides the yaml files, you also have the flexibility to specify just one (of several) parameters on the command line, which will override the values in yaml files.
python xxx.py --config configs/demo/process.yaml --language_id_score_filter.lang=en
The basic config format and definition is shown below.
Sandbox¶
The data sandbox laboratory (DJ-Sandbox) provides users with the best practices for continuously producing data recipes. It features low overhead, portability, and guidance.
In the sandbox, users can quickly experiment, iterate, and refine data recipes based on small-scale datasets and models, before scaling up to produce high-quality data to serve large-scale models.
In addition to the basic data optimization and recipe refinement features offered by Data-Juicer, users can seamlessly use configurable components such as data probe and analysis, model training and evaluation, and data and model feedback-based recipe refinement to form a complete one-stop data-model research and development pipeline.
The sandbox is run using the following commands by default, and for more information and details, please refer to the sandbox documentation.
python tools/sandbox_starter.py --config configs/demo/sandbox/sandbox.yaml
Preprocess Raw Data (Optional)¶
Our Formatters support some common input dataset formats for now:
Multi-sample in one file: jsonl/json, parquet, csv/tsv, etc.
Single-sample in one file: txt, code, docx, pdf, etc.
However, data from different sources are complicated and diverse. Such as:
Raw arXiv data downloaded from S3 include thousands of tar files and even more gzip files in them, and expected tex files are embedded in the gzip files so they are hard to obtain directly.
Some crawled data include different kinds of files (pdf, html, docx, etc.). And extra information like tables, charts, and so on is hard to extract.
It’s impossible to handle all kinds of data in Data-Juicer, issues/PRs are welcome to contribute to processing new data types!
Thus, we provide some common preprocessing tools in
tools/preprocessfor you to preprocess these data.You are welcome to make your contributions to new preprocessing tools for the community.
We highly recommend that complicated data can be preprocessed to jsonl or parquet files.
For Docker Users¶
If you build or pull the docker image of
data-juicer, you can run the commands or tools mentioned above using this docker image.Run directly:
# run the data processing directly
docker run --rm \ # remove container after the processing
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--name dj \ # name of the container
-v <host_data_path>:<image_data_path> \ # mount data or config directory into the container
-v ~/.cache/:/root/.cache/ \ # mount the cache directory into the container to reuse caches and models (recommended)
datajuicer/data-juicer:<version_tag> \ # image to run
dj-process --config /path/to/config.yaml # similar data processing commands
Or enter into the running container and run commands in editable mode:
# start the container
docker run -dit \ # run the container in the background
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--rm \
--name dj \
-v <host_data_path>:<image_data_path> \
-v ~/.cache/:/root/.cache/ \
datajuicer/data-juicer:latest /bin/bash
# enter into this container and then you can use data-juicer in editable mode
docker exec -it <container_id> bash