Sirchmunk: A Technical Deep Dive
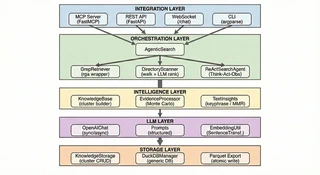 Sirchmunk Architecture
Sirchmunk ArchitectureSirchmunk is an open-source, embedding-free, agentic search engine that transforms raw data into self-evolving intelligence in real time. Unlike traditional RAG (Retrieval-Augmented Generation) systems that depend on static vector embeddings, pre-computed indexes, and complex ETL pipelines, Sirchmunk operates directly on raw files — delivering instant, full-fidelity retrieval without any pre-processing.
This report provides a comprehensive technical analysis of Sirchmunk’s design philosophy and architectural principles, covering its multi-phase search pipeline, Monte Carlo evidence sampling, ReAct-based agentic refinement, self-evolving knowledge clustering, and its integration surfaces across MCP, OpenClaw, REST, WebSocket, CLI, and Web UI.
1. Abstract
Sirchmunk is an open-source, embedding-free, agentic search engine that transforms raw data into self-evolving intelligence in real time. Unlike traditional RAG (Retrieval-Augmented Generation) systems that depend on static vector embeddings, pre-computed indexes, and complex ETL pipelines, Sirchmunk operates directly on raw files — delivering instant, full-fidelity retrieval without any pre-processing.
This report provides a comprehensive technical analysis of Sirchmunk’s design philosophy and architectural principles, covering its multi-phase search pipeline, Monte Carlo evidence sampling, ReAct-based agentic refinement, self-evolving knowledge clustering, and its integration surfaces across MCP, OpenClaw, REST, WebSocket, CLI, and Web UI.
2. Motivation & Design Philosophy
Intelligence pipelines built upon vector-based retrieval are often rigid and brittle. They suffer from three fundamental problems:
- Expensive to compute — Building and maintaining vector indexes requires significant compute and time.
- Blind to real-time changes — Embeddings become stale the moment the underlying data changes.
- Detached from raw context — Vector approximations lose information; the retrieval is inherently lossy.
Sirchmunk’s design philosophy rests on three pillars:
| Pillar | Principle | How Sirchmunk Implements It |
|---|---|---|
| Embedding-Free | Work with data in its purest form | Indexless retrieval with zero information loss. On top of path meta-information and probe sampling, intelligent inference locates the most likely target files — without ever building a vector index. |
| Self-Evolving | Data is a stream, not a snapshot | Knowledge clusters evolve with every search; LLM-powered autonomy ensures that the system’s understanding deepens over time. |
| Token-Efficient | Maximize intelligence, minimize cost | LLM inference is triggered only when necessary; Monte Carlo sampling extracts precise evidence from documents without reading them in full. |
Comparison with Traditional RAG
| Dimension | Traditional RAG | Sirchmunk |
|---|---|---|
| Setup Cost | High — VectorDB, GraphDB, document parsers, ETL pipelines | Zero — Drop files and search immediately |
| Data Freshness | Stale — Requires batch re-indexing | Instant — Searches live files directly |
| Information Fidelity | Lossy — Vector approximation discards nuance | Full — Raw content, zero loss |
| Scalability | Linear cost growth with data size | Low resource consumption — streaming search, in-memory analytics |
| Accuracy | Approximate matches — may miss or hallucinate | Deterministic — Evidence-backed with confidence scores |
| Knowledge Evolution | Static — Index is a snapshot in time | Self-evolving — Clusters grow with every search |
| Token Efficiency | Sends full chunks to LLM | Monte Carlo sampling selects only the most relevant regions |
| Failure Mode | Returns whatever the vector index matches — no recourse | Falls back to ReAct agent for iterative deep exploration |
3. System Architecture
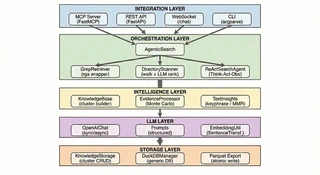
4. Core Search Pipeline
At the heart of Sirchmunk is a multi-phase search pipeline. The core design principle is maximum parallelism within each phase combined with strict phase dependencies between them. This achieves both speed and correctness: independent tasks race concurrently, while each phase builds on the converged output of the previous one.
Sirchmunk supports two search modes: FAST mode (default) uses a greedy strategy with 2-level keyword cascade, context-window sampling, and early stopping — completing retrieval in 2–5 seconds with only 2 LLM calls (~10x faster than DEEP mode). DEEP mode activates the full pipeline described below, including Monte Carlo evidence sampling and multi-round ReAct refinement, for maximum recall on complex queries (10–30 seconds).
Query
|
v
+----------------------------------------------+
| Phase 0: Knowledge Reuse |
| "Have we seen a similar question before?" |
| YES -> return immediately | NO -> continue |
+-------------------+--------------------------+
v
+----------------------------------------------+
| Phase 1: Parallel Probing |
| Four independent probes run concurrently: |
| - LLM keyword extraction (multi-granularity)|
| - Directory structure scan (metadata) |
| - Knowledge cache lookup (partial reuse) |
| - Spec-path context cache load |
+-------------------+--------------------------+
v
+----------------------------------------------+
| Phase 2: Retrieval & Ranking |
| Two strategies run in parallel: |
| - Keyword-based content retrieval (IDF) |
| - LLM-guided file candidate ranking |
+-------------------+--------------------------+
v
+----------------------------------------------+
| Phase 3: Knowledge Cluster Construction |
| Merge & deduplicate -> Monte Carlo evidence |
| extraction -> LLM synthesis -> cluster |
+-------------------+--------------------------+
v
+----------------------------------------------+
| Phase 4: Output |
| Evidence found? -> LLM summarization |
| No evidence? -> ReAct agent refinement |
+-------------------+--------------------------+
v
+----------------------------------------------+
| Phase 5: Persist |
| Save cluster + embedding for future reuse |
+----------------------------------------------+
4.1 Phase 0 — Knowledge Cluster Reuse
Before any heavy computation begins, Sirchmunk asks a simple question: “Have we answered something semantically similar before?” It computes a lightweight embedding of the incoming query and measures cosine similarity against all stored knowledge clusters. If a close match is found (above a configurable threshold), the cached cluster is returned immediately — providing sub-second response times for repeated or paraphrased queries.
This is not merely a cache — it is the beginning of knowledge compounding. Each reuse appends the new query to the cluster’s history, so the system remembers which questions led to which insights.
4.2 Phase 1 — Parallel Probing
Four independent probes launch concurrently. The design intent is to gather diverse signals about where the answer might live, rather than betting on a single retrieval strategy:
- LLM Keyword Extraction — The LLM decomposes the query into multi-level keywords, from coarse (high recall) to fine (high precision), each annotated with an estimated rarity score. This multi-granularity approach ensures that both broad topics and specific terms are captured.
- Directory Structure Scan — The file system is traversed to collect path metadata: file names, sizes, modification times, and content previews. This is the foundation for intelligent inference — using structural cues (naming conventions, directory hierarchy, file types) to narrow down the most promising candidates before ever reading their content.
- Knowledge Cache Lookup — Existing knowledge clusters are searched for partial matches, enabling the system to build upon what it already knows.
- Spec-Path Context Load — Previously computed context for the same search paths is loaded from a local cache, avoiding redundant work for frequently searched directories.
4.3 Phase 2 — Retrieval & Ranking
Two complementary retrieval strategies run in parallel, embodying a dual-signal philosophy:
- Content-based retrieval — Multi-level keywords from Phase 1 are used to search file contents directly. Results are scored with an IDF-weighted formula that rewards rare, discriminative terms and penalizes overly long or trivially short snippets. This is a bottom-up signal: “what does the text actually say?”
- Structure-based ranking — The LLM receives candidate file summaries from the directory scan and ranks them by relevance with reasoning. This is a top-down signal: “given the file’s name, path, and preview, how likely is it to contain the answer?”
By combining bottom-up content matching with top-down structural reasoning, Sirchmunk achieves higher recall than either strategy alone — a principle we call intelligent inference based on path meta-information and probe sampling.
4.4 Phase 3 — Knowledge Cluster Construction
File paths from both retrieval strategies are merged and deduplicated. For each candidate file, the Monte Carlo Evidence Sampling algorithm (detailed in Section 6) extracts the most relevant regions without reading the entire document. The LLM then synthesizes these evidence fragments into a structured Knowledge Cluster — a self-contained unit of insight with a deterministic identity, confidence score, and lifecycle state.
4.5 Phase 4 — Summarization & ReAct Refinement
The pipeline now branches based on the richness of the gathered evidence:
- Evidence found: The LLM generates a structured markdown briefing from the cluster. It also evaluates whether the cluster is valuable enough to persist for future reuse — a form of self-curation.
- No evidence: The system does not give up. Instead, a ReAct Search Agent (detailed in Section 7) takes over, performing iterative reasoning-and-action cycles to explore alternative search strategies until an answer is found or the budget is exhausted.
This fallback-to-agent design embodies a key principle: the system should always try harder before admitting ignorance.
5. Indexless Retrieval Engine
The retrieval engine is the foundation of Sirchmunk’s “drop-and-search” philosophy. There is no indexing step, no embedding generation, no database to set up. Users simply point the system at a directory, and it searches immediately.
The Rationale for Going Indexless
Traditional retrieval systems require an up-front investment: parse every document, split it into chunks, compute embeddings, and store them in a vector database. This pipeline is expensive, fragile, and instantly stale when data changes. Sirchmunk rejects this paradigm entirely.
Instead, it leverages a high-performance, Rust-based full-text search engine (ripgrep-all) that can search across 100+ file formats — PDFs, Office documents, archives, source code, and plain text — in a streaming fashion. The key insight is that raw text search combined with intelligent scoring is sufficient when augmented with LLM-guided probe sampling.
Intelligent File Discovery
The system doesn’t blindly grep through every file. On top of path meta-information and probe sampling, it makes intelligent inferences to locate the most likely target files:
- Structural cues: File names, directory hierarchies, and extensions carry strong prior signals about content. A file named
authentication.pyin asecurity/directory is far more likely to answer a question about auth than a randomutils.py. - Multi-level keyword probing: Rather than searching with a single query string, the system decomposes the question into keywords at multiple granularity levels. Coarse keywords cast a wide net; fine-grained keywords narrow the focus. Each level’s results are scored with IDF-weighted relevance.
- LLM-guided structural ranking: The LLM evaluates candidate files based on their metadata — name, path, size, and content preview — to determine which ones are most worth reading in depth.
This combination of bottom-up content search and top-down structural reasoning means Sirchmunk can find relevant files in massive repositories with the same accuracy as indexed systems — but without any of the setup cost.
Scoring Philosophy
Not all matches are created equal. The scoring system is designed around several principles:
- Rarity matters: Rare terms (high IDF) are weighted more heavily than common ones, because a match on a distinctive keyword is a stronger signal than a match on a stop word.
- Diminishing returns: Term frequency is subject to logarithmic saturation — seeing a keyword 100 times is not 100x more valuable than seeing it once.
- Context quality: Snippets that are too short (fragments) or too long (noise-diluted) are penalized. The ideal match is a concise, information-dense passage.
- Precision bonus: Exact, whitespace-bounded matches receive a bonus over partial matches, rewarding precision without sacrificing recall.
6. Monte Carlo Evidence Sampling
Perhaps the most novel contribution of Sirchmunk is its evidence extraction strategy. The fundamental challenge is this: a candidate file may be hundreds of pages long, but only a few paragraphs are relevant. Reading the entire document is prohibitively expensive in LLM tokens. Fixed chunking strategies risk either missing the relevant section or drowning it in noise.
Sirchmunk solves this with an exploration–exploitation approach inspired by Monte Carlo methods in statistical inference. The idea is simple yet powerful: sample strategically, score cheaply, then zoom in on the best regions.
The Algorithm in Three Acts
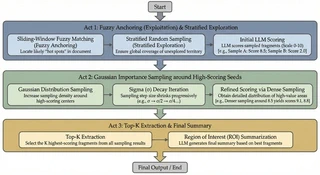
Act 1: Casting the Net
The first round combines two complementary strategies. Fuzzy anchoring (exploitation) uses rapid, token-level fuzzy matching to identify regions of the document that lexically resemble the query and keywords. These are cheap to compute and provide good initial “hot spots.” Stratified random sampling (exploration) supplements the anchors with samples drawn from evenly spaced strata across the document, ensuring that no region is left entirely unexplored — because sometimes the most relevant passage uses different terminology than the query.
Every sample is then scored by the LLM on a 0–10 relevance scale, with structured reasoning. This is the only LLM call in the loop, and it operates on small windows rather than entire documents — keeping token costs low.
Act 2: Zooming In
High-scoring samples become “seeds” for the next round. New samples are drawn from Gaussian distributions centered on each seed, with a sigma that decays with each successive round. This progressive narrowing is analogous to simulated annealing: early rounds explore broadly, later rounds converge on the highest-value regions with increasing precision.
The process includes early stopping: if a sample exceeds a high confidence threshold, the algorithm terminates immediately, saving unnecessary rounds.
Act 3: Synthesis
The top-K scored snippets are passed to the LLM for synthesis into a coherent Region of Interest (ROI) summary. The output includes a confidence flag indicating whether strong evidence was found, enabling the pipeline to make informed decisions about whether to proceed with summarization or fall back to the ReAct agent.
Design insight: By treating evidence extraction as a sampling problem rather than a parsing problem, Sirchmunk avoids the need for document-specific chunking heuristics. The same algorithm works equally well on a 2-page memo and a 500-page technical manual.
7. ReAct Search Agent
When the standard pipeline fails to find sufficient evidence, Sirchmunk does not simply return “no results found.” Instead, it activates a ReAct (Reasoning + Acting) agent — an autonomous reasoning loop that iteratively explores the data through tool use until it finds the answer or exhausts its budget.
The Think → Act → Observe Paradigm
The ReAct pattern, introduced in the AI research community, alternates between three cognitive steps:
- Think: The LLM reasons about what it knows so far, what’s missing, and what action would most likely fill the gap.
- Act: The LLM selects and invokes a tool — a keyword search, a file read, a knowledge query, or a directory scan.
- Observe: The tool’s result is fed back to the LLM as new context, and the cycle repeats.
This paradigm transforms the search from a single-shot retrieval into an iterative dialogue between reasoning and evidence. The LLM can adjust its strategy based on what it discovers — broadening the search if nothing is found, or diving deeper into a promising file.
Prioritized Tool Strategy
The agent follows a principled search strategy: keyword search first (cheapest, broadest coverage), then file reading (for promising candidates), then knowledge cache queries (leveraging existing insights), and finally directory scanning (when all else fails). This priority order minimizes cost while maximizing the chance of finding relevant evidence early.
Budget-Bounded Exploration
Unbounded agent loops are a well-known risk in agentic AI systems. Sirchmunk addresses this through a dual-budget mechanism:
- Token budget: A hard ceiling on total LLM tokens consumed, preventing runaway costs.
- Loop count: A maximum number of Think-Act-Observe cycles, ensuring termination.
Additionally, the agent maintains a memory of what it has already tried — files read, searches performed — to avoid wasteful repetition. This is not just efficiency; it is a form of cognitive discipline that keeps the agent focused on unexplored avenues.
8. Self-Evolving Knowledge System
Knowledge in Sirchmunk is not a static index — it is a living, evolving graph of insights that compounds with every search. This is perhaps the deepest philosophical departure from traditional RAG: the system doesn’t just retrieve; it learns.
The Knowledge Cluster
The fundamental unit of knowledge is the Knowledge Cluster — a self-contained, LLM-synthesized insight derived from raw evidence. Each cluster carries:
- A deterministic identity (content-hashed) so that identical insights always converge to the same cluster.
- Evidence units linking back to the original source files and snippets — every claim is traceable.
- A confidence score reflecting the strength and consistency of the underlying evidence.
- An abstraction level (Technique → Principle → Paradigm → Foundation → Philosophy) — categorizing how generalizable the insight is.
- A lifecycle state (Emerging → Stable → Deprecated or Contested) — modeling the natural evolution of knowledge.
- A hotness score reflecting how frequently the cluster is accessed, so the system can prioritize commonly needed knowledge.
How Clusters Evolve
The evolution of knowledge follows a natural lifecycle:
- Creation: A new search produces evidence that doesn’t match any existing cluster. Monte Carlo sampling extracts evidence; the LLM synthesizes it into a new cluster.
- Reuse: A similar query arrives. Cosine similarity on lightweight embeddings identifies the matching cluster, which is returned immediately. The new query is appended to the cluster’s history.
- Maturation: As a cluster is reused and validated across multiple queries, its confidence grows and its lifecycle transitions from Emerging to Stable.
- Deprecation: When the underlying data changes and evidence no longer supports the cluster, it may transition to Contested or Deprecated.
The Knowledge Graph
Clusters do not exist in isolation. Two types of semantic edges weave them into a graph:
- Weak semantic edges: Lightweight, weighted connections that indicate topical relatedness.
- Rich cognitive edges: Typed relationships (Pathway, Barrier, Analogy, Shortcut, Resolution) that model how insights relate to each other at a deeper level — enabling future capabilities like cognitive graph navigation and chain-of-thought retrieval.
Design insight: By modeling knowledge with lifecycle states and abstraction levels, Sirchmunk treats its knowledge base as a living organism rather than a dead archive. Knowledge can be born, grow, and eventually retire — mirroring how human expertise evolves.
9. Storage & Persistence Philosophy
Sirchmunk’s storage design follows a principle we call “fast by default, durable when it matters.” The system operates entirely in-memory during runtime for maximum speed, while a background process transparently synchronizes state to disk for durability.
In-Memory First, Disk Second
All knowledge clusters, chat history, and settings live in an in-memory analytical database (DuckDB) during execution. This provides microsecond-level read/write access. A daemon thread periodically syncs the in-memory state to disk using columnar Parquet files — chosen for their excellent compression, analytical query performance, and ecosystem compatibility.
Atomic Persistence
Writes to disk use an atomic pattern: data is first written to a temporary file, then atomically renamed to the target location. This means the on-disk state is always consistent, even if the process crashes mid-write. There is no corruption window.
Embedding-Aware Storage
Each knowledge cluster’s embedding vector (384 dimensions) is stored alongside the cluster data, enabling efficient similarity search for the Phase 0 reuse mechanism. This is a deliberate hybrid: while Sirchmunk is “embedding-free” for retrieval, it uses lightweight embeddings for knowledge management — a pragmatic choice that avoids the costs of embedding every document while still enabling semantic cluster matching.
10. Integration Layer: MCP, OpenClaw, API & Beyond
Sirchmunk is designed to be consumed, not deployed. Rather than requiring users to build applications around it, it exposes its intelligence through multiple standard interfaces — meeting users where they already work. As of v0.0.6post1, Sirchmunk is also published as an OpenClaw skill, so any OpenClaw-compatible agent can invoke its search workflow via natural language alongside MCP-native and HTTP clients.
Model Context Protocol (MCP)
The Model Context Protocol integration is perhaps the most forward-looking surface. MCP allows AI assistants like Claude Desktop and Cursor IDE to invoke Sirchmunk’s search as a native tool. The design principle is zero-friction AI-to-AI communication: an AI assistant can seamlessly ask Sirchmunk to search a user’s local files, and the result flows back as structured context.
The MCP server supports two transport modes: stdio (for local integration with desktop AI tools) and HTTP (for remote or networked scenarios). The search, directory scanning, and knowledge management capabilities are all exposed as MCP tools that any compliant client can discover and invoke.
REST API & Real-Time Chat
For programmatic access, a full REST API provides search, knowledge management, system monitoring, and settings configuration. The design follows the principle of progressive disclosure: a single search endpoint suffices for basic use, while advanced parameters allow fine-grained control over search depth, file filtering, and output format — including return_context to include extended context in responses (this supersedes the legacy return_cluster flag).
Real-time chat is powered by a WebSocket connection that supports streaming responses with inline search logs and source citations. The chat system supports multiple modes: pure LLM conversation, conversation augmented with file-based RAG, and web-augmented search — all selectable by the user at runtime.
Web UI
The web interface is built around the principle of transparent intelligence: users should not only see the answer, but understand how the system arrived at it. The UI provides streaming search logs, source citations, knowledge cluster browsing, and system monitoring dashboards — all in a single, modern interface with dark/light theme support and bilingual localization (English and Chinese).
CLI
The command-line interface serves as the primary entry point for all operations: initialization, server management, direct search, web UI serving, and MCP server startup. The design principle is one tool, all modes — a single binary covers every use case from quick local search to full production deployment.
11. Conclusion
Sirchmunk represents a paradigm shift in how we think about retrieval-augmented generation. By eliminating the embedding bottleneck and embracing an agentic, evidence-driven approach, it achieves:
- Zero infrastructure overhead — No vector database, no graph database, no ETL pipeline. Just files.
- Real-time data freshness — Always searching the live file system, never a stale index.
- Token efficiency — Monte Carlo sampling minimizes LLM costs while maximizing the relevance of extracted evidence.
- Self-improving intelligence — Knowledge clusters compound over time, making repeated queries faster and richer.
- Graceful degradation — When the standard pipeline finds nothing, the ReAct agent explores deeper rather than giving up.
- Universal integration — MCP, OpenClaw, REST, WebSocket, CLI, and Web UI meet users wherever they work.
Technology Stack
| Layer | Technology |
|---|---|
| Language | Python 3.10+ |
| Full-Text Search | ripgrep-all (Rust-based, 100+ formats) |
| Text Extraction | Kreuzberg |
| Fuzzy Matching | RapidFuzz |
| Embeddings | SentenceTransformers (via ModelScope) |
| LLM Interface | OpenAI-compatible (any provider) |
| Storage | DuckDB (in-memory) + Apache Parquet (persistence) |
| API | FastAPI + Uvicorn |
| MCP | FastMCP |
| Frontend | Next.js 14 + Tailwind CSS + React |
| License | Apache License 2.0 |
This technical report was generated by analyzing the Sirchmunk source code (v0.0.6post1). github.com/modelscope/sirchmunk · ModelScope
Sirchmunk: Raw data to self-evolving intelligence, real-time.
