数据菜谱的自动化超参优化¶
基于3-Sigma原则进行Auto-HPO¶
一种简单的数据菜谱自动调参方法是假设outlier数据对训练有害,那么我们可以引入3-sigma原则来自动确定超参,过滤数据。具体来说,假设原始数据的某个分析维度服从正态分布且存在随机误差,我们可以基于Analyzer产出的stats,在该维度上 把算子过滤的上下界设为三倍标准差。
$$P(|x-\mu| > 3\sigma) \leq 0.003$$
为了自动化该过程,我们提供了相应工具:
# cd tools/hpo
# usage 1: do not save the refined recipe
python execute_hpo_3sigma.py --config <data-process-cfg-file-path>
# usage 2: save the refined recipe at the given path
python execute_hpo_3sigma.py --config <data-process-cfg-file-path> --path_3sigma_recipe <data-process-cfg-file-after-refined-path>
# e.g., usage 1
python execute_hpo_3sigma.py --config configs/process.yaml
# e.g., usage 2
python execute_hpo_3sigma.py --config configs/process.yaml --path_3sigma_recipe configs/process_3sigma.yaml
基于WandB进行Auto-HPO¶
我们将自动化 HPO (hyper-parameters optimization) 工具 WandB Sweep 结合到 Data-Juicer 中,以简化改良数据处理超参数的过程。 使用此工具,用户可以研究探索 数据配方的特定超参数 和 指定目标度量(如数据质量分、模型loss等) 之间的 相关性和重要性得分。
注意:这是一个实验性功能。 用于数据配方的 Auto-HPO 仍然有 一个极大的探索空间,暂无标准做法。 欢迎大家提出更多的建议、讨论、 并通过新的 PR 做出贡献!
前置条件¶
您需要先安装 data-juicer。
此外,该工具利用了 WandB,通过pip install wandb安装它。
在使用此工具之前,您需要运行wandb login并输入您的 WandB
API 密钥。
如果您有自己的 WandB 实例(例如 本地托管模式 ),请运行以下脚本:
wandb login --host <URL of your wandb instance>
# enter your api key
使用和定制化¶
给定一个数据配方,以指定的配置文件所定义<data-process-cfg-file-path>,您可以使用 execute_hpo_wandb.py 来搜索
由<hpo-cfg-file-path>定义的超参数空间。
# cd tools/hpo
python execute_hpo_wandb.py --config <data-process-cfg-file-path> --hpo_config <hpo-cfg-file-path>
# e.g.,
python execute_hpo_wandb.py --config configs/process.yaml --hpo_config configs/quality_score_hpo.yaml
对于数据菜谱的配置,即<data-process-cfg-file-path>,
请参阅我们的 指南
获取更多详细信息。
对于HPO的配置,即<hpo-cfg-file-path>,请参阅Sweep提供的 指南 。
我们在hpo/objects.py中提供了一个示意性的搜索目标 quality_score,
它使用质量评分器来度量处理后的数据,并将平均质量分数链接到数据配方的超参数。
运行后,你会得到类似如下的结果: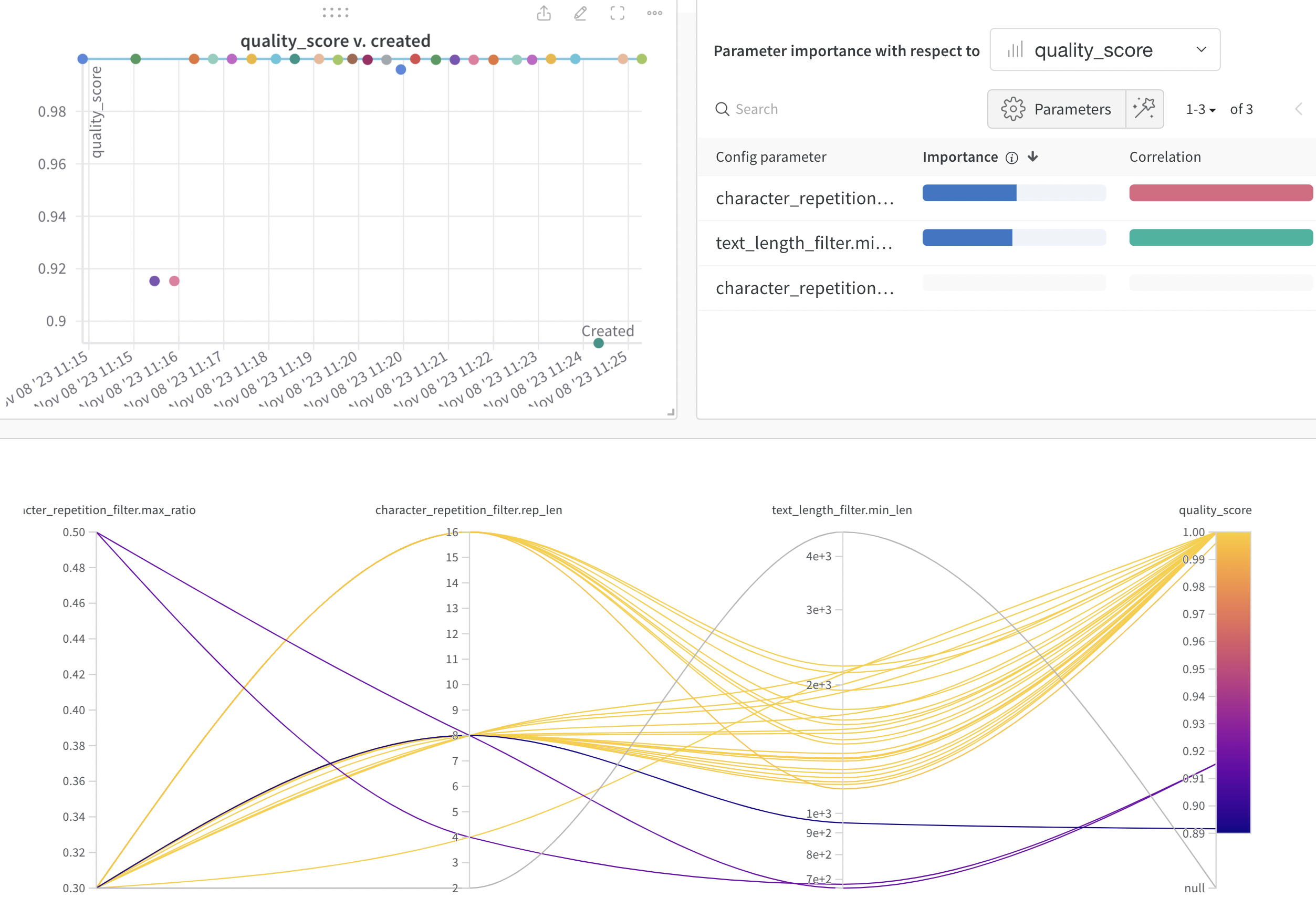
您可以在 get_hpo_objective 函数中实现您自己的 HPO 目标,例如,将数据配方链接到
model_loss(通过用训练程序 替换质量评分器),
下游任务(通过用训练和评测程序 替换质量评分器),或
一些您感兴趣的指标的综合考量,以便可以探索不同角度的权衡(如size-quality-diversity)。