快速上手¶
数据集配置¶
DJ 支持多种数据集输入类型,包括本地文件、远程数据集(如 huggingface);还支持数据验证和数据混合。
配置输入文件的两种方法
简单场景,本地/HF 文件的单一路径
dataset_path: '/path/to/your/dataset' # 数据集目录或文件的路径
高级方法,支持子配置项和更多功能
dataset:
configs:
- type: 'local'
path: 'path/to/your/dataset' # 数据集目录或文件的路径
更多详细信息,请参阅 数据集配置指南。
数据处理¶
以配置文件路径作为参数来运行
process_data.py或者dj-process命令行工具来处理数据集。
# 适用于从源码安装
python tools/process_data.py --config configs/demo/process.yaml
# 使用命令行工具
dj-process --config configs/demo/process.yaml
注意:使用未保存在本地的第三方模型或资源的算子第一次运行可能会很慢,因为这些算子需要将相应的资源下载到缓存目录中。默认的下载缓存目录为
~/.cache/data_juicer。您可通过设置 shell 环境变量DATA_JUICER_CACHE_HOME更改缓存目录位置,您也可以通过同样的方式更改DATA_JUICER_MODELS_CACHE或DATA_JUICER_ASSETS_CACHE来分别修改模型缓存或资源缓存目录:注意:对于使用了第三方模型的算子,在填写config文件时需要去声明其对应的
mem_required(可以参考config_all.yaml文件中的设置)。Data-Juicer在运行过程中会根据内存情况和算子模型所需的memory大小来控制对应的进程数,以达成更好的数据处理的性能效率。而在使用CUDA环境运行时,如果不正确的声明算子的mem_required情况,则有可能导致CUDA Out of Memory。
# 缓存主目录
export DATA_JUICER_CACHE_HOME="/path/to/another/directory"
# 模型缓存目录
export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
# 资源缓存目录
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
灵活的编程接口: 我们提供了各种层次的简单编程接口,以供用户选择:
# ... init op & dataset ...
# 链式调用风格,支持单算子或算子列表
dataset = dataset.process(op)
dataset = dataset.process([op1, op2])
# 函数式编程风格,方便快速集成或脚本原型迭代
dataset = op(dataset)
dataset = op.run(dataset)
分布式数据处理¶
Data-Juicer 现在基于RAY实现了多机分布式数据处理。 对应Demo可以通过如下命令运行:
# 运行文字数据处理
python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
# 运行视频数据处理
python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
如果需要在多机上使用RAY执行数据处理,需要确保所有节点都可以访问对应的数据路径,即将对应的数据路径挂载在共享文件系统(如NAS)中。
RAY 模式下的去重算子与单机版本不同,所有 RAY 模式下的去重算子名称都以
ray作为前缀,例如ray_video_deduplicator和ray_document_deduplicator。更多细节请参考分布式处理文档。
用户也可以不使用 RAY,拆分数据集后使用 Slurm 在集群上运行,此时使用不包含 RAY 的原版 Data-Juicer 即可。 阿里云 PAI-DLC 支持 RAY 框架、Slurm 框架等,用户可以直接在DLC集群上创建 RAY 作业 和 Slurm 作业。
数据分析¶
以配置文件路径为参数运行
analyze_data.py或者dj-analyze命令行工具来分析数据集。
# 适用于从源码安装
python tools/analyze_data.py --config configs/demo/analyzer.yaml
# 使用命令行工具
dj-analyze --config configs/demo/analyzer.yaml
# 你也可以使用"自动"模式来避免写一个新的数据菜谱。它会使用全部可产出统计信息的 Filter 来分析
# 你的数据集的一小部分(如1000条样本,可通过 `auto_num` 参数指定)
dj-analyze --auto --dataset_path xx.jsonl [--auto_num 1000]
注意:Analyzer 只用于能在 stats 字段里产出统计信息的 Filter 算子和能在 meta 字段里产出 tags 或类别标签的其他算子。除此之外的其他的算子会在分析过程中被忽略。我们使用以下两种注册器来装饰相关的算子:
NON_STATS_FILTERS:装饰那些不能产出任何统计信息的 Filter 算子。TAGGING_OPS:装饰那些能在 meta 字段中产出 tags 或类别标签的算子。
数据可视化¶
运行
app.py来在浏览器中可视化您的数据集。注意:只可用于从源码安装的方法。
streamlit run app.py
构建配置文件¶
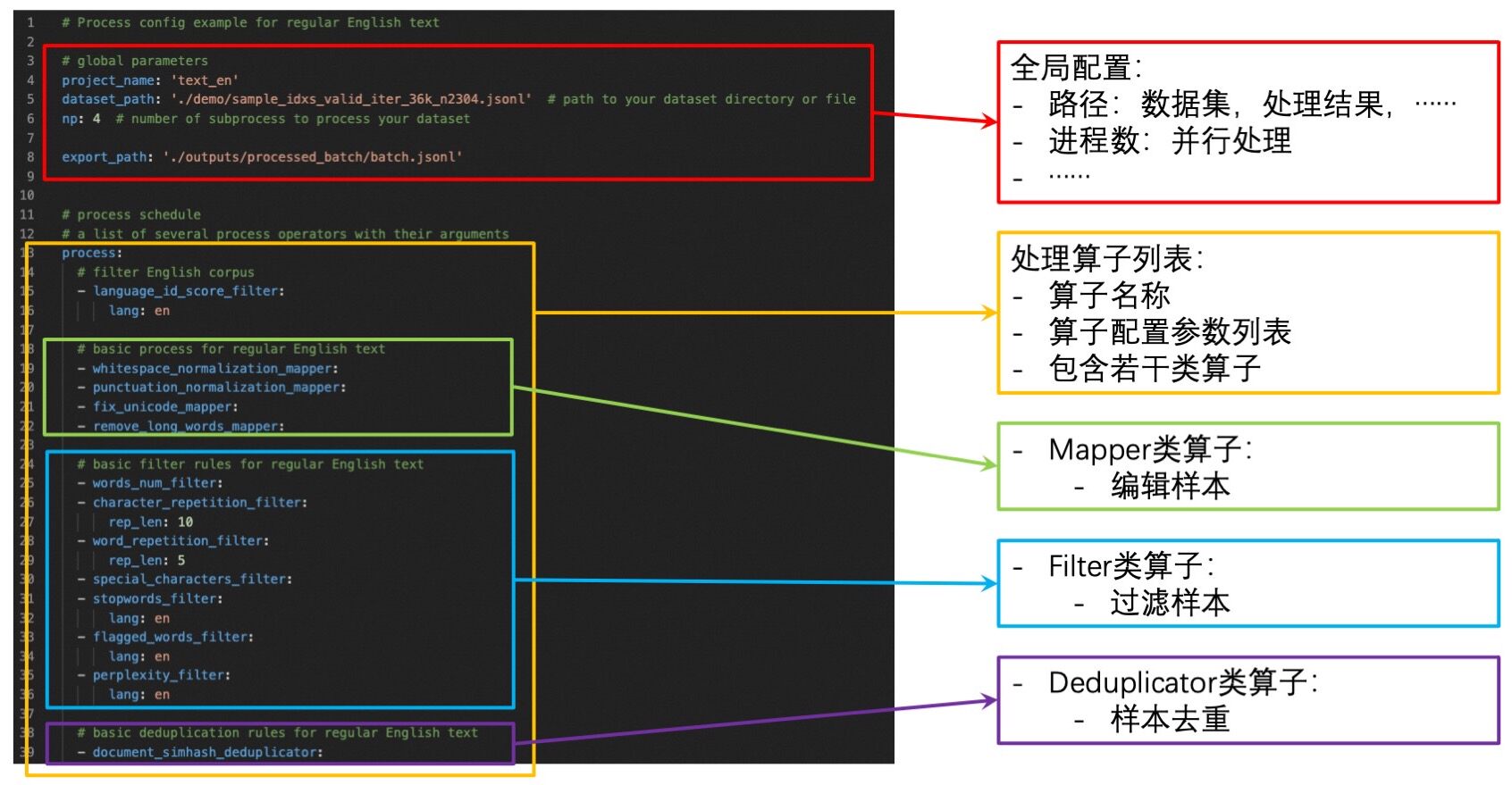
配置文件包含一系列全局参数和用于数据处理的算子列表。您需要设置:
全局参数:输入/输出 数据集路径,worker 进程数量等。
算子列表:列出用于处理数据集的算子及其参数。
您可以通过如下方式构建自己的配置文件:
➖:修改我们的样例配置文件
config_all.yaml。该文件包含了所有算子以及算子对应的默认参数。您只需要移除不需要的算子并重新设置部分算子的参数即可。➕:从头开始构建自己的配置文件。您可以参考我们提供的样例配置文件
config_all.yaml,算子文档,以及 开发者指南.除了使用 yaml 文件外,您还可以在命令行上指定一个或多个参数,这些参数将覆盖 yaml 文件中的值。
python xxx.py --config configs/demo/process.yaml --language_id_score_filter.lang=en
基础的配置项格式及定义如下图所示
沙盒实验室¶
数据沙盒实验室 (DJ-Sandbox) 为用户提供了持续生产数据菜谱的最佳实践,其具有低开销、可迁移、有指导性等特点。
用户在沙盒中可以基于一些小规模数据集、模型对数据菜谱进行快速实验、迭代、优化,再迁移到更大尺度上,大规模生产高质量数据以服务大模型。
用户在沙盒中,除了Data-Juicer基础的数据优化与数据菜谱微调功能外,还可以便捷地使用数据洞察与分析、沙盒模型训练与评测、基于数据和模型反馈优化数据菜谱等可配置组件,共同组成完整的一站式数据-模型研发流水线。
沙盒默认通过如下命令运行,更多介绍和细节请参阅沙盒文档.
python tools/sandbox_starter.py --config configs/demo/sandbox/sandbox.yaml
预处理原始数据(可选)¶
我们的 Formatter 目前支持一些常见的输入数据集格式:
单个文件中包含多个样本:jsonl/json、parquet、csv/tsv 等。
单个文件中包含单个样本:txt、code、docx、pdf 等。
但来自不同源的数据是复杂和多样化的,例如:
从 S3 下载的 arXiv 原始数据 包括数千个 tar 文件以及更多的 gzip 文件,并且所需的 tex 文件在 gzip 文件中,很难直接获取。
一些爬取的数据包含不同类型的文件(pdf、html、docx 等),并且很难提取额外的信息,例如表格、图表等。
Data-Juicer 不可能处理所有类型的数据,欢迎提 Issues/PRs,贡献对新数据类型的处理能力!
因此我们在
tools/preprocess中提供了一些常见的预处理工具,用于预处理这些类型各异的数据。欢迎您为社区贡献新的预处理工具。
我们强烈建议将复杂的数据预处理为 jsonl 或 parquet 文件。
对于 Docker 用户¶
如果您构建或者拉取了
data-juicer的 docker 镜像,您可以使用这个 docker 镜像来运行上面提到的这些命令或者工具。直接运行:
# 直接运行数据处理
docker run --rm \ # 在处理结束后将容器移除
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--name dj \ # 容器名称
-v <host_data_path>:<image_data_path> \ # 将本地的数据或者配置目录挂载到容器中
-v ~/.cache/:/root/.cache/ \ # 将 cache 目录挂载到容器以复用 cache 和模型资源(推荐)
datajuicer/data-juicer:<version_tag> \ # 运行的镜像
dj-process --config /path/to/config.yaml # 类似的数据处理命令
或者您可以进入正在运行的容器,然后在可编辑模式下运行命令:
# 启动容器
docker run -dit \ # 在后台启动容器
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--rm \
--name dj \
-v <host_data_path>:<image_data_path> \
-v ~/.cache/:/root/.cache/ \
datajuicer/data-juicer:latest /bin/bash
# 进入这个容器,然后您可以在编辑模式下使用 data-juicer
docker exec -it <container_id> bash