ReAct Agent Training#
This section demonstrates how to train a ReAct Agent using Trinity-RFT. We use AgentScope as an example and leverage its built-in ReAct agent to solve GSM8K math problems. Developers can refer to this example to adapt Trinity-RFT’s training to their own agent projects.
Key Features#
Before diving into the example, let’s review several important features of Trinity-RFT for Agentic-RL training.
Compatible with Various Agent Frameworks#
There are many agent development frameworks, each with different model wrapping and invocation methods. To maximize compatibility, Trinity-RFT wraps the openai.OpenAI and openai.AsyncOpenAI interfaces. As long as your agent framework supports calling models via the OpenAI interface, you can train agents using Trinity-RFT’s OpenAI or AsyncOpenAI instances. You can also implement your own agent directly using Trinity-RFT’s OpenAI interface without any framework.
No Need to Modify Agent Code#
Training agents requires collecting dialogue history and other relevant information (such as token_id, logprobs) during agent execution, which often requires modifying source code of the agent application. Trinity-RFT avoids this by wrapping the openai.OpenAI or openai.AsyncOpenAI instances, automatically collecting all necessary training information during model calls, so that you don’t need to change your agent code.
Supports Multi-Turn Interaction#
Agent tasks often involve multiple steps of reasoning and actioning. Trinity-RFT natively supports RL training for tasks with multi-turn interactions, without limiting the number of turns (just ensure each LLM call’s sequence length does not exceed the model’s maximum). This allows you to design dynamic-length interactions based on task complexity. Trinity-RFT’s dynamic synchronization mechanism enables training to start as soon as enough samples are collected, improving efficiency.
Implementation#
We will walk through how to train a ReAct agent implemented with AgentScope using Trinity-RFT.
1. Change the OpenAI client of your Agent#
The AgentScopeReActAgent wraps AgentScope’s ReAct agent and injects Trinity-RFT’s openai.AsyncOpenAI instance during initialization. The subsequent execution is handled by the AgentScope agent itself, with no code modification required.
# A simplified version of trinity.common.workflows.agentscope.react.react_agent.AgentScopeReActAgent
class AgentScopeReActAgent:
def __init__(
self,
openai_client: openai.AsyncOpenAI, # provided by Trinity-RFT
# some other params
):
"""Initialize the AgentScope ReAct agent with specified tools and model.
Args:
openai_client (openai.AsyncOpenAI): An instance of AsyncOpenAI client.
"""
self.agent_model = OpenAIChatModel(
api_key="EMPTY",
model_name=model_name,
generate_kwargs=generate_kwargs,
stream=False,
)
# patch the OpenAIChatModel to use the openai_client provided by Trinity-RFT
self.agent_model.client = openai_client
self.agent = ReActAgent(
name="react_agent",
model=self.agent_model,
)
async def reply(self, query):
"""Generate a response based on the query."""
# no need to modify your agent logic
return await self.agent.reply(
Msg("user", query, role="user")
)
Note
We encapsulate AgentScope’s ReAct agent in a new class here to clearly demonstrate the process of replacing the OpenAI client. In practice, you can directly modify the OpenAI client of your existing agent without creating a new class.
2. Implement the Training Workflow#
The AgentScopeReActWorkflow demonstrates the agent training workflow. Its core run_async method includes three steps:
Call the agent to complete the task and return the result.
Evaluate the result and calculate the reward.
Collect trainable data generated during task execution and combine it with the reward to create training samples (
Experience).
# A simplified version of trinity.common.workflows.agentscope.react.react_workflow.AgentScopeReActWorkflow
class AgentScopeReActWorkflow(Workflow):
def __init__(
self,
*,
task: Task,
model: ModelWrapper,
auxiliary_models: Optional[List[ModelWrapper]] = None,
):
# initialize the agent
self.agent = AgentScopeReActAgent(
openai_client=model.get_openai_async_client(),
# some other params
)
# get query from the task
self.query = task.raw_task.get(task.format_args.prompt_key) # type: ignore [index]
async def run_async(self):
"""Run the workflow asynchronously."""
# Step 1: call the ReAct agent to solve the task
response = await self.agent.reply(self.query)
# Step 2: calculate the reward based on the response
reward = await self.calculate_reward(response)
# Step 3: construct experiences from the interaction history and return them
return self.construct_experiences(reward)
async def calculate_reward(self, response) -> float:
"""Calculate the reward based on the response."""
# your reward logic
def construct_experiences(self, reward: float) -> List[Experience]:
"""Construct experiences from the agent's interaction history.
Returns:
List: A list of Experience objects.
"""
# Extract all interaction history generated by this task
exps = self.model.extract_experience_from_history()
# update the reward for each experience
for exp in exps:
exp.reward = reward
return exps
3. Training Configuration#
Trinity-RFT uses configuration files to control the training workflow. Below are key configuration parameters for this example.
Inference Model Configuration#
The explorer.rollout_model section configures the model used by the agent application. Key parameters include:
explorer:
rollout_model:
# ...
enable_openai_client: true # Enable OpenAI Client
enable_history: true # Enable automatic call history recording
enable_auto_tool_choice: true # Allow model to generate `tool_calls`
tool_call_parser: hermes # Specify parser for tool call outputs
reasoning_parser: deepseek_r1 # Helps parse model reasoning process
enable_thinking: true # Enable thinking (mainly for Qwen3 series models)
Multi-Step Training Algorithm#
The algorithm section configures the training algorithm for the agent application. Key parameters include:
algorithm:
algorithm_type: multi_step_grpo # Specify multi-step GRPO training algorithm
Dynamic Synchronization Configuration#
Since agent applications may have variable interaction rounds and sample counts, we enable Trinity-RFT’s dynamic synchronization to improve efficiency. Relevant configuration:
synchronizer:
sync_style: dynamic_by_explorer # Trainer starts training immediately when enough data is generated, rather than padding to a fixed size, improving efficiency
sync_interval: 2 # Check for model parameter updates after every two batches
Running the Example#
Install dependencies: Follow the Installation Guide to install Trinity-RFT and AgentScope v1.0 or above.
pip install agentscope>=1.0.4
Download model and dataset:
huggingface-cli download Qwen/Qwen3-8B
huggingface-cli download openai/gsm8k --repo-type dataset
Start the training task:
# Navigate to the Trinity-RFT root directory
cd /path/to/Trinity-RFT
# Run the training for GSM8k dataset:
trinity run --config examples/agentscope_react/gsm8k.yaml
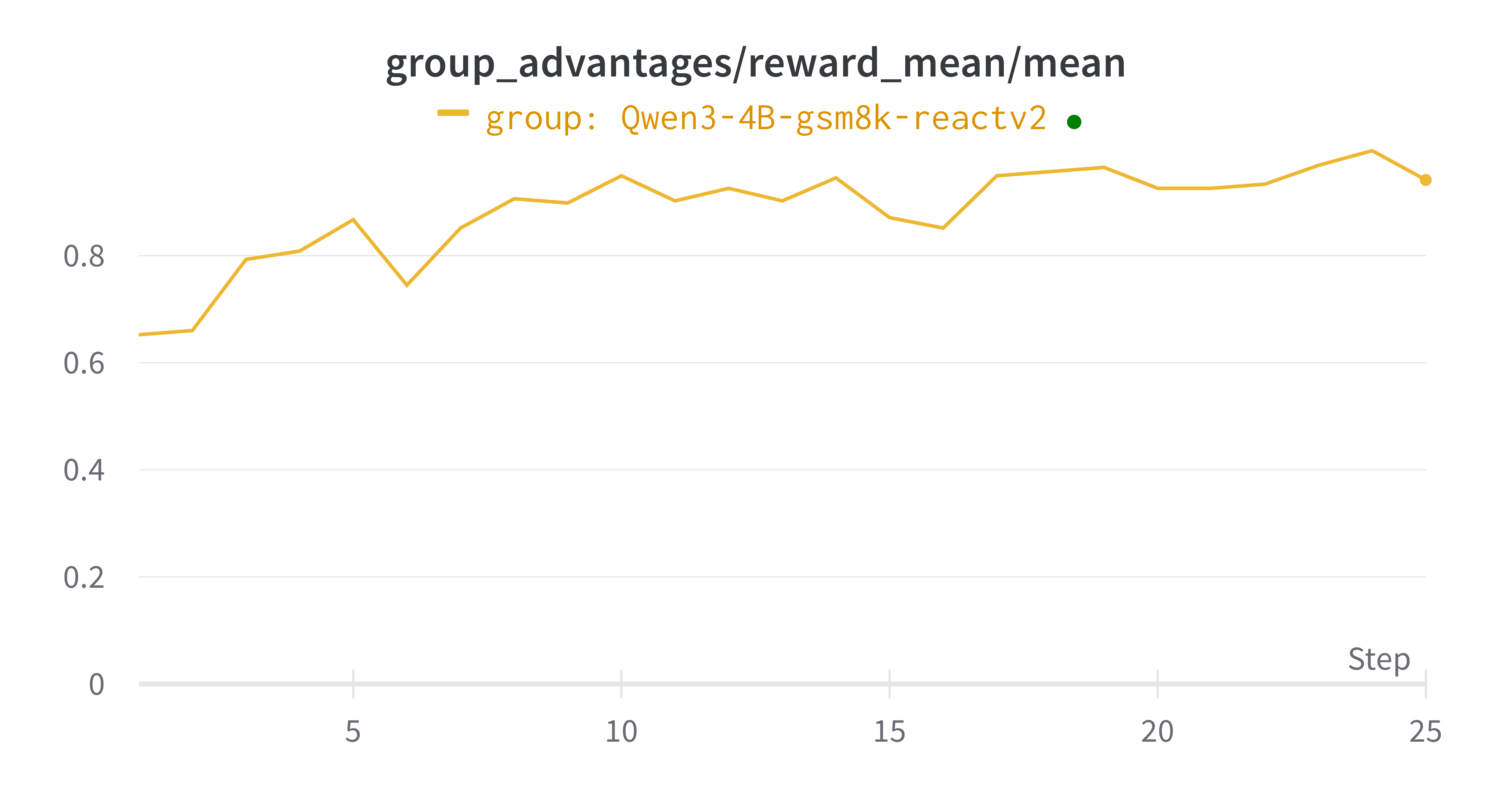
Results#
Reward curve: