The original document is Chinese Version

TLDR: Tongyi open-sources a new generation of cutting-edge and easy-to-use Agentic Reinforcement Learning framework, AgentJet (AJet). AgentJet features fully distributed Swarm Training capabilities, achieving complete decoupling of training and inference. It significantly simplifies the training process for single-agent and multi-agent LLM systems, enabling more efficient training of complex multi-agent systems.
On one hand, in AgentJet, researchers can use very simple code to connect multiple different LLM models simultaneously into a multi-agent system RL training task, achieving true non-shared parameter Multi-Agent Reinforcement Learning (MARL). On the other hand, researchers can run agents directly participating in training on any device (such as a laptop), and can dynamically add, remove, or modify agent Rollout nodes at any time. This builds a swarm training network that is unrestricted by the environment, allows for bug fixing on the fly, and can self-heal from external environment crashes. Furthermore, AgentJet is completely open-source, rich in examples, ready to use out of the box, and open for co-construction. It comes with token-level tracing debugging tools & a version-by-version training performance tracking platform. It also provides relevant skills (SKILLs) for Vibe Coding developers, allowing tools like Claude Code to assist in your agent orchestration and training debugging with one click.
The Dilemma of Centralized Agentic LLM RL Architecture
In the past year of 2025, we witnessed the rapid development of Large Language Model Agents. However, as LLM agents and their supporting tools and runtimes become increasingly complex, both agent developers and frontier LLM reinforcement learning researchers encounter various frustrating problems:
- Just as you were about to celebrate the initial success of Agent training, an external API balance was unexpectedly exhausted, causing the training to abort.
- You only simply modified the reward, but had to wait forever for the training to restart, and all progress since the last checkpoint was lost.
- A certain Agent requires docker as a runtime, but due to insufficient permissions, you cannot start other containers, so you have to spend a lot of time modifying the Agent source code to find a workaround.
- MCP tool failures (browser MCP tools blocked by IP, database MCP tools failing due to unexpected disk fullness).
- Remote connection to the server to debug the Agent is inconvenient. How great it would be if you could run the Agent on your own laptop and directly participate in (full parameter) Agent RL training.
When too much energy is wasted on the stability of the Agent runtime, it becomes increasingly difficult to make "bold" algorithmic attempts under the constraints of existing frameworks:
- Why can't we train models of different sizes simultaneously in multi-agent tasks, doing non-parameter sharing multi-agent RL training?
- If a smaller model learns multiple completely different Agent Workflows, or even tasks in completely different domains, at each Gradient Step simultaneously, is it possible to perform better?
- Why is there rarely research using complex Agents with complex Runtimes like opencode directly for training?
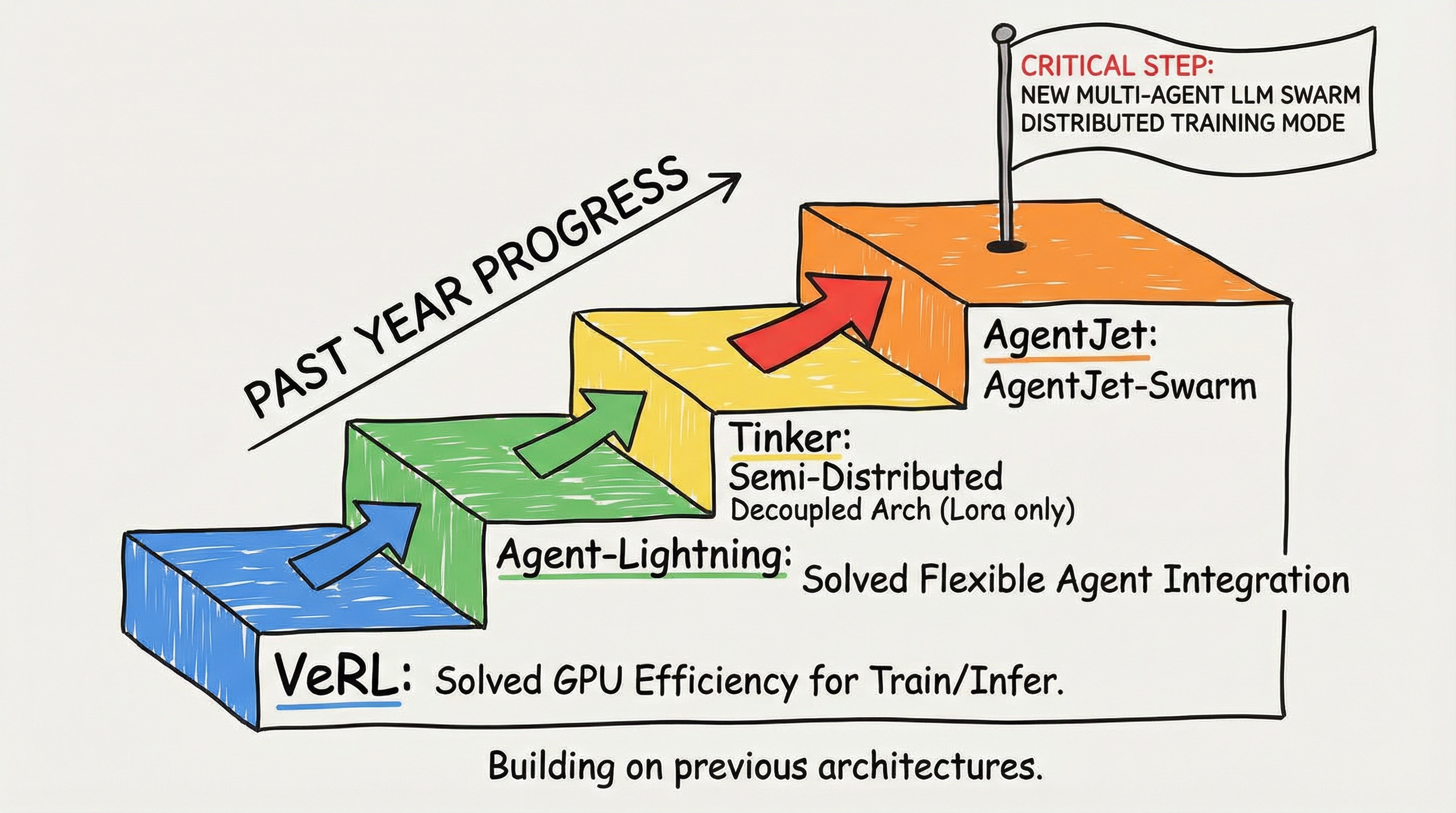
Where there are difficulties, there are solutions. In the past year, (1) VERL solved the problem of training and inference GPU efficiency, (2) Agent-Lightning solved the problem of flexible access to custom agents, (3) Tinker proposed a semi-distributed decoupled architecture (unfortunately, it can only train LoRA models). Building on the strengths of these projects, the Tongyi EconML team has taken a critical step forward with AgentJet:
We propose a brand new multi-agent LLM swarm distributed training mode, achieving complete decoupling of training and sampling, significantly simplifying the training process for single-agent and multi-agent LLM systems, enabling more efficient training of complex multi-agent systems. In this new training framework, you can easily implement training algorithms and debugging techniques that were considered very difficult in the old system with just a few simple lines of code, such as non-shared parameter multi-agent reinforcement learning, using a Macbook locally to run agents participating in full model training, multi-runtime multi-task cocktail training, hot-swap debugging, etc.
AgentJet Swarm: The First Open-Source Swarm Distributed LLM Agent Training Framework
Previous Agentic RL training modes had some implicit assumptions:
- First, no matter how many agents are in the task to be trained, these agents can only share the same fine-tunable LLM model (shared "brain"). The reason for this phenomenon is that most training backends represented by VERL and TRL typically configure only one LLM model for fine-tuning.
- Second, in the reinforcement learning sample collection stage, all current training frameworks forcibly bind the agent Rollout task process. That is, all tasks must be initiated by a single training backend, use a single model for inference, traverse tasks from the same dataset, and be constrained by the same operating system environment.
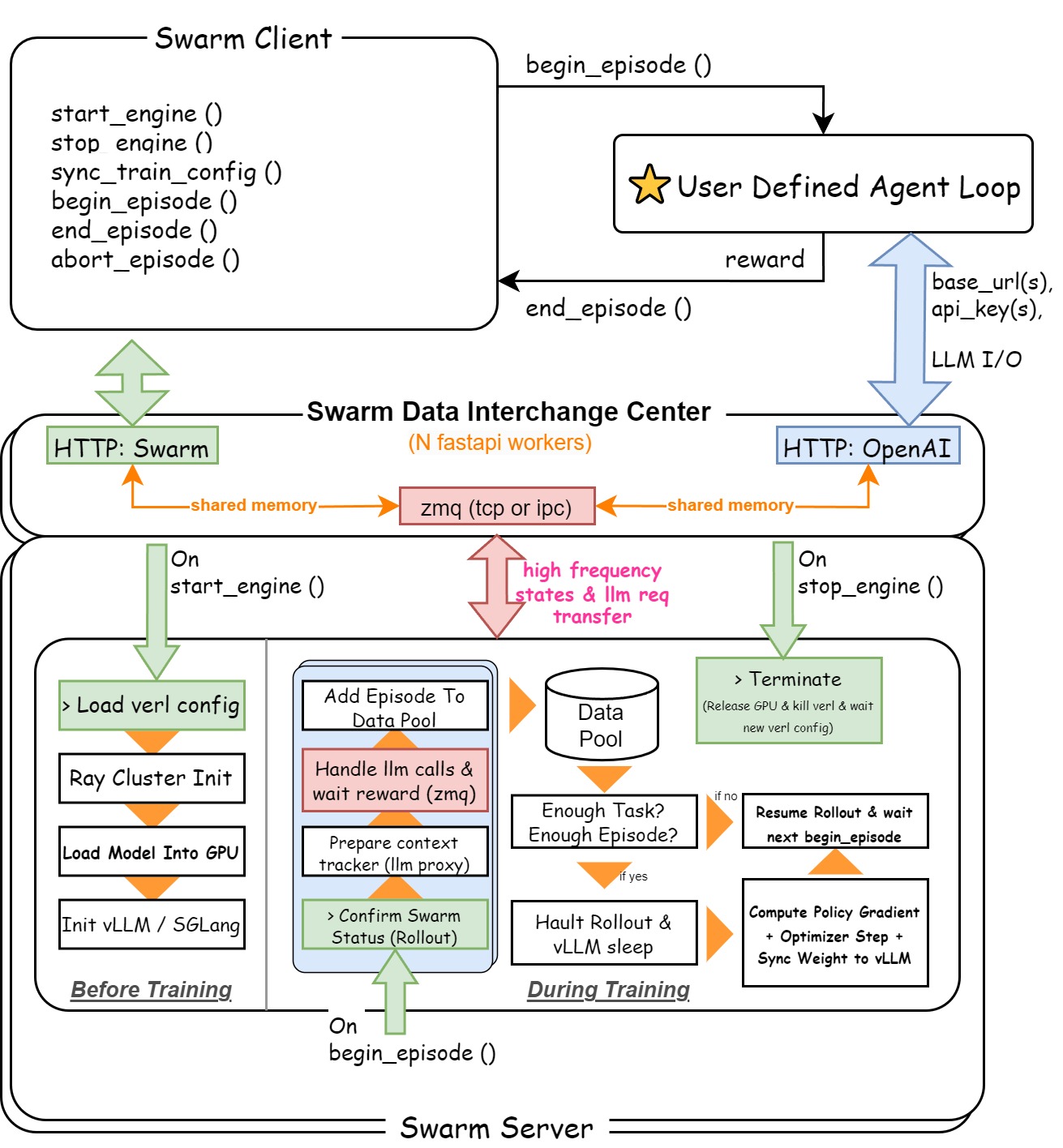
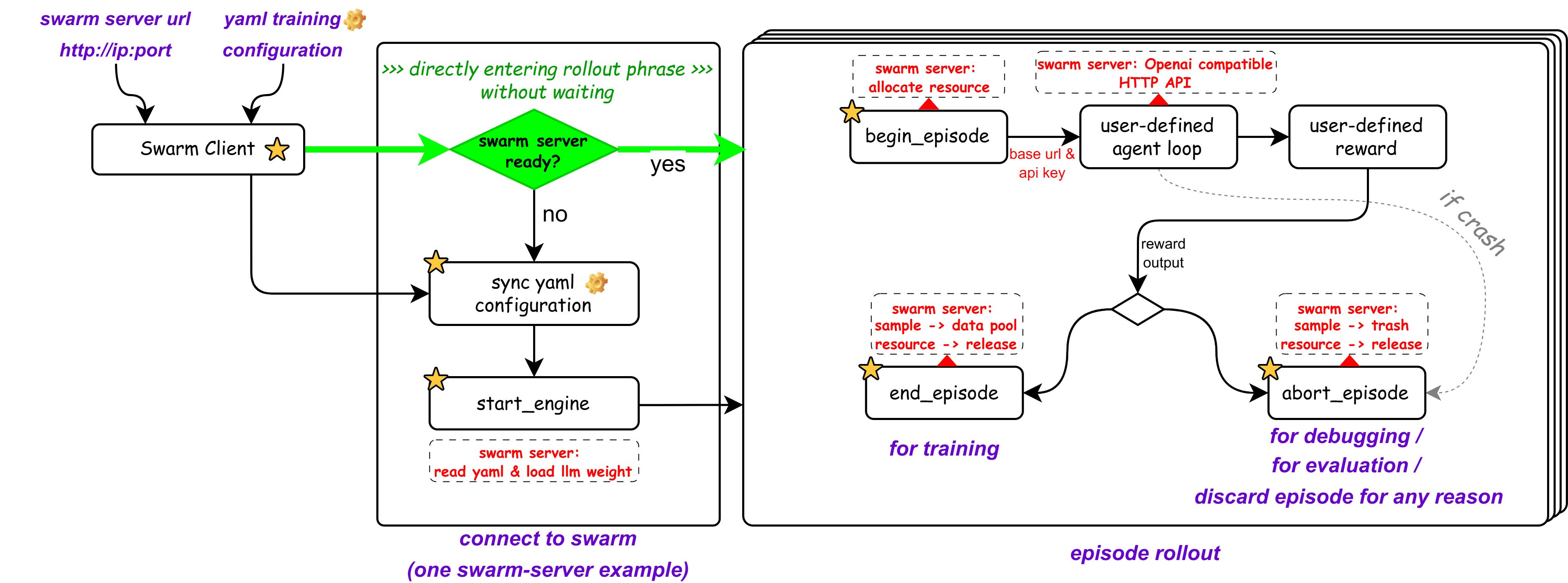
AgentJet Swarm pioneers a brand new distributed swarm training framework. In this framework, the entire training system consists of several nodes, divided into two categories: Swarm Server and Swarm Client:
- Swarm Server: Runs on a GPU server (or cluster), loads the LLM policy parameters being trained, maintains the training/inference CoLocate environment, provides vLLM/SGLang API interfaces (with automatic context tracking & timeline merging capabilities), and executes policy gradient calculations.
- Swarm Client: Runs on any device, reads datasets, runs reinforcement learning sampling tasks, and finally returns reward signals to the Swarm Server. It can also remotely control the Swarm Server at any time to update its training parameters, remotely start, stop, or restart training at will.
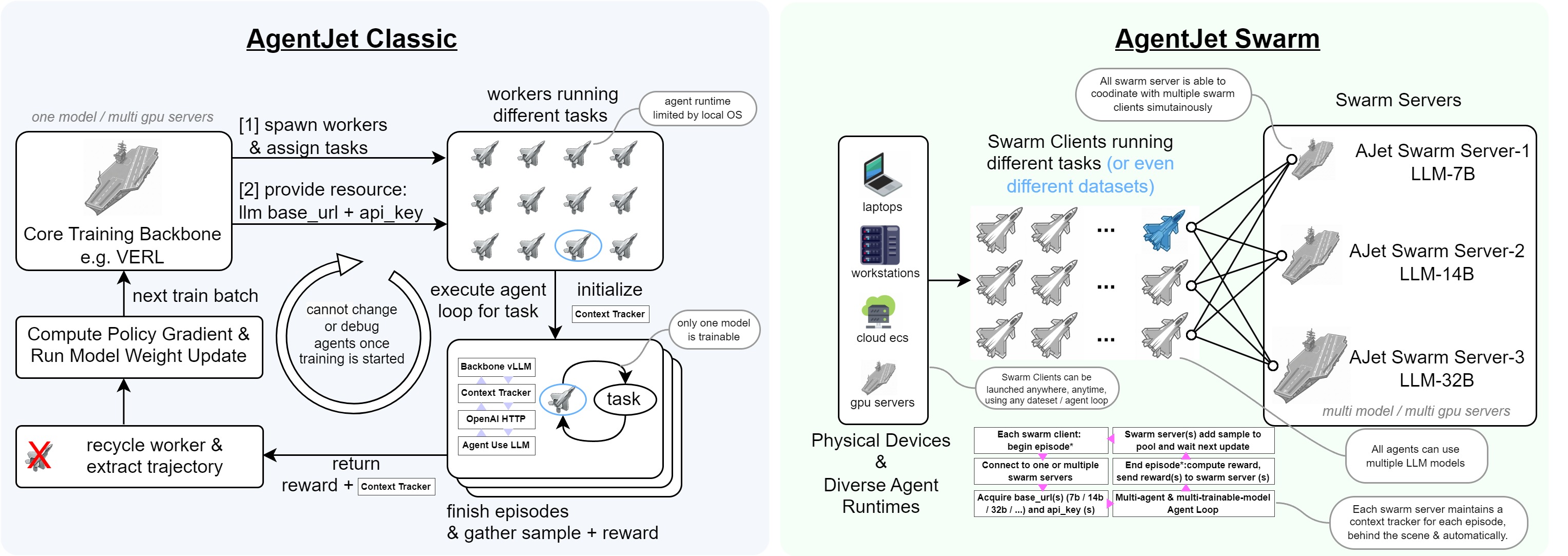
To more vividly demonstrate the difference between the two training modes, we can compare the training backend (like VERL) to an "aircraft carrier" with sufficient computing power but carrying only one model, and the RL inference sampling process to "fighter jets".
| Feature | Typical Mode | AgentJet Swarm Training Mode |
|---|---|---|
| Multi-Model Training | Does not support training multiple LLM models simultaneously. These "fighter jets" (sampling processes) are completely "welded" to the "aircraft carrier" (training backend) that created them, unable to collaborate across "aircraft carriers". No matter how many agents are trained, they can only share a "brain". | Supports training multiple LLM models simultaneously. Multiple "mother ships" (Swarm Servers) can be deployed, each "aircraft carrier" carrying different LLM models, and supports dynamic allocation and cross-"aircraft carrier" collaboration of "fighter jets" (Swarm Clients). |
| Runtime Environment Constraints | The "weight" of "fighter jet" runtime is constrained by the "aircraft carrier", requiring researchers to invest time and energy in engineering issues like dependency environment configuration, MCP tool modifications, and building proxy networks. | No constraints whatsoever. Workstations, servers, or even Macbooks will work. No restrictions on hardware, operating system, dependency environment, or even programming language - as long as it can send HTTP requests. |
| Dynamics and Scalability | When external environment changes occur (such as external API failure, IP rate limiting, disk issues) or agent code needs modification (such as reward coefficients, task difficulty coefficients, code bug fixes), the entire training process must be completely terminated and retried, losing all unsaved progress. | A flexibly scalable training system. Supports any "fighter jet" node dynamically joining or leaving training tasks at any time (even killing processes directly is fine), without causing training interruption or chaos. The system has high flexibility and fault tolerance. |
| Special Abilities | - | Researchers can designate any "fighter jet" in the swarm as a "super commander", responsible for directing the operation of "aircraft carriers" in the swarm. For example, after debugging on a small model, the "super commander" can command the "aircraft carrier" to immediately switch to a larger base model and execute formal training with more GPUs. |
Next, let's use a few simple cases to demonstrate the advantages of the AgentJet swarm mode.
Flexible Swarm Training Mode
Full Parameter Training of Agentic LLM Models on a Laptop
Yes, in AgentJet swarm mode, your laptop can perfectly become a Swarm Client. Imagine this scenario: your team has deployed a Swarm Server on a remote GPU cluster, mounting a Qwen-32B model. At this time, open your Laptop, write the Agent Loop you need to train, specify the dataset path, model path, and reward function, and debugging and training can begin.
Your laptop (or workstation, Alibaba Cloud ECS, etc., no GPU required) is only responsible for running the logic orchestration of the Agent workflow: reading datasets, calling the remote Swarm Server's inference interface (Base Url + Api Key) to get model output, executing tool calls, calculating rewards, and then sending the results back to the Swarm Server.
On the other hand, all the heavy lifting (model inference, gradient calculation, parameter update) is completed by the remote GPU cluster.

What does this mean? Agent developers and large model researchers no longer need to clearly distinguish between the boundaries of "inference" and "training", nor do they need to struggle to debug workflows in a dedicated training pipeline. You can write and modify Agent logic locally using your most familiar IDE. Without terminating the training, you can also achieve instant modification of agent code and reward parameters at any time. For example, when you need to modify the reward, just modify the code, kill the running old Swarm Client process and restart it. (The Swarm Server will automatically clean up the data debris left by the previous Swarm Client.)
Because AgentJet swarm mode realizes instant feedback of agent code and reward modifications in the training system, you can even let advanced programming assistance tools like Claude Code or Cursor take over the entire process of Agent Loop writing + debugging + training, writing http commands to remotely adjust Swarm Server training parameters.
Although essentially different, a comparison can be made with Tinker in the reinforcement learning field. AgentJet, which is fully open-source and open, is more controllable and flexible in this field.
| Feature | Tinker | AgentJet-Swarm |
|---|---|---|
| Open Source Nature | ❌ Closed Source | ✅ Open Source & Free |
| Task | Various LLM Training | Specialized in Agent RL Training |
| Architecture Mode | Managed Service + Single Point Client API | ✅ Both Server and Client are scalable on demand |
| Multi-Client Participation | ❌ Not Supported | ✅ Supported |
| Training Method | LoRA Fine-tuning only | ✅ Full LLM Model Training |
| Max Model Scale | Llama 70B, Qwen 235B | ✅ Depends on user GPU cluster config |
| Communication Protocol | Proprietary API | ✅ Proprietary API + OpenAI Compatible API |
| Inference Engine Backend | Built-in unknown inference service | ✅ vLLM/SGLang optional |
External Runtime Crash? Fix it and Continue, Don't Waste a Second
This is one of the most intuitive engineering benefits brought by the AgentJet swarm architecture. Training crashes caused by unstable external factors may have become a collective memory of many Agent reinforcement learning researchers. In traditional centralized training frameworks, Agent runtime and training loops are tightly coupled. Once an external dependency fails. For example, a browser MCP tool is IP banned by the target website, a code sandbox Docker container is killed due to OOM, or even just a third-party API Rate Limit is triggered, the entire training process has a probability of crashing. Then you have to reload from the last checkpoint, lose all unsaved rollout data, and pray for better luck next time.
AgentJet Swarm cures this problem from the architectural level. Since Swarm Client and Swarm Server are completely decoupled independent processes, the crash of a Client is just "one less data provider" for the Server. The Server will continue to wait for data from other Clients, or patiently wait for the faulty Client to recover.
Specifically:
- Client Crash: Rollout samples already collected by the Server will not be lost; they are safely stored in the Server's sample buffer. You just need to fix the problem (change IP, restart Docker, recharge API balance), and then restart the Client. It will automatically continue to submit new rollouts from the breakpoint.
- Partial Task Failure: Even if some tasks in a batch fail due to runtime failures, AgentJet will gracefully skip these failed samples and use the successfully completed samples to continue gradient updates, without wasting any effective computation.
For Agent training tasks that rely on complex external environments (web browsing, terminal operations, database interactions), this fault tolerance capability is not just icing on the cake, but a necessity.
Fixing Workflow BUG? Debugging Rewards? Get Traceback in 10 Seconds
AgentJet achieves true trinity of training, inference, and debugging. Under traditional frameworks, debugging a reward function for an Agent workflow is a frustrating thing. You modify a line of reward calculation logic, and then you need to: restart the entire training script -> wait for model loading (tens of seconds to minutes) -> wait for vLLM engine initialization -> wait for the first rollout to complete -> finally see the error message. The entire cycle may take 5-10 minutes, and you might have just made a mistake in indentation.
In swarm mode, this pain point is completely eliminated. Because the Swarm Client is a lightweight pure CPU process, it does not need to load any model weights, and the startup time is in seconds. Your debugging cycle becomes:
- Modify workflow code or reward function in IDE (VS Code, Cursor, ClaudeCode, etc.)
- Restart Swarm Client (about 2-3 seconds)
- Client immediately connects to the already running Swarm Server and starts executing new rollouts (no need to wait for model weights to reload)
- See results or traceback within seconds
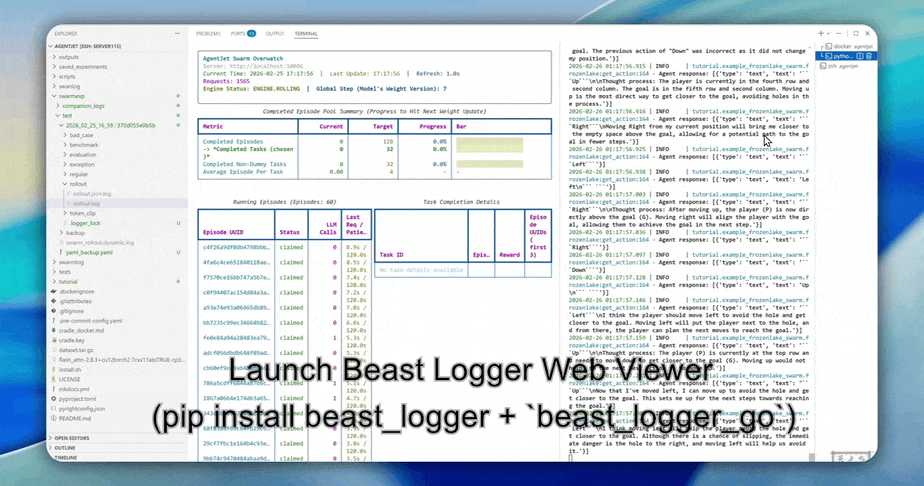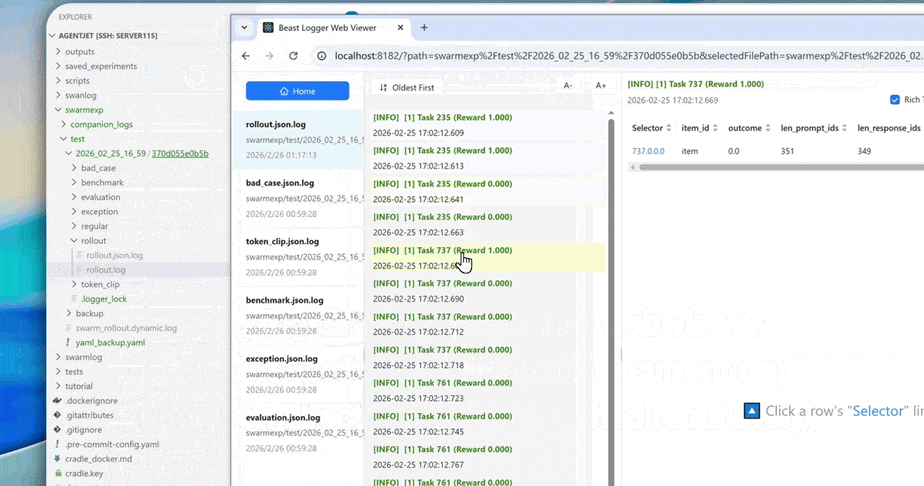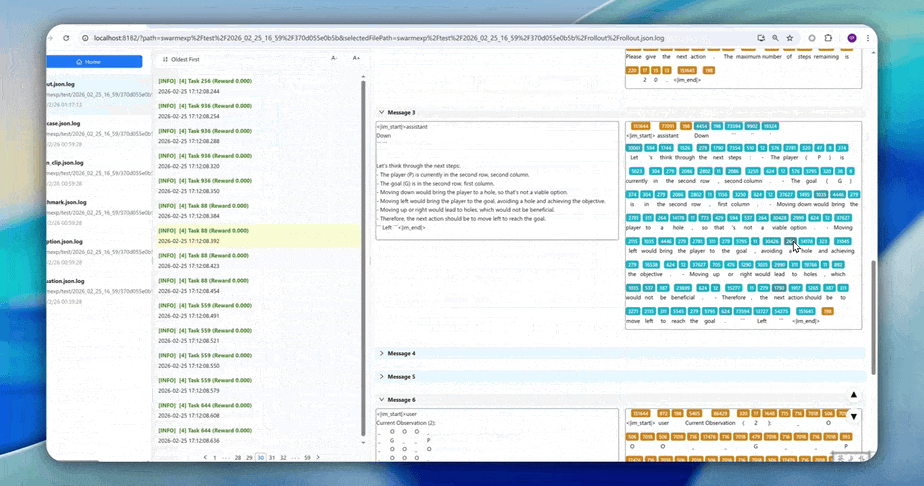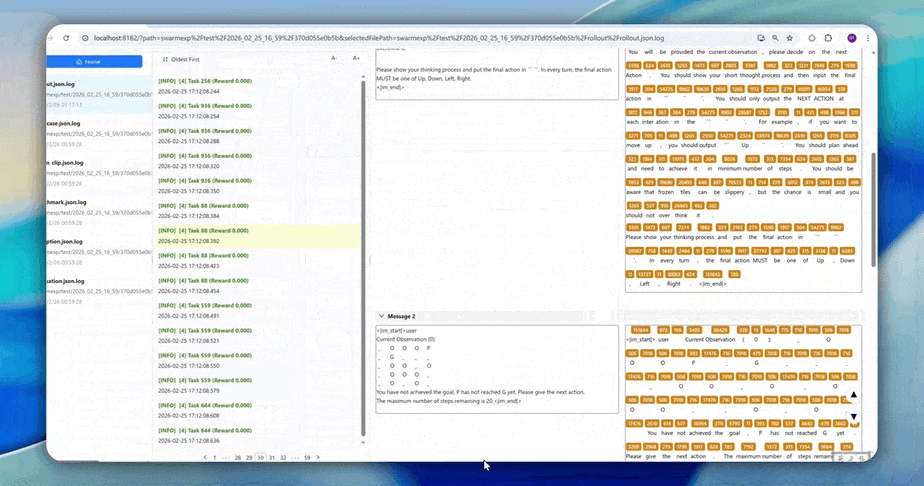
This means you can develop Agent training processes just like developing ordinary Python projects - set breakpoints, check variables, single-step execution. The entire Client side is ordinary Python code, without Ray or any other "black magic" of distributed training frameworks. AI programming assistants like Cursor and Claude Code can also directly participate in your Agent training development and benefit from the instant output feedback of the Agent to automatically fix Bugs.
Multi-Task Cocktail RL Training: Need to train Math + Code + Terminal tasks simultaneously, with completely different runtime dependencies for each task? Easy!
Multi-task mixed training is a key means to improve model generalization capabilities, but it is fraught with difficulties in practice. Math tasks require a symbolic calculation verifier, code tasks require a safe Docker sandbox, and terminal tasks require a complete Linux environment and file system - the dependencies, permission requirements, and security policies of these three runtimes are completely different. Stuffing them into the same training process is both troublesome and unsafe.
AgentJet swarm mode naturally solves this problem. You only need to deploy a Swarm Server to host the target model, and then start multiple Swarm Clients on different machines (or even different network environments), each Client responsible for a type of task. Next, you can use the "throttler" provided by AgentJet to adjust the ratio of different tasks; you can also flexibly customize the training logic and dynamically adjust the ratio during the training process. Each Client operates independently, is independently fault-tolerant, and does not interfere with each other.
This architecture also brings an additional benefit: Resource Isolation. Code sandbox needs Docker permissions? Configure it on Machine B, it won't affect other Clients. Browser MCP tools need special network proxies? Configure only on the corresponding Client machine. The security boundaries and resource requirements of different tasks are naturally isolated.
Single Node-Multi Model: Train multiple heterogeneous models simultaneously? No problem!
Multi-agent collaboration is one of the frontier directions of Agent research, but existing frameworks almost always assume that all Agents share the same underlying model. This assumption is uneconomical in many scenarios: an Agent responsible for high-level planning may need a 32B large model to ensure reasoning quality, while an Agent responsible for specific execution may be sufficient with a 7B small model.
AgentJet Swarm natively supports multi-Server multi-model training topology. You can start multiple Swarm Servers simultaneously on multiple GPU servers, each Server hosting models of different sizes, and then use a Swarm Client to orchestrate their collaboration:
In the workflow, the Client can route different inference requests to different Servers based on roles. The conversation history of the planning Agent is sent to the 32B model, and the conversation history of the execution Agent is sent to the 7B model. The two models collect their own rollout samples, calculate gradients independently, update parameters independently, and complete true non-shared parameter multi-agent reinforcement learning training (multiple heterogeneous LLM models undergoing RL training simultaneously).
This capability opens up many research directions that were previously difficult to realize:
- Heterogeneous Team Collaboration: Models of different ability levels form teams to each learn optimal strategies in competitive or cooperative environments.
- Cascaded Decision Optimization: Large models are responsible for coarse-grained decisions, small models execute fine-grained operations, jointly optimizing the entire decision chain end-to-end.
- ...
A Powerful Training Framework
Agnostic to Agent Framework, Supports OpenAI Protocol BaseUrl and ApiKey
AgentJet is not bound to any specific Agent framework. Whether you use LangChain, AutoGen, CrewAI, MetaGPT, or your own handwritten Agent logic based on raw HTTP requests, as long as your Agent calls LLM via OpenAI compatible API protocol (base_url + api_key), seamless access to AgentJet for training is possible.
For your Agent code, Swarm Server is no different from any other OpenAI compatible inference service. The only difference is that AgentJet silently records complete conversation context and token-level information for training in the background.
This means you can take existing, already debugged Agent workflows directly for RL training without rewriting any inference call logic. Even for some closed-source Agent black-box agents, theoretically, you only need to modify the base_url and api_key in the environment variables to access AgentJet for training.
Stable, Reproducible, Version-by-Version Performance Tracking, No Worries
For a training framework, "it runs" is just the minimum requirement. "Runs correctly" and "runs stably" are what researchers really care about. AgentJet has invested heavily in engineering quality to ensure that every training result is trustworthy.
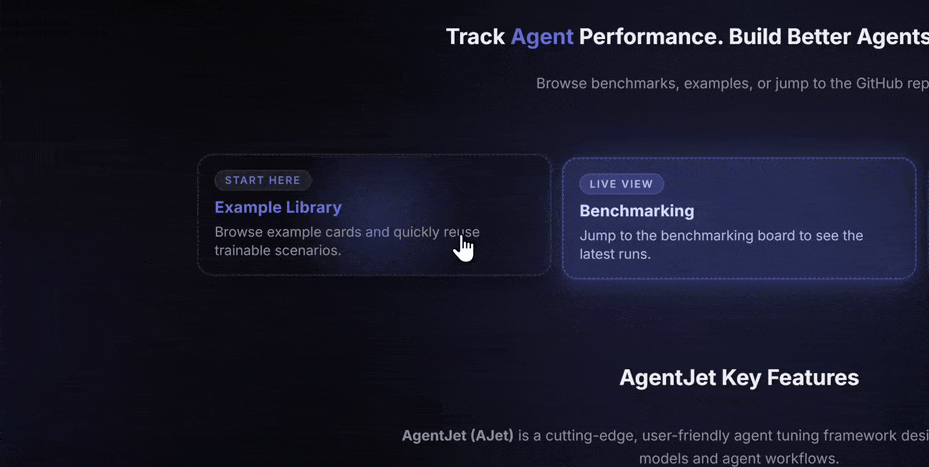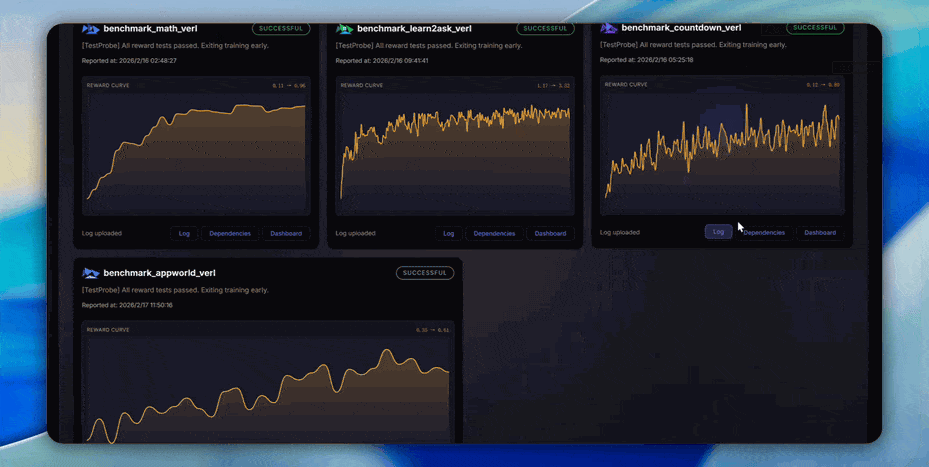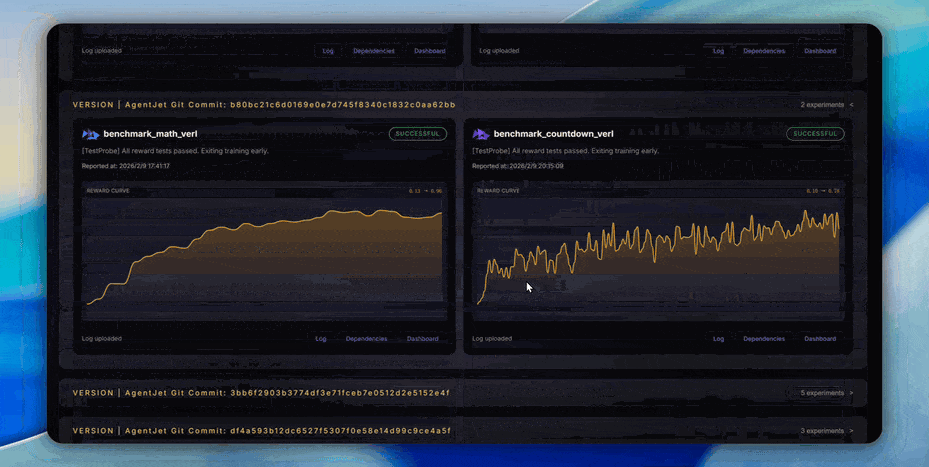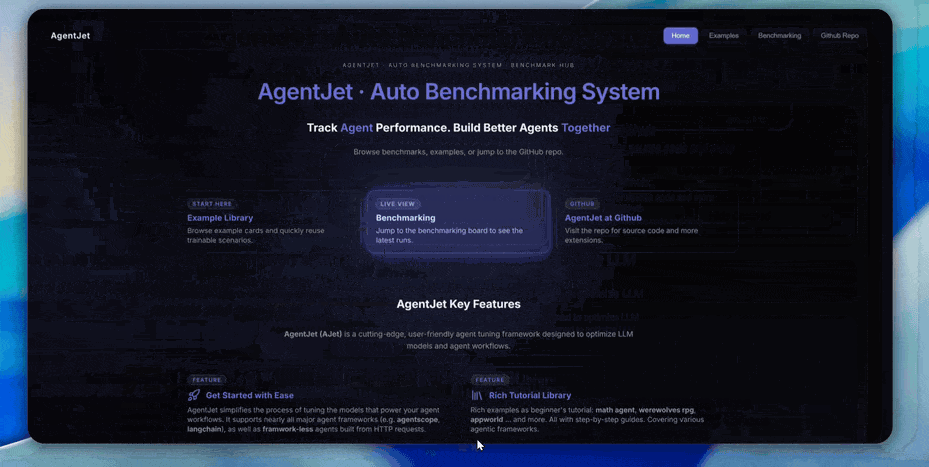
Version-by-Version Performance Tracking: We maintain a public Performance Tracking Dashboard, continuously recording AgentJet's training curves and final performance on multiple standard tasks (mathematical reasoning, code generation, tool use, etc.), across major Git versions, and across different training backends (VERL, etc.). With every code update, the test bot executes benchmarks, and any performance regression is immediately detected. This means:
- When upgrading AgentJet versions, you can clearly know how the new version performs on the tasks you care about.
- If an update introduces a hidden bug causing a decline in training effectiveness, we will capture it immediately.
- Researchers can confidently cite AgentJet's experimental results because they are reproducible.
Token Consistency Automatic Alert & Repair: In Agent training, a hidden issue is token drift: the same text may be encoded into different token sequences during inference and training phases, leading to incorrect logprob calculations and thus polluting the accuracy of policy gradient calculations. AgentJet has built-in automatic re-tokenization drift detection and repair mechanisms, enabled by default. It automatically verifies and corrects token sequences before each rollout sample enters the training pipeline, eliminating such problems.
High-Resolution Logs: When in-depth diagnosis of training behavior is needed, AgentJet provides token-level rollout logs, recording the ID, loss mask status, and logprob value of each token. This information is crucial for understanding model learning dynamics, troubleshooting reward signal anomalies, and verifying workflow logic correctness.
Core Strengths and Rich Tutorial Library
As an Agent training framework, simply implementing a distributed architecture is far from enough. How to provide a stable, instant-start, trustworthy training environment is also a topic we need to study. Therefore, AgentJet possesses and open-sources these core hard capabilities:
- Rich Tutorial Library: Provides interesting examples as tutorial materials. Explore our rich example library to quickly start your journey:
- Timeline Automatic Merging Capability: Supports multi-agent workflows and adopts context merging technology to accelerate training by 1.5x to 10x in multi-turn (or multi-agent) conversation scenarios. (Similar to the "tree structure" processing capability mentioned in the minimax forge technical report.)
- Reliable and Reproducible: We continuously track the framework's performance on multiple different tasks + major Git versions + different training backends (data continuously aggregated), what you see is what you get, hidden bugs are discovered in seconds.
- Token Consistency Automatic Alert & Repair: By default, AgentJet automatically performs Re-tokenization drift repair based on the Token ID returned by the vLLM engine.
- Multi-Training Backend Support: Supports multiple training backends including VERL, and is working on supporting other training backends like TRL.
Efficient Training/Inference GPU CoLocate Based on VERL
The flexibility of the AgentJet swarm architecture does not come at the expense of GPU utilization efficiency & generating large GPU bubbles. Inside the Swarm Server, AgentJet still adopts the battle-tested VERL training/inference CoLocate architecture: this means that inference (rollout generation) and training (gradient update) share the same group of GPUs, avoiding waste of GPU memory.
For researchers familiar with VERL, almost all algorithm implementations implemented by VERL can be applied to AgentJet losslessly. AgentJet adds a swarm communication layer and timeline merging optimization on this basis, but the core training logic remains consistent. Migration costs are low, and performance is guaranteed.
Conclusion and Outlook
The core philosophy of the AgentJet swarm training framework can be summarized in one sentence: Let the flexibility of Agent training match the complexity of the Agent itself.
When Agent workflows become increasingly complex, rely on more external tools, and involve more heterogeneous models, the training framework should not become a bottleneck. By completely decoupling training inference (Server) from Agent runtime (Client), AgentJet achieves:
- Developer Friendly: Debug Agent workflows on a laptop with IDE, connect to remote swarm for instant training.
- Engineering Robustness: External runtime failures do not affect training progress, seamlessly resume after repair.
- Algorithm Flexibility: Multi-task mixed training, heterogeneous multi-model collaborative training, dynamic data ratio adjustment, everything is configurable.
- Reliable Performance: Inherits VERL's efficient CoLocate architecture, supplemented by timeline merging acceleration techniques, and version-by-version performance tracking capabilities to ensure trustworthy results.
We believe that when the training framework is no longer a limiting factor, researchers and engineers can devote more energy to truly important things - designing better Agent architectures, exploring more effective reward signals, and trying bolder multi-agent collaboration strategies.
AgentJet is fully open-sourced on GitHub. Researchers and developers in the community are welcome to try, provide feedback, and contribute. Let's push LLM Agent training into the swarm era together.
Project Address: https://github.com/modelscope/AgentJet
Performance Dashboard: https://benchmark.agentjet.top/
Official Documentation: https://modelscope.github.io/AgentJet/