Welcome to Trinity-RFT’s documentation!#
💡 What is Trinity-RFT?#
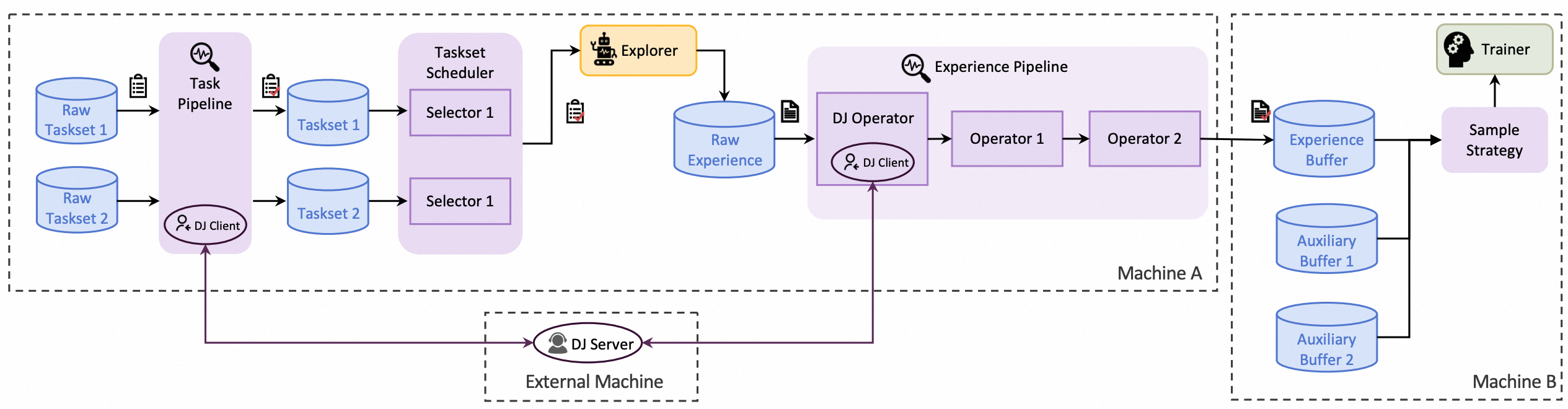
Trinity-RFT is a general-purpose, flexible and user-friendly framework for LLM reinforcement fine-tuning (RFT). It decouples RFT into three components that work in coordination:
Explorer generates experience data via agent-environment interaction;
Trainer updates model weights by minimizing losses on the data;
Buffer pipelines data processing throughout the RFT lifecycle.
Trinity-RFT provides functionalities for users with different backgrounds and objectives:
🤖 Agent application developers: Train LLM-powered agents and improve their capabilities in specific domains [tutorial]
🧠 Reinforcement learning researchers: Design, implement and validate new RL algorithms using compact, plug-and-play modules that allow non-invasive customization [tutorial]
📊 Data engineers: Create RFT datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios [tutorial]
🔨 Tutorials and Guidelines#
🌟 Key Features#
Flexible RFT Modes:
Supports synchronous/asynchronous, on-policy/off-policy, and online/offline RL.
Rollout and training can run separately and scale independently across devices.
Boost sample and time efficiency by experience replay.

Agentic RL Support:
Supports both concatenated and general multi-step agentic workflows.
Able to directly train agent applications developed using agent frameworks like AgentScope.

Full-Lifecycle Data Pipelines:
Enables pipeline processing of rollout tasks and experience samples.
Active data management (prioritization, cleaning, augmentation, etc.) throughout the RFT lifecycle.
Native support for multi-task joint learning and online task curriculum construction.
User-Friendly Design:
Plug-and-play modules and decoupled architecture, facilitating easy adoption and development.
Rich graphical user interfaces enable low-code usage.

🔧 Supported Algorithms#
We list some algorithms supported by Trinity-RFT in the following table. For more details, the concrete configurations are shown in the Algorithm module. You can also set up new algorithms by customizing different components, see tutorial.
Algorithm |
Doc / Example |
Source Code |
Key Configurations |
|---|---|---|---|
PPO [Paper] |
[Doc] [Countdown Example] |
[Code] |
|
GRPO [Paper] |
[Doc] [GSM8K Example] |
[Code] |
|
CHORD 💡 [Paper] |
[Doc] [ToolACE Example] |
[Code] |
|
REC Series 💡 [Paper] |
[Code] |
|
|
RLOO [Paper] |
- |
[Code] |
|
REINFORCE++ [Paper] |
- |
[Code] |
|
GSPO [Paper] |
- |
[Code] |
|
TOPR [Paper] |
[Code] |
|
|
sPPO [Paper] |
[Code] |
|
|
AsymRE [Paper] |
[Code] |
|
|
CISPO [Paper] |
- |
[Code] |
|
SAPO [Paper] |
- |
[Code] |
|
[Code] |
|
Acknowledgements#
This project is built upon many excellent open-source projects, including:
verl and PyTorch’s FSDP for LLM training;
vLLM for LLM inference;
Data-Juicer for data processing pipelines;
AgentScope for agentic workflow;
Ray for distributed systems;
we have also drawn inspirations from RL frameworks like OpenRLHF, TRL and ChatLearn;
……
Citation#
@misc{trinity-rft,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
year={2025},
eprint={2505.17826},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.17826},
}