Off-Policy RFT#
Let’s continue with the previous GSM8k example, but switch from on-policy to off-policy RFT.
In this example, we consider an off-policy RL algorithm termed as OPMD (Online Policy Mirror Descent) in Trinity-RFT.
The algorithm design and analysis can be found in Section 2.2 of our paper.
The config file is opmd_gsm8k.yaml.
To try out the OPMD algorithm:
trinity run --config examples/opmd_gsm8k/opmd_gsm8k.yaml
Note that in this config file, sync_interval is set to 10, i.e., the model weights of explorer and trainer are synchronized only once every 10 training steps, which leads to a challenging off-policy scenario (potentially with abrupt distribution shift during the RFT process).
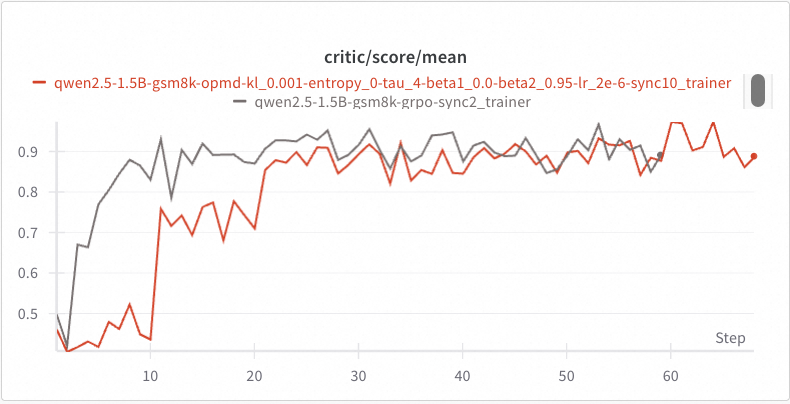
In the plot below, the red curve shows the score achieved by the explorer during OPMD training.
Since the explorer’s model weights remain unchanged for the first 10 steps, its score remains flat.
Then, after the model weights of explorer and trainer are synchronized at the end of step 10, we see an abrupt increase in score at step 11, which indicates effective off-policy learning in the first 10 steps.
A similar performance boost is shown at step 21, which leads to a converged score matching what is achieved by GRPO in a mostly on-policy case (with sync_interval=2).
If you’re interested in more findings about off-policy RL algorithms, please refer to our paper.