异步 RFT#
本示例展示了如何使用 Qwen2.5-1.5B-Instruct 模型和 GSM8K 数据集以完全异步模式运行 GRPO 算法。
Trinity-RFT 支持通过在独立进程中运行 trainer 和 explorer 来实现异步 RFT。
我们提供了两个主要配置文件:explorer.yaml 和 trainer.yaml。
两者之间的主要区别是:在 explorer.yaml 中将 mode 设置为 explore,而在 trainer.yaml 中将 mode 设置为 train。
Explorer 与 Trainer 的模型权重每处理 sync_interval * batch_size 个任务后同步一次。
假设我们有一个包含 8 块 GPU 的节点,我们将其中 4 块分配给 trainer,另外 4 块分配给 explorer 。explorer.yaml 中的关键配置如下:
# explorer.yaml
project: <project_name>
name: <experiment_name>
mode: explore
checkpoint_root_dir: ${oc.env:TRINITY_CHECKPOINT_ROOT_DIR,./checkpoints}
algorithm:
algorithm_type: grpo
repeat_times: 8
model:
model_path: ${oc.env:TRINITY_MODEL_PATH,Qwen/Qwen2.5-1.5B-Instruct}
max_response_tokens: 1024
max_model_len: 2048
cluster:
node_num: 1
gpu_per_node: 4
buffer:
total_epochs: 1
batch_size: 64
explorer_input:
taskset:
name: gsm8k
storage_type: file
path: ${oc.env:TRINITY_TASKSET_PATH,openai/gsm8k}
subset_name: 'main'
split: train
format:
prompt_key: 'question'
response_key: 'answer'
rollout_args:
temperature: 1.0
default_workflow_type: 'math_workflow'
trainer_input:
experience_buffer:
name: gsm8k_buffer
storage_type: queue
path: 'sqlite:///gsm8k.db'
explorer:
runner_per_model: 16
rollout_model:
engine_num: 4
synchronizer:
sync_method: 'checkpoint'
sync_interval: 10
trainer.yaml 中的关键配置如下:
# trainer.yaml
project: <project_name>
name: <experiment_name>
mode: train
checkpoint_root_dir: ${oc.env:TRINITY_CHECKPOINT_ROOT_DIR,./checkpoints}
algorithm:
algorithm_type: grpo
repeat_times: 8
optimizer:
lr: 1e-6
model:
model_path: ${oc.env:TRINITY_MODEL_PATH,Qwen/Qwen2.5-1.5B-Instruct}
max_response_tokens: 1024
max_model_len: 2048
cluster:
node_num: 1
gpu_per_node: 4
buffer:
total_epochs: 1
train_batch_size: 512
explorer_input:
taskset:
name: gsm8k
storage_type: file
path: ${oc.env:TRINITY_TASKSET_PATH,openai/gsm8k}
subset_name: 'main'
format:
prompt_key: 'question'
response_key: 'answer'
rollout_args:
temperature: 1.0
default_workflow_type: 'math_workflow'
trainer_input:
experience_buffer:
name: gsm8k_buffer
storage_type: queue
path: 'sqlite:///gsm8k.db'
synchronizer:
sync_method: 'checkpoint'
sync_interval: 10
trainer:
grad_clip: 1.0
use_dynamic_bsz: true
max_token_len_per_gpu: 16384
ulysses_sequence_parallel_size: 1
你可以使用以下命令运行此示例:
bash examples/async_gsm8k/run.sh
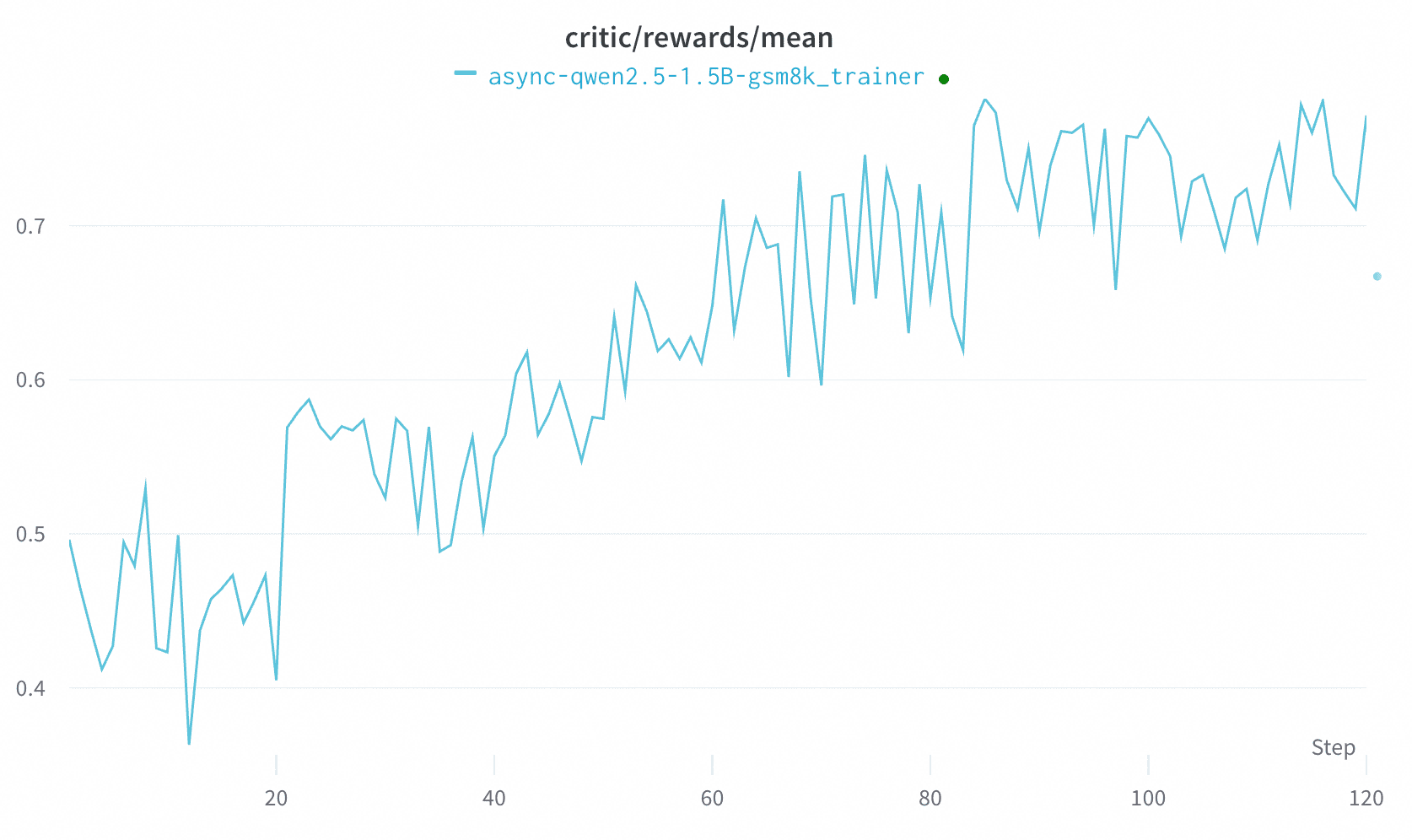
下图展示了 GRPO 在异步模式下的学习曲线:
此结果仅应视为基线,因为 GRPO 本质上是一种 on-policy 算法。 我们正在持续研究其他在异步模式下适用的强化学习算法(例如 OPMD)。
Trinity-RFT 还支持在异步模式下的动态扩展。延续之前的例子,如果在训练过程中有另一台带有 8 块 GPU 的机器加入 Ray 集群,你可以使用以下配置文件 explorer_new.yaml 启动一个新的 explorer 。
# explorer_new.yaml
project: <project_name>
name: <experiment_name>
mode: explore
checkpoint_root_dir: ${oc.env:TRINITY_CHECKPOINT_ROOT_DIR,./checkpoints}
algorithm:
algorithm_type: grpo
repeat_times: 8
model:
model_path: ${oc.env:TRINITY_MODEL_PATH,Qwen/Qwen2.5-1.5B-Instruct}
max_response_tokens: 1024
max_model_len: 2048
cluster: # important
node_num: 1
gpu_per_node: 8
explorer:
name: 'explorer_new' # important
runner_per_model: 8
rollout_model:
engine_num: 8
buffer:
total_epochs: 1
batch_size: 64
explorer_input:
taskset: # important
name: gsm8k
storage_type: file
path: ${oc.env:TRINITY_TASKSET_PATH,openai/gsm8k}
subset_name: 'main'
format:
prompt_key: 'question'
response_key: 'answer'
rollout_args:
temperature: 1.0
default_workflow_type: 'math_workflow'
trainer_input:
experience_buffer:
name: gsm8k_buffer
storage_type: queue
path: 'sqlite:///gsm8k.db'
synchronizer:
sync_method: 'checkpoint'
sync_interval: 10
# other configs are the same as explorer.yaml
explorer_new.yaml 与 explorer.yaml 的差异包括:
cluster.node_num/gpu_per_node:指定新加入的 explorer 所在集群的配置。explorer.name:后启动的 explorer 需要一个不同于默认名称 "explorer" 的名称。explorer.rollout_model.engine_num/tensor_parallel_size:定义引擎数量和张量并行大小,以最优地利用 GPU 资源。buffer.explorer_input.taskset:为新的 explorer 提供另一个任务数据集作为输入。
其余所有参数均与 explorer.yaml 中保持一致。